爬虫 页面不存在_百度搜索
1.学写爬虫,遇到一个问题,加了values={"wd":"test","ie":"utf-8"}就报错了,也就是我向百度页面搜索里面输入test就报错,百度了一圈没找到答案,请教一下各位大神如何处理,如果可以的话能否说明这是为什么,以及怎么处理类似的情况,谢谢!
2.代码如下(版本2.7):
(randHeader用来生成随机的Header,savef保存输出结果,logging.info用来调试,try处理可能的错误,其他部分就是爬虫的主体)
#coding:utf-8import random
import urllib2
import urllib
import os
import logging
logging.basicConfig(level=logging.INFO)
def savef(html,tpath):
#12输入输出目录不存在,就创建
if not os.path.exists(tpath):
os.makedirs(tpath)
#12打开需要保存的文件(该命令下,如果文件不存在就创建新文件)
with open(os.path.join(tpath,'2.html'),'w') as f:
f.write(html)
with open(os.path.join(tpath,'2.xml'),'w') as f:
f.write(html)
with open(os.path.join(tpath,'2.txt'),'w') as f:
f.write(html)
def randHeader():
head_connection = ['Keep-Alive','close']
head_accept = ['text/html, application/xhtml+xml, */*']
head_accept_language = ['zh-CN,fr-FR;q=0.5','en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3']
head_user_agent = ['Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.95 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; rv:11.0) like Gecko)',
'Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1',
'Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070309 Firefox/2.0.0.3',
'Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070803 Firefox/1.5.0.12',
'Opera/9.27 (Windows NT 5.2; U; zh-cn)',
'Mozilla/5.0 (Macintosh; PPC Mac OS X; U; en) Opera 8.0',
'Opera/8.0 (Macintosh; PPC Mac OS X; U; en)',
'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.12) Gecko/20080219 Firefox/2.0.0.12 Navigator/9.0.0.6',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Win64; x64; Trident/4.0)',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0)',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Maxthon/4.0.6.2000 Chrome/26.0.1410.43 Safari/537.1 ',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; .NET4.0C; .NET4.0E; QQBrowser/7.3.9825.400)',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0 ',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.92 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; BIDUBrowser 2.x)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/3.0 Safari/536.11']
header = {
'Connection': head_connection[0],
'Accept': head_accept[0],
'Accept-Language': head_accept_language[1],
'User-Agent': head_user_agent[random.randrange(0,len(head_user_agent))]
}
return header
"""
#输出随机Header
for i in range(10):
print(randHeader())
"""
url1="http://www.baidu.com/"
kkk=url1.split("/")[2]
headers=randHeader()
logging.info("headers=%s" % headers)
values={"wd":"test","ie":"utf-8"}
data=urllib.urlencode(values)
request=urllib2.Request(url1,data,headers)
#HTTP错误处理
try:
urllib2.urlopen(request)
except URLError,e:
logging.info("e.code=%s" % e.code)
logging.info("e.read()=" % e.read())
response=urllib2.urlopen(request)
html=response.read()
#根目录
cpath="I:\\"
#拼输出目录
tpath=os.path.join(cpath,kkk)
savef(html,tpath)
3.输出结果如下:
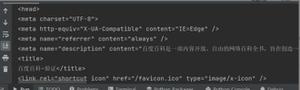
<!DOCTYPE html><!--STATUS OK-->
<html>
<head>
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<meta http-equiv="content-type" content="text/html;charset=utf-8">
<meta content="always" name="referrer">
<title>页面不存在_百度搜索</title>
<style data-for="result">
...由于太多,后面就省略了

回答:
因为你的百度地址错了
实际上还要加一个/s,
http://www.baidu.com/s
完整包括关键词的地址是这样
http://www.baidu.com/s?wd=key...
包括页码的地址是这样的
http://www.baidu.com/s?wd=key...
你如果不加s的话,就会提示页面没找到
====================================
#/usr/bin/python# -*- coding: Utf-8 -*-
# -*- author: Wd0g -*-
import requests,gzip
def httpGet(url):
try:
res = requests.session().get(url,verify=True)
except Exception as e:
return False
try:
data = res.content.decode('utf-8')
except:
try:
data = res.content.decode('gbk')
except:
data = gzip.decompress(res.content).decode()
return data
def baidu(keywords, pageNum):
url = 'http://www.baidu.com/s?wd=%s&pn=%d' %(keywords, pageNum*10)
return httpGet(url)
print(baidu('wd0g',0))
这是python3.5的代码,我这里是没有出现你说过的问题
回答:
一个简单的Python爬虫写这么多代码。。。。。。
import urllib.requesthtml = urllib.request.urlopen("http://www.baidu.com")
content = html.read()
content = content.decode("utf-8")
print(content)
回答:
写爬虫的话用requests库更为方便一些,不用设置复杂的Header
import requestsresponse = requests.get('http://www.baidu.com')
response.status_code # 200
response.text # <!doctype html><html>.....</html>
回答:
import urllibimport requests
keyword = 'test'
url = 'http://www.baidu.com/s?wd=%s' % urllib.quote(keyword)
res = requests.get(url)
html = res.content
以上是 爬虫 页面不存在_百度搜索 的全部内容, 来源链接: utcz.com/a/160306.html