浅谈模块化加载的实现原理
相信很多人都用过 seajs、 requirejs 等这些模块加载器,他们都是十分便捷的工程管理工具,简化了代码的结构,更重要的是消除了各种文件依赖和命名冲突问题,并利用 AMD / CMD 规范统一了格式。如果你不太明白模块化的作用,建议看看玉伯写的 一篇文章。
为什么他们会想到使用模块化加载呢,我觉得主要是两点。
- 一是按需加载,业务越来越大,基础代码也会越来越多,开发人员可能开发了一百个小工具,而且都塞在一个叫做 utils.js 的包里,但是一个页面可能只需要三到五个小工具,如果直接去加载这个 utils.js 岂不是很大的浪费,PC 端还好,主要是无线端,剩下 1KB 那都是很大的价值啊,所以呢,如今很多框架的开发都体现出细颗粒度的分化,像百度研究比较卖力的 tangram,阿里放满产品线的 kissy,几乎是细分到了微粒程度,这种细分方式也促进了模块化加载技术的发展,比如为了减少请求数量,kissy 的 config 中开启 combo 就可以合并多个请求为一个等等。
- 第二点,应该也是从服务器那边参考而来的,服务器脚本很多都是以文件为单位分离的,如果要利用其它文件的功能,可以轻而易举的 require 或者 include 进来,我没有去研究这些加载函数的内部实现原理,稍微猜猜应该是把文件写入到缓存,遇到 include 之类的加载函数,暂停写入,找到需要 include 的文件地址,把找到的文件接着上面继续写入缓存,以此类推,直到结束,然后编译器进行统一编译。
一、模块化加载的技术原理
先不考虑各种模块定义规范,本文目的只是简要的分析加载原理, CMD / AMD 规范虽内容然不多,但是要实现起来,工程量还是不小。文章后面会提到。
1、数据模块的加载
既然是模块化加载,想办法把模块内容拿到当然是重头戏,无论是 script 还是 css 文件的加载,一个 script 或者 link 标签就可以搞定问题,不过我这里采用的是 ajax,目的是为了拿到 script 的代码,也是为了照顾后面要说的 CMD 规范。
var require = function(path){ var xhr = new XMLHttpRequest(), res;
xhr.open("GET", path, true);
xhr.onreadystatechange = function(){
if(xhr.readyState == 4 && xhr.status == 200){
// 获取源码
res = xhr.responseText;
}
}
xhr.send();
};
创建 script 便签加载脚本不会存在跨域问题,不过拿到的脚本会被浏览器立马解析出来,如果要做同异步的处理就比较麻烦了。没有跨域的文件我们就通过上面的方式加载,如果脚本跨域了,再去创建标签,让文档自己去加载。
// 跨域处理if(crossDomain){
var script = document.createElement("script");
script.src = path;
(document.getElementsByTagName("head")[0] || document.body).appendChild(script);
}
2、解析模块的层次依赖关系
模块之间存在依赖关系是十分正常的,如一个工程的文件结构如下:
project/├── css/
│ └── main.css
├── js/
│ ├── require.js
│ └── modlues/
│ ├── a.js
│ ├── b.js
│ └── c.js
└── index.html
而这里几个模块的依赖关系是:
┌> a.js -> b.jsindex.html -|
└> c.js
// a.js
require("./js/test/b.js");
// b.js
console.log("i am b");
// c.js
console.log("i am c");
我们要从 index.html 中利用 require.js 获取这一连串的依赖关系,一般采用的方式就是正则匹配。如下:先拿到 function 的代码,然后正则匹配出第一层的依赖关系,接着加载匹配到关系的代码,继续匹配。
// index.html<script type="text/javascript" src="./js/require.js"></script>
<script type="text/javascript">
function test(){
var a = require("./js/modlues/a.js");
var c = require("./js/modlues/c.js");
}
// toString 方法可以拿到 test 函数的 code
start(test.toString());
</script>
整个函数的入口是 start,正则表达式为:
var r = /require\((.*)\)/g;var start = function(str){
while(match = r.exec(str)) {
console.log(match[1]);
}
};
由此我们拿到了第一层的依赖关系,
["./js/modlues/a.js", "./js/modlues/c.js"]接着要拿到 a.js 和 b.js 的文件层次依赖,之前我们写了一个 require 函数,这个函数可以拿到脚本的代码内容,不过这个 require 函数要稍微修改下,递归去查询和下载代码。
var cache = {};var start = function(str){
while(match = r.exec(str)) {
console.log(match && match[1]);
// 如果匹配到了内容,下载 path 对应的源码
match && match[1] && require(match[1]);
}
};
var require = function(path){
var xhr = new XMLHttpRequest(), res;
xhr.open("GET", path, true);
xhr.onreadystatechange = function(){
if(xhr.readyState == 4 && xhr.status == 200){
res = xhr.responseText;
// 缓存文件
cache[path] = res;
// 继续递归匹配
start(res);
}
}
xhr.send();
};
上面的代码已经可以很好地拿到文件递归关系了:
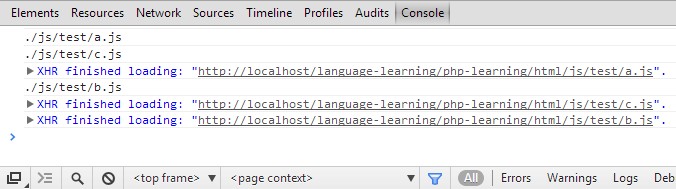
3、添加事件机制,优化管理代码
但是我们有必要先把 responseText 缓存起来,如果不缓存文件,直接 eval 得到的 responseText 代码,想想会发生什么问题~ 如果模块之间存在循环引用,如:
┌> a.js -> b.jsindex.html -|
└> b.js -> a.js
那 start 和 require 将会陷入死循环,不断的加载代码。所以我们需要先拿到依赖关系,然后解构关系,分析出我们需要加载哪些模块。值得注意的是,我们必须按照加载的顺序去 eval 代码,如果 a 依赖 b,先去执行 a 的话,一定会报错!
有两个问题我纠结了半天,上面的请求方式,何时会结束?用什么方式去记录文件依赖关系?
最后还是决定将 start 和 require 两个函数的相互递归修改成一个函数的递归。用一个对象,发起请求时把 URL 作为 key,在这个对象里保存 XHR 对象,XHR 对象请求完成后,把抓取到的新请求再用同样的方式放入这个对象中,同时从这个对象中把自己删除掉,然后判断这个对象上是否存在 key, 如果存在说明还有 XHR 对象没完成。
var r = /require\(\s*"(.*)"\s*\)/g;var cache = {}; // 文件缓存
var relation = []; // 依赖过程控制
var obj = {}; // xhr 管理对象
//辅助函数,获取键值数组
Object.keys = Object.keys || function(obj){
var a = [];
for(a[a.length] in obj);
return a ;
};
// 入口函数
function start(str){
while(match = r.exec(str)){
obj[match[1]] = new XMLHttpRequest();
require(obj[match[1]], match[1]);
}
}
// 递归请求
var require = function(xhr, path){
//记录依赖过程
relation.push(path);
xhr.open("GET", path, true);
xhr.onreadystatechange = function(){
if(xhr.readyState == 4 && xhr.status == 200){
var res = xhr.responseText;
// 缓存文件
cache[path] = res;
// 从xhr对象管理器中删除已经加载完毕的函数
delete obj[path];
// 如果obj为空则触发 allLoad 事件
Object.keys(obj).length == 0 ? Event.trigger("allLoad") : void 0;
//递归条件
while(match = r.exec(res)){
obj[match[1]] = new XMLHttpRequest();
require(obj[match[1]], match[1]);
}
}
}
xhr.send();
};
上面的代码已经基本完成了文件依赖分析,文件的加载和缓存工作了,我写了一个,有兴趣可以看一看。这个demo的文件结构为:
project/├── js/
│ ├── require.js
│ └── test/
│ ├── a.js
│ ├── b.js
│ ├── c.js
│ ├── d.js
│ └── e.js
└── index.html
//文件依赖关系为
┌> c.js
┌> a.js ->-|
index.html -| └> d.js
└> b.js -> e.js
戳我 → Demo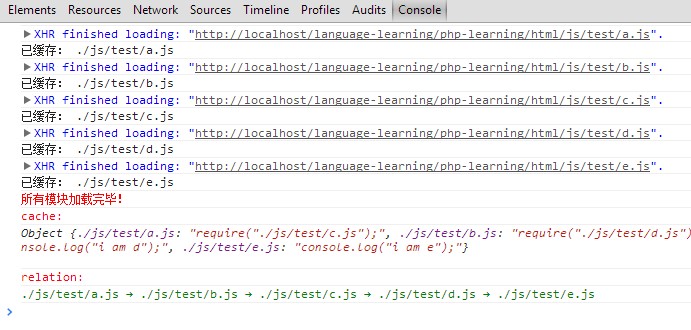
4、CMD 规范的介绍
上面写了一大堆内容,也实现了模块加载器的原型,但是放在实际应用中,他就是个废品,回到最开始,我们为什么要使用模块化加载。目的是为了不去使用麻烦的命名空间,把复杂的模块依赖交给 require 这个函数去管理,但实际上呢,上面拿到的所有模块都是暴露在全局变量中的,也就是说,如果 a.js 和 b.js 中存在命名相同的变量,后者将会覆盖前者,这是我们不愿意看到的。为了处理此类问题,我们有必要把所有的模块都放到一个闭包中,这样一来,只要不使用 window.vars 命名,闭包之间的变量是不会相互影响的。我们可以使用自己的方式去管理代码,不过有人已经研究处理一套标准,而且是全球统一,那就拿着用吧~
关于 CMD 规范,我这里就不多说了,可以去看看 草案,玉伯也翻译了一份,戳我。每一模块有且仅有一个对外公开的接口 exports,如:
define(function(require, exports) { // 对外提供 foo 属性
exports.foo = 'bar';
// 对外提供 doSomething 方法
exports.doSomething = function() {};
});
剩下的工作就是针对 CMD 规范写一套符合标准的代码接口,这个比较琐碎,就不写了。
二、额外的话题
上面的代码中提到了关于 Event 的事件管理。在模块全部加在完毕之后,需要有个东西告诉你,所以顺手写了一个 Event 的事件管理器。
// Eventvar Event = {};
Event.events = [];
Event.on = function(evt, func){
for(var i = 0; i < Event.events.length; i++){
if(Event.events[i].evt == evt){
Event.events[i].func.push(func);
return;
}
}
Event.events.push({
evt: evt,
func: [func]
});
};
Event.trigger = function(evt){
for(var i = 0; i < Event.events.length; i++){
if(Event.events[i].evt == evt){
for(var j = 0; j < Event.events[i].func.length; j++){
Event.events[i].func[j]();
}
return;
}
}
};
Event.off = function(evt){
for(var i = 0; i < Event.events.length; i++){
Event.events.splice(i, 1);
}
};
我觉得 seajs 是一个很不错的模块加载器,如果感兴趣,可以去看看他的源码实现,代码不长,只有一千多行。模块的加载它采用的是创建文本节点,让文档去加载模块,实时查看状态为 interactive 的 script 标签,如果处于交互状态就拿到他的代码,接着删除节点。当节点数目为 0 的时候,加载工作完成。
本文没有考虑 css 文件的加载问题,我们可以把它当做一个没有 require 关键词的 js 文件,或者把它匹配出来之后另作处理,因为他是不可能存在模块依赖关系的。
然后就是很多很多细节,本文的目的并不是写一个类似 seajs 的模块管理工具,只是稍微说几句自己对这玩意儿的看法,如果说的有错,请多多吐槽!
三、参考资料
- https://github.com/seajs/seajs/issues seajs issues
以上是 浅谈模块化加载的实现原理 的全部内容, 来源链接: utcz.com/p/234157.html