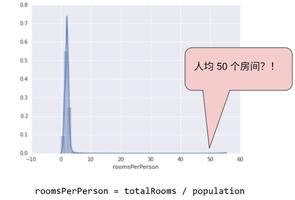
机器学习之数据集的划分
通常将数据集划分为三个子集 ( 如下图所示 ) ,您可以大幅降低过拟合的发生几率:
图 2.将单个数据集划分为三个子集
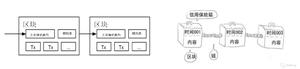
使用验证集评估训练集的效果.然后, 在模型“通过”验证集之后,使用测试集再次检查评估结果. 下图展示了这一新工作流程: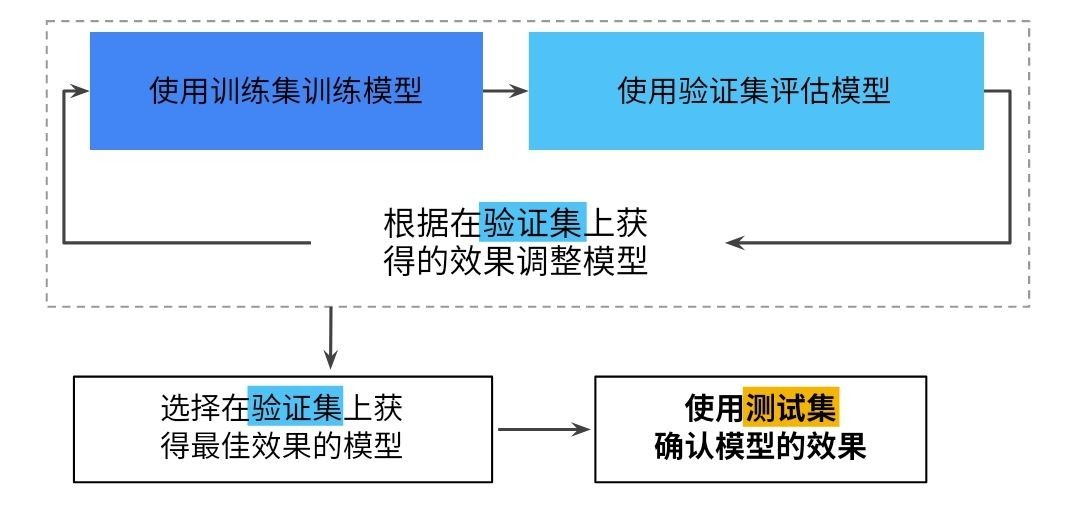
图 3.更好的工作流程
在这一经过改进的工作流程中:
1.选择在验证集上获得最佳效果的模型.
2.使用测试集再次核查该模型.
该工作流程之所以更好, 原因在于它报漏给测试集的信息更少.
注意:
不断使用测试集和验证集会使其逐渐失去效果.也就是说, 您使用相同的数据来决定超参数设置或其他模型改进的次数越多, 您对于这些结果能够真正的泛化到未见过的新数据的信心就越低.请注意, 验证集的失效速度通常比测试集缓慢.
如果可能的话, 建议您收集更多的数据来“刷新”测试集和验证集.重新开始是一种很好的重置方式.
以上是 机器学习之数据集的划分 的全部内容, 来源链接: utcz.com/p/216987.html