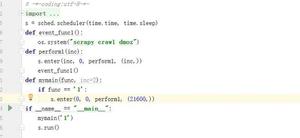
爬虫爬取图片问题?
这是我写的爬虫的项目地址
项目不报错,但是问题是下载图片到本地后经常性的是图片不完整,如下:
这是下载图片的核心代码,如下:
@Override public void run() {
Response res = null;
try {
res = Jsoup.connect(src).ignoreContentType(true).timeout(30000).execute();
byte[] bytes = res.bodyAsBytes();
File file = new File(path + name);
if (!file.exists()) {
RandomAccessFile raf = new RandomAccessFile(file, "rw");
raf.write(bytes);
raf.close();
}
} catch (IOException e1) {
e1.printStackTrace();
}
}
经过资料查询,感觉是范围请求 Range的问题或者自己没发现的问题?希望大家给看下,谢谢
回答:
感觉是响应数据没获取完整,你debug一下看看响应的实际数据大小和你保存的数据大小是否有出入。
又或者因为还有一部分数据还在缓冲区中,没来得及写到文件,此时进程退出,导致数据不完整,关闭文件流之前执行一下flush操作。
6月23日更新:
我用如下代码下载了一张图片,图片被完整的下载下来了,没出现题主的问题
public static void main(String[] args) { Connection.Response res = null;
String src = "https://ws2.sinaimg.cn/large/6c7edb3fly1fguvf22hznj215o0k67h5.jpg";
try {
res = Jsoup.connect(src).ignoreContentType(true).timeout(30000).execute();
byte[] bytes = res.bodyAsBytes();
File file = new File("1.png");
if (!file.exists()) {
RandomAccessFile raf = new RandomAccessFile(file, "rw");
raf.write(bytes);
raf.close();
}
} catch (IOException e1) {
e1.printStackTrace();
}
}
更新2:
把获取响应的语句改为这样:
res = Jsoup.connect(src).ignoreContentType(true).timeout(30000).maxBodySize(0).execute();参考 http://jmchung.github.io/blog...
回答:
试了下页数从3到1和从1到3,始终就是固定的几个图片 写入的字节流不全。
回答:
非常感谢 @Derobukal 问题已经解决了,已采纳和关注
以上是 爬虫爬取图片问题? 的全部内容, 来源链接: utcz.com/a/166672.html