AJAX接口拉购网职位搜索爬虫

爬虫">拉购网职位搜索爬虫
分析职位搜索调用接口:
- 浏览器开发者模式(快捷键
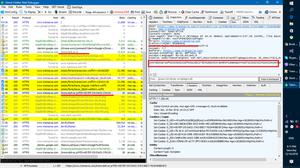
F12)切换手机模式,打开拉购网职位搜索链接 https://m.lagou.com/search.html - 输入搜索关键词, 例如"Python" ,可以看到右侧的
XHR中出现一个AJAX调用请求 https://m.lagou.com/search.json?city=%E5%85%A8%E5%9B%BD&positionName=Python&pageNo=1&pageSize=15 - 找到了AJAX接口后,我们就可以使用
requests模拟发送请求来搜索职位信息了。
下面是实现源码:
#!/usr/bin/env python3# -*-coding:utf8-*-
import logging
import traceback
import requests
from requests.adapters import HTTPAdapter
import json
import random
import sys
def usage():
print("Usage:
lagou_search <keyword> [page_number] [地理位置]
<keyword> : 搜索职位名称
[page_number]显示页数,每页15条
------
")
if len(sys.argv) < 2:
usage()
sys.exit(1)
keyword = sys.argv[1]
if len(sys.argv) > 2:
page_num = int(sys.argv[2])
else:
page_num = 1
if len(sys.argv) > 3:
city = sys.argv[3]
else:
city = "全国"
LOG_FORMAT = "%(asctime)s - %(filename)s - %(funcName)s - %(lineno)s - %(levelname)s - %(message)s"
logging.basicConfig(filename=f"log.lagou.log", level=logging.DEBUG, filemode="a", format=LOG_FORMAT)
def get_proxy():
proxy_uri = "socks5://127.0.0.1:1084"
proxies = {
"http": proxy_uri,
"https": proxy_uri
}
return proxies
def search_jobs(keyword, page):
proxies = get_proxy()
myheaders = {
"User-Agent": "Mozilla/5.0 (Linux; Android 7.1.1; OS105 Build/NGI77B) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.84 Mobile Safari/537.36",
}
headers = {
"Host": "m.lagou.com",
"Accept": "application/json,text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Linux; Android 7.1.1; OS105 Build/NGI77B) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.84 Mobile Safari/537.36",
"Referer": "https://m.lagou.com/search.html",
"Accept-Language": "zh-CN,zh;q=0.9"
}
payload = {
"city": city,
"positionName": keyword,
"pageNo": 1,
"pageSize": 15
}
result = {}
try:
s = requests.Session()
s.mount("http://", HTTPAdapter(max_retries=5))
s.mount("https://", HTTPAdapter(max_retries=5))
resp = s.get("https://m.lagou.com/search.html", headers=myheaders, proxies=proxies, timeout=10)
for pn in range(1, page+1):
payload["pageNo"] = pn
try:
resp = s.get("https://m.lagou.com/search.json", params=payload, proxies=proxies, timeout=10, headers=headers)
jscontent = resp.text
jsDict = json.loads(jscontent)
statusJson = jsDict["state"] if "state" in jsDict.keys() else 0
if statusJson == 1:
if "content" in jsDict.keys():
jsList = jsDict["content"]["data"]["page"]["result"]
for jsData in jsList:
result["positionId"] = jsData["positionId"]
result["positionName"] = jsData["positionName"]
result["city"] = jsData["city"]
result["salary"] = jsData["salary"]
result["companyFullName"] = jsData["companyFullName"]
result["link"] = "https://www.lagou.com/jobs/" + str(jsData["positionId"]) + ".html"
print(json.dumps(result, ensure_ascii=False))
except Exception as e:
logging.exception(str(e))
except requests.exceptions.ProxyError as e:
logging.exception(f"proxy_error " + str(e))
except Exception as e:
logging.exception(f"proxy: " + str(e))
if __name__ == "__main__":
try:
search_jobs(keyword, page_num)
except Exception as e:
print(e)
脚本工具使用方法:
╰─ ./lagou_search.pyUsage:
lagou_search <keyword> [page_number] [地理位置]
<keyword> : 搜索职位名称
[page_number]显示页数,每页15条
------
以上是 AJAX接口拉购网职位搜索爬虫 的全部内容, 来源链接: utcz.com/z/531114.html