机器学习之分类:精确率和召回率
精确率
精确率指标尝试回答以下问题:
在被识别为正类别的样本中,确实为正类别的比例是多少?
精确率的定义如下:
Precision = \dfrac{TP}{TP + FP}
注意:如果模型的预测结果中没有假正例,则模型的精确率为 1.0 。
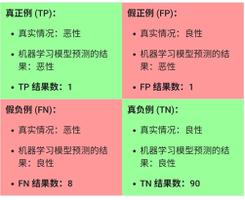
让我们来计算一下上一部分中用于分析肿瘤的机器学习模型的精确率:
精确率 = \dfrac{TP}{TP + FP} = \dfrac{1}{1 + 1} = 0.5
该模型的精确率为 0.5,也就是说,该模型在预测恶性肿瘤方面的正确率是 50%。
召回率
召回率尝试回答以下问题:
在所有正类别样本中,被正确识别为正类别的比例是多少?
从数学角度讲,召回率的定义如下:
召回率 = \dfrac{TP}{TP + FN}
注意:如果模型的预测结果中没有假负例,则模型的召回率为 1.0
让我们来计算一下肿瘤分类器的召回率:
召回率 = \dfrac{TP}{TP + FN} = \dfrac{1}{1 + 8} = 0.11
该模型的召回率是 0.11,也就是说,该模型能够正确识别出所有恶性肿瘤的百分比是 11%
精确率和召回率:一场拔河比赛
要全面评估模型的有效性,必须同时检查精确率和召回率。遗憾的是,精确率和召回率往往是此消彼长的情况。也就是说,提高精确率通常会降低召回率值,反之亦然。
请观察下图来了解这一概念,该图显示了电子邮件分类模型做出的 30 项预测。分类阈值右侧的被归类为“垃圾邮件”,左侧的则被归类为“非垃圾邮件”。
图 1.将电子邮件归类为垃圾邮件或非垃圾邮件
我们根据图 1 所示的结果来计算精确率和召回率值:
精确率指的是被标记为垃圾邮件的电子邮件中正确分类的电子邮件所占的百分比,即图 1 中阈值线右侧的绿点所占的百分比:
Precision = \dfrac{TP}{TP + FP} = \dfrac{8}{8 + 2} = 0.8
召回率指的是实际垃圾邮件中正确分类的电子邮件所占的百分比,即图 1 中阈值线右侧的绿点所占的百分比:
Recall = \dfrac{TP}{TP + FN} = \dfrac{8}{8 +3} = 0.73
图 2 显示提高分类阈值产生的效果
图 2.提高分类阈值
假正例数量会减少,但假负例数量会相应地增加。结果,精确率有所提高,而召回率则有所降低:
Precision = \dfrac{TP}{TP + FP} = \dfrac{7}{7 + 1} = 0.88
Recall = \dfrac{TP}{TP + FN}=\dfrac{7}{7 + 4} = 0.64
相反,图 3 显示了降低分类阈值(从图 1 中的初始位置开始)产生的效果。
图 3.降低分类阈值。
假正例数量会增加,而假负例数量会减少。结果这一次,精确率有所下降,而召回率有所提高:
Precision = \dfrac{TP}{TP + FP} = \dfrac{9}{9 + 3} = 0.75
Recall = \dfrac{TP}{TP + FN} = \dfrac{9}{9 + 2} = 0.82
我们已经根据精确率和召回率指标制定了各种指标。
以上是 机器学习之分类:精确率和召回率 的全部内容, 来源链接: utcz.com/p/216978.html