[MIT6.824-lab1] 批处理算法模型MapReduce
开个新专题,总结下MIT-6.824分布式系统的实验。同时不熟悉golnag内存模型的朋友也可用python做实验,原理是一样的。
原文链接
- Lab1-MapReduce golang version
- Lab1-MapReuduce python version
MIT-6.824课程实验一,使用golang完成单机版本的MapReduce, 具体问题场景为WordsCount。需要通过的测试主要有:
- 正确性,与串行结果比较
- 可靠性,能应付某个作业失败的情况(主要是Worker失效)
- 可扩展性,增加工作节点数量能 接近线性地 提升性能
MapReduce 是什么
MapReduce(以下称MR), 狭义上是指google首次在论文[1]中提出的分布式批处理模型,广义上指使用了mapper和reduce两种函数处理工作的范式。有些语境下也单指Hadoop或Spark中MR计算组件。
MR是一种应对大型数据系统应用中的 批处理 计算模型。与批处理截然不同的是流处理的情景。
批处理系统
批处理系统接收大量的输入数据,运行一个作业来处理数据,并产生输出数据。作业往往需要执行一段时间(从几分钟到几天),批量作业通常以定时任务形式执行。
MR编程模型
- Map函数:
map(contents) -> list(k,v) - Reduce函数:
reduce(k, list(v)) -> list(v)
map函数的输入通常是分布式存储系统中的某个数据块(数据格式并不重要),产生一系列的键值对, 例如在WordCount中产生<wordm 1>.
reduce函数输入的是键和其在map函数的输出,整合所有键值到一定的形式,如在WordCounts中就是统计下改键的数量。
map和reduce函数已经被很多语言内置为标准的通用模块,你会在python和js中使用原生的map与reduce函数。
如果用串行的思维看待这两个函数其实是无意义的,之所以将任务分块由map处理,再用reduce聚合map结果是因为任务的独立性可使用分布式加速。分布式加速在mr的情景下可简单理解为并行加速,使用多个worker执行map作业和reduce作业。承担worker角色的小到可以是个线程(进程),大到可以是另一台机器。
分布式MR
分布式MR与单机串行的区别在于:
- 输入分布式,作业内容常常在分布式存储系统中,物理上不在一起。Map接受的分块区域散步在集群中。
- 执行分布式,通常由集群各个节点上的worker执行各个子任务
- 中间结果分布式,MR会产生一些中间结果,其存储物理上也不在一起
- 输出分布式,reduce作业的输出也分布不在一处
既然加上分布式了,那么分布式必须要考虑的问题也随之而来:
- 可用性:结果是否和串行结果一致
- 可靠性:节点worker任务失败的情况能否自我修复任务进度
- 可扩展性:增加worker数量能否提升性能
那怎么在集群上实现这个编程模型呢?其实google论文中给出了详细的实现细节:
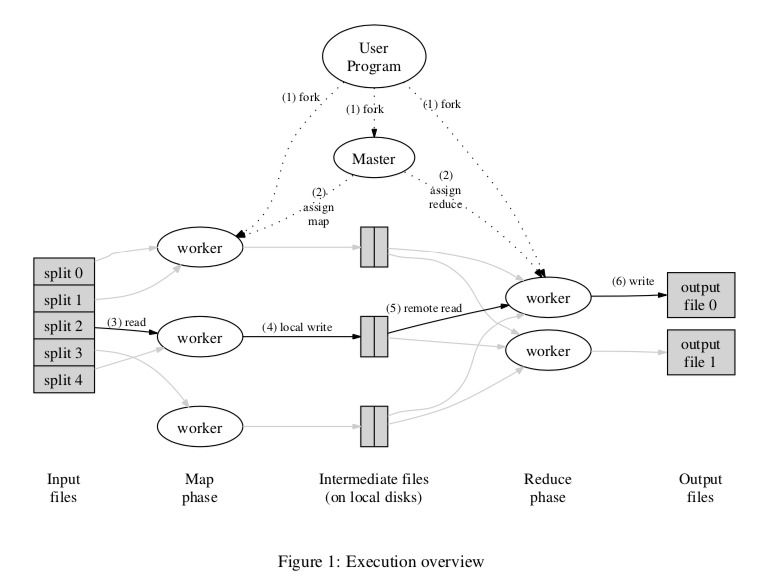
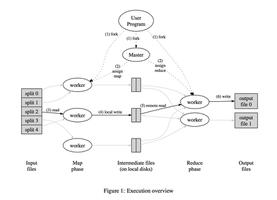
执行流程
论文中也声明MR可以有多种实现方式,图中只是针对Google集群环境的方式。先简要概括下他的流程:
- 以64MB为块大小对输入文件进行分块成 M 个map任务
- 启动一个master程序和若干worker程序。master负责将任务调度给空闲的worker
- 接受到map任务的worker执行用户定义好的任务逻辑,并将输出的键值对结果保持在内存中(buffered in memory)
- 周期性地将内存缓存的键值对结果由**分块函数(分区函数)**在本地分为 R 个块落盘处理,落盘的位置信息需要发送给master
- 领取到reduce任务的worker接受master的分块位置信息,通过远程调用在集群寻址读取相应的reduce数据
- reduce任务将读取到的中间值先排序,再处理,将解除输出存储
- reduce的结果文件应该为 R 个, 所有任务结束后再将其一起聚合成总结果
分布式的特点就是需要一个总调度,记录集群的运行信息。
容错控制
论文中建议的容错控制为发送heartbreak 包给worker进行监测,不回应就认为该任务失败,重新调度。
任务粒度
在真正做lab1时,需要考虑map和reduce任务的划分粒度,具体就是分区函数。对于lab1的map划分直接以文件为单位。reduce采用hash(key) % ReduceNumber的常规做法。
Lab-01 单机多线程实现
论文还介绍了更多实践细节,不过都针对大型集群的。上述master和worker的工作流程看似简单优雅,可是真的实现起来却不那么容易。lab-1不考虑多台机器,使用线程模拟worker,使用rpc来通信。
master的实现较worker更为复杂些,他设计到的线程更多,因为每个worker与master通信就建立一个线程(golang中是协程),同时master需要做大量同步的工作来保证任务的完成和数据的一致性。
Master
我们先思考一下master主要的功能:
- 监测MR流程,是否完成
- 派发任务
- 监测任务状态,恢复失败任务
对应地再考虑他们可以在golang中如何实现:
- 监测MR流程 -> 全局变量控制,维护任务队列(使用channel来同步各个worker线程)
- 派发任务 -> 对任务队列上锁,保持一致性,动态与worker通信收集任务状态 (启动多个goroutine动态监测)
- 循环监测任务状态,将超时任务重新加入队列
现在来看关键代码:
// master的数据结构type Master struct {
taskCh chan Task // 任务队列
files []string
nReduce int
taskPhase TaskPhase // 任务流程同步
taskStats []TaskStat // 任务状态监测
workerID int
mu sync.Mutex // 同步互斥锁
done bool
}
func(m *Master)addTask(taskID int) {
m.taskStats[taskID].Status = TaskStatusQueue
task := Task{
FileName: "",
NReduce: m.nReduce,
NMaps: len(m.files),
TaskID: taskID,
Phase: m.taskPhase,
Alive: true,
}
if m.taskPhase == MapPhase {
task.FileName = m.files[taskID]
}
m.taskCh <- task // 放入任务队列,与worker请求线程同步
}
func(m *Master)checkBreak(taskID int) {
timeGap := time.Now().Sub(m.taskStats[taskID].StartTime)
if timeGap > MaxTaskRunTime {
// 任务超时重新加入队列
m.addTask(taskID)
}
}
func(m *Master)schedule() {
// 定期执行,监测任务状态和流程, 单独goroutine运行
// master持有的全局变量上锁
allFinish := true
m.mu.Lock()
defer m.mu.Unlock()
for seq, ts := range m.taskStats {
switch ts.Status {
case TaskStatusReady:
allFinish = false
m.addTask(seq)
case TaskStatusQueue:
allFinish = false
case TaskStatusRunning:
allFinish = false
m.checkBreak(seq)
case TaskStatusFinished:
case TaskStatusErr:
allFinish = false
m.addTask(seq)
default:
panic("tasks status schedule error...")
}
}
if allFinish {
if m.taskPhase == MapPhase {
m.initReduceTasks()
} else {
m.done = true
}
}
}
因为通信使用rpc,因此master作为server不会主动与worker通信,那么监测任务状态的功能需要让worker主动报告:
Worker
worker不涉及多线程同步问题,但他需要注册、报告任务的状态。
// worker运行的任务func(w *worker)run() {
for {
t := w.reqTask()
if !t.Alive {
fmt.Println("worker get task not alive, worker %d exit..", w.id)
return
}
w.doTask(t)
}
}
// rpc向master请求任务
func(w *worker)reqTask()Task {
args := ReqTaskArgs{}
args.WorkerID = w.id
reply := ReqTaskReply{}
if ok := call("Master.ReqTask", &args, &reply); !ok {
log.Fatal("request for task fail...")
}
return *reply.Task
}
func(w *worker)reportTask(task Task, done bool, err error) {
if err != nil {
log.Printf("%v", err)
}
args := ReportTaskArgs{}
args.Done = done
args.Seq = task.TaskID
args.Phase = task.Phase
args.WorkerId = w.id
reply := ReportTaskReply{}
if ok := call("Master.ReportTask", &args, &reply); !ok {
fmt.Println("report task fail:%+v", args)
}
}
func(w *worker)doTask(task Task) {
if task.Phase == MapPhase {
w.doMapTask(task)
} elseif task.Phase == ReducePhase {
w.doReduceTask(task)
} else {
panic(fmt.Sprintf("task phase err: %v", task.Phase))
}
}
总得来说,go的task channel是真正同步任务的主要数据结构,当请求任务的线程遇到<-taskCh时,如果通道内没有任务此线程会在此处阻塞,一直等到其他线程有taskCh <- task时才拿到任务重新唤醒。
More
因为我对golang的内存模型和同步运用还不是很熟练,在完成golang版本前我先用更熟悉的python完成了一版,其中思想都是一样的,只不过将taskCh Chan Task 换成了multiprocessing.Queue在官方文档中明确指出他是线程安全的,这意味着他可以帮助master来实现任务同步调度。
其他的python与golang的实现方式一致,全局变量需要加锁,master的协程在python中换为线程(不能换为进程,这样无法共享一些变量)。
参考
[1] MapReduce: Simplified Data Processing on Large Clusters
[2] pdos.csail.mit.edu/6.824
[3] <数据密集型系统应用设计(DDIA)> 第10章 批处理系统
以上是 [MIT6.824-lab1] 批处理算法模型MapReduce 的全部内容, 来源链接: utcz.com/a/31800.html