爬虫 页面不存在_百度搜索
1.学写爬虫,遇到一个问题,加了values={"wd":"test","ie":"utf-8"}就报错了,也就是我向百度页面搜索里面输入test就报错,百度了一圈没找到答案,请教一下各位大神如何处理,如果可以的话能否说明这是为什么,以及怎么处理类似的情况,谢谢!2.代码如下(版本2.7):(randHeader用来生成随机的Header,savef...
2024-01-10
爬虫百度百科要求验证,请问该如何处理?
爬虫要求验证,请问该如何处理?请赐教,不胜感激。import urllib.requestimport urllib.parsefrom lxml import etreeimport re url = 'https://bke.bd.com/item/' + urllib.parse.quote('周杰伦')headers = { 'User-Agent': 'Mozilla...
2024-03-07
大规模异步新闻抓取:简单的百度新闻爬虫
要抓取新闻,首先得有新闻源,也就是抓取的目标网站。国内的新闻网站,从中央到地方,从综合到垂直行业,大大小小有几千家新闻网站。百度新闻(news.baidu.com)收录的大约两千多家。那么我们先从百度新闻入手。打开百度新闻的网站首页:news.baidu.com我们可以看到这就是一个新闻聚合网页,里面...
2024-01-10
爬虫的基本概念
一、为什么要学习爬虫学习爬虫,可以私人订制一个搜索引擎,并且可以对搜索引擎的工作原理进行更深层次地理解。当下是大数据时代,在这个信息爆炸的时代,我们可以利用爬虫获取大量有价值的数据,通过数据分析获得更多隐性的有价值的规律。方便就业。从就业的角度来说,爬虫工程师...
2024-01-10
爬虫爬取图片问题?
这是我写的爬虫的项目地址项目不报错,但是问题是下载图片到本地后经常性的是图片不完整,如下:这是下载图片的核心代码,如下:@Override public void run() { Response res = null; try { res = Jsoup.connect(src).ignoreContentType(true).timeout(30000).execute(); byte[] bytes = res.bodyAs...
2024-01-10
学会这些,轻松搞定爬虫!
什么是 “爬虫”?简单来说,写一个从 web 上获取需要数据并按规定格式存储的程序就叫爬虫;爬虫理论上步骤很简单,第一步获取 html 源码,第二步分析 html 并拿到数据。但实际操作,老麻烦了~用 Python 写 “爬虫” 有哪些方便的库常用网络请求库:requests、urllib、urllib2、urllib 和 urllib2 是 Python 自...
2024-01-10
爬虫定时执行
我把爬虫设置了每6个小时候运行1次,结果执行了。问题是每次点开始后立刻就会先运行一次,然后再每6小时执行一次。怎么让它在点开始时那次不运行?!我用了@小鬼web的方法报错了,不知道是什么没装还是怎么的。图片描述哦,已经可以了。把main文件放在和setting文件一个目录就行了。回答:...
2024-01-10
AJAX接口拉购网职位搜索爬虫
拉购网职位搜索爬虫分析职位搜索调用接口:浏览器开发者模式(快捷键F12)切换手机模式,打开拉购网职位搜索链接 https://m.lagou.com/search.html输入搜索关键词, 例如"Python" ,可以看到右侧的XHR中出现一个AJAX调用请求 https://m.lagou.com/search.json?city=%E5%85%A8%E5%9B%BD&positionName=Python&pageNo=1&pageSize=15找到了AJAX...
2024-01-10
某网站翻页js 爬虫
网址:http://jzsc.mohurd.gov.cn/dat...import requestsimport jsondata_form = {"pg":11,"ps":15,"tt":373478,"pn":5,"pc":24899,"id":'',"st":True}headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/7...
2024-01-10
网页爬虫,F12可以看到的内容,但爬出来的源码里没有
想要做一个自动爬取公司内网word的一个工具,但是在爬取日期的时候,发现爬出来的源码缺失了很多信息,跟F12看到的不一样。尝试用了xpath和正则表达式解析,解析出来的全是空列表。搜了很多,基本都说是异步加载的问题。但查Network里看到的是第一条出来的,Doc里的内容。所以应该不是异步加...
2024-01-10
大规模异步新闻爬虫之网络请求函数的优化
前面我们实现了一个简单的再也不能简单的新闻爬虫,这个爬虫有很多槽点,估计大家也会鄙视这个爬虫。上一节最后我们讨论了这些槽点,现在我们就来去除这些槽点来完善我们的新闻爬虫。问题我们前面已经描述清楚,解决的方法也有了,那就废话不多讲,代码立刻上(Talk is cheap, show me the code!)...
2024-01-10
用PYTHON爬虫简单爬取网络小说
用PYTHON爬虫简单爬取网络小说。这里是17K小说网上,随便找了一本小说,名字是《千万大奖》。里面主要是三个函数:1、get_download_url() 用于获取该小说的所有章节的URL。分析了该小说的目录页http://www.17k.com/list/2819620.html的HTML源码,发现其目录是包含在Volume里的A标签合集。所以就提取出了URLS列表。2、...
2024-01-10
用C#做网络爬虫的步骤教学
如今代码圈很多做网络爬虫的例子,今天小编给大家分享的是如何用C#做网络爬虫。注意这次的分享只是分享思路,并不是一整个例子,因为如果要讲解一整个例子的话,牵扯的东西太多。1、新建一个控制台程序,这个相信大家都懂的2、建好以后,打开主程序文件,导入发送http请求的库,这里用的...
2024-01-10
写网络爬虫程序到底难在哪?
写爬虫,是一个非常考验综合实力的活儿。有时候,你轻而易举地就抓取到了想要的数据;有时候,你费尽心思却毫无所获。好多Python爬虫的入门教程都是一行代码就把你骗上了“贼船”,等上了贼船才发现,水好深~比如爬取一个网页可以是很简单的一行代码:r = requests.get('http://news.baidu.com')非常...
2024-01-10
原来网络爬虫的原理这么简单!
互联网上,公开数据(各种网页)都是以http(或加密的http即https)协议传输的。所以,我们这里介绍的爬虫技术都是基于http(https)协议的爬虫。在Python的模块海洋里,支持http协议的模块是相当丰富的,既有官方的urllib,也有大名鼎鼎的社区(第三方)模块 requests。它们都很好的封装了http协议请求的...
2024-01-10
网络爬虫是什么
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。下面我们来分析网络爬虫具体要做哪些核心工作:通过网络向指定的 URL 发送请...
2024-01-10
爬虫实战之爬取房天下新房数据
本示例主要用到requests库和bs4库,requests库用来获取网页内容,bs4库则是解析网页内容,获取有用数据。代码中url可切换当地房天下网址。代码如下# -*- coding:utf-8 -*-# author:zhoulong'''房天下天水新房信息'''import requestsfrom bs4 import BeautifulSoupimport numpy as npimport reURL = 'http://newhouse.tianshui.fang.com...
2024-01-10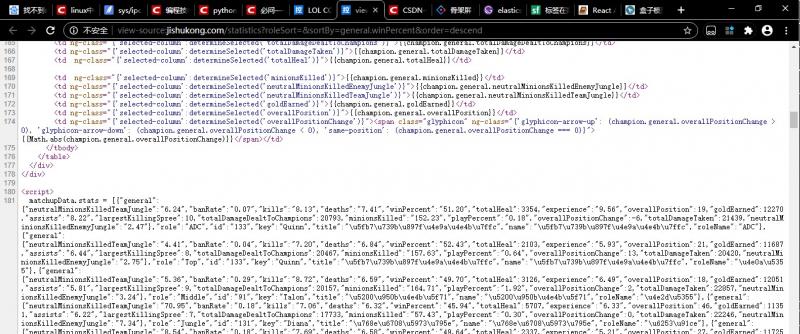
关于爬虫获取接口数据的问题
http://jishukong.com/statistics?roleSort=&sortBy=general.winPercent&order=descend这是网址,我在爬取的时候发现它的数据是通过js来获取的,但是我在控制台并没有发现它获取数据的地址。请问这一类的数据应该通过怎样的方式来获取?回答您好: 对于这个网页,他的数据应该就在你发的url里,我在源码的第181行看...
2024-01-10
爬虫技术只能用来爬数据吗
写爬虫抓数据只是爬虫技术的应用方向之一,一个公司可以靠着爬虫技术引来倍增的流量/用户, 完成关键的冷启动,还能用来打败对手;个人可以利用爬虫技术获得被动收入,俗称趟挣。 这篇聊一下公司篇。定义下爬虫技术为了抓数据所运用的模拟登录、模拟账号、养IP/账号池、抓包分析、模拟用户...
2024-01-10
爬虫如何抓取网页数据
爬虫抓取网页数据的方法:将网址当参数传递给requests包的get方法就可以爬到简单网页上面的所有信息,然后用“print”语句打印出来就可以了示例如下:爬取百度首页的网页内容:代码如下:执行结果如下:更多Python知识,请关注:云海天python教程网!!...
2024-01-10
关于一个网站的反爬虫问题
我现在遇到的这个网站,似乎是使用了distil networks这个反爬虫服务, 如果需要拿到数据就必须带上 cookie,不带 cookie 的请求都会被直接返回<!DOCTYPE html><html><head><META NAME="ROBOTS" CONTENT="NOINDEX, NOFOLLOW"><meta http-equiv="cache-control" content="max-age=0" /><meta http-equiv="cache-control" content="no...
2024-01-10
API接口访问频次限制/网站恶意爬虫限制/网站恶意访问限制方案
API接口访问频次限制 / 网站恶意爬虫限制 / 网站恶意访问限制 方案采用多级拦截,后置拦截的方式体系化解决1 分层拦截1.1 第一层 商业web应用防火墙(WAF)直接用商业服务传统的F5硬件,不过现在用的很少了云时代就用云时代的产品,典型代表 阿里云 web应用防火墙1.2 第二层 API 网关(API Gateway)层API 网关...
2024-01-10
Go语言并发爬虫的具体实现
目录写在前面1. 单线程爬虫2. 多线程爬虫2.1 channel main函数2.2 sync.WaitGroup3. 源码地址写在前面这篇文章主要让大家明白多线程爬虫,因为go语言实现并发是很容易的。这次的服务端,是我们之前搭建的电子商城平台,所以我们不担心ip被封之类的问题。而实际生产环境中,其实我们都是用python爬虫的...
2024-01-10
坚持住啊,还在代码屎山中爬行的同事们
"There are only two hard things in Computer Science: cache invalidation and naming things."— Phil Karlton在计算机领域只有两件艰难的事情:缓存失效和对象命名。这还真不是一个笑话。写代码是比较容易的事情,但是阅读别人的代码,那就因人而异了。好的工程师写出来的代码可读性很高,比如我上家公司的同事旭总...
2024-01-10
JAVA爬虫代码
工程目录:所需要的jar包为: jsoup-1.10.2.jar/** * Created by wangzheng on 2017/2/19. */public class Article { /** * 文章链接的相对地址 */ private String address; /** * 文章标题 */ private String title; /** * 文章简介 */ private String despti...
2024-01-10

