机器学习之简化正则化:Lambda
模型开发者通过以下方式来调整正则化的整体的影响:用正则化项的值乘以名为lambda ( 又称为 正则化率 ) 的标量。也就是说, 模型开发者会执行以下运算:
minimize (Loss(Data|Model) + \lambda complexity(Model))
执行 L_2正则化对模型具有以下影响
- 是权重值接近于 0 (但并非正好为 0 )
- 使权重的平均值接近于0,且成正态( 钟形曲线或高斯曲线 )分布。
增加 lambda 值将增强正则化效果。例如, lambda 值较高的权重直方图可能会如图 2 所示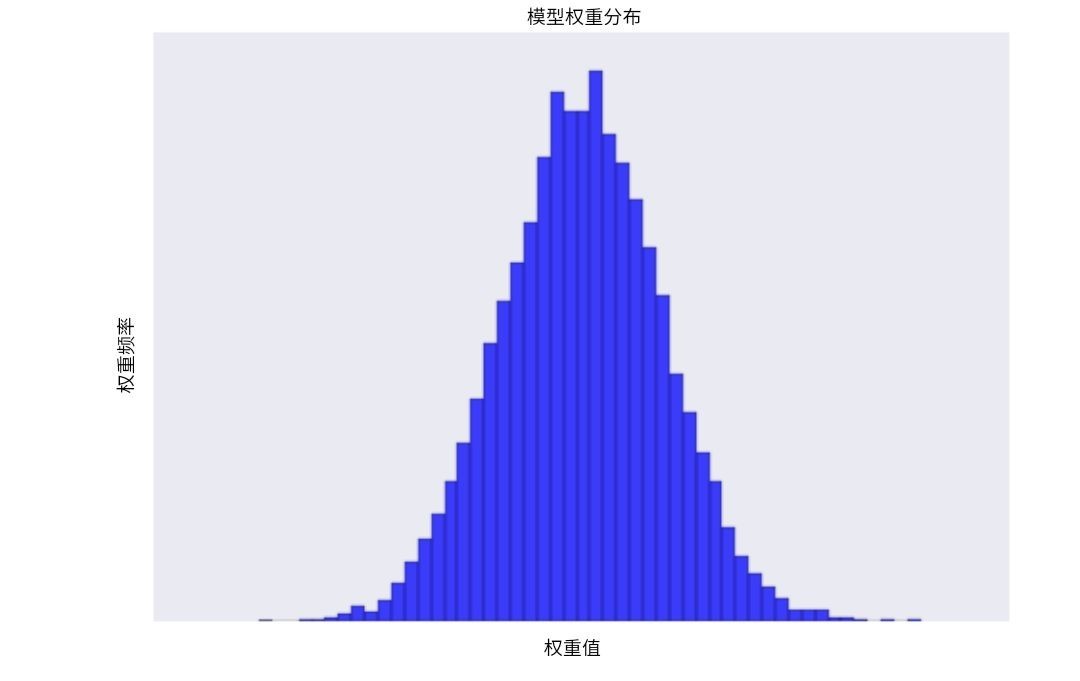
图 2.权重直方图
降低 lambda 的值往往会得出比较平缓的直方图, 如图 3 所示
图 3.较低的 lambda 值得出的权重直方图。
在选择 lambda 值时, 目标是在简单化和训练数据拟合之间达到适当的平衡: - 如果您的 lambda 值过高, 则模型会非常简单, 但是您将面临数据欠拟合的风险。您的模型将无法从训练数据中获得足够的信息来做出有用的预测
- 如果您的 lambda 值过低, 则模型比较复杂, 并且您将面临数据过拟合的风险。您的模型将因获得过多训练数据特点方面的信息而无法泛化到新数据。
注意:将 lambda 设为 0 可彻底取消正则化。在这种情况下, 训练的唯一目的将是最小化损失, 而这样做将会使过拟合的风险达到最高。
理想的 lambda 值生成的模型可以很好地泛化到以前未见过的数据。遗憾的是,理想的 lambda 值取决于数据,因此您需要手动或自动进行一些调整。
以上是 机器学习之简化正则化:Lambda 的全部内容, 来源链接: utcz.com/p/216979.html