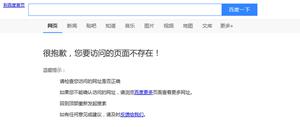
爬虫百度百科要求验证,请问该如何处理?
爬虫要求验证,请问该如何处理?请赐教,不胜感激。
import urllib.requestimport urllib.parse
from lxml import etree
import re
url = 'https://bke.bd.com/item/' + urllib.parse.quote('周杰伦')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
req = urllib.request.Request(url=url, headers=headers, method='GET')
response = urllib.request.urlopen(req)
text = response.read().decode('utf-8')
print(text)
html = etree.HTML(text)
lt=[]
for i in range(1,6):
sen_list = html.xpath(f"/html/body/div[3]/div[2]/div/div[1]/div[4]/div[{i}]//text()")
l = [item.strip('\n') for item in sen_list]
l=''.join(l)
l=re.sub("\[+\d+\]","",l)
lt.append(l)
for i in range(len(lt)):
print(lt[i])
这种情况用梯子换ip能解决问题吗
回答:
明显是特征被识别到了,换IP肯定是不能的,使用代理有可能够解决。模拟浏览器访问会好一些。
回答:
咋还没解决 ? 之前回复过应该是 TLS 特征被识别,还以为应该知道怎么解决了
pip install aiohttp代码是你之前问题的代码改的
import urllib.parseimport asyncio
import aiohttp
from lxml import etree
async def query(content):
# 请求地址
url = 'https://baike.baidu.com/item/' + urllib.parse.quote(content)
# 请求头部
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
async with aiohttp.ClientSession(headers=headers) as session:
async with session.get(url) as response:
text = await response.text()
# 构造 _Element 对象
html = etree.HTML(text)
# 使用 xpath 匹配数据,得到匹配字符串列表
sen_list = html.xpath('//div[contains(@class,"lemma-summary") or contains(@class,"lemmaWgt-lemmaSummary")]//text()')
# 过滤数据,去掉空白
sen_list_after_filter = [item.strip('\n') for item in sen_list]
# 将字符串列表连成字符串并返回
return ''.join(sen_list_after_filter)
async def main():
while (True):
content = input('查询词语:')
result = await query(content)
print("查询结果:%s" % result)
if __name__ == '__main__':
asyncio.run(main())

原理就是 urllib.request 库对于 https 请求即 TLS 特征被识别
只需要换个不依赖 urllib.request 实现的请求库如 aiohttp
可参考
- SSL 指纹识别和绕过
以上是 爬虫百度百科要求验证,请问该如何处理? 的全部内容, 来源链接: utcz.com/p/938724.html