Java NIO Buffer实现原理详解
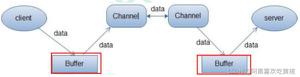
1、Buffer的继承体系

如上图所示,对于Java中的所有基本类型,都会有一个具体的Buffer类型与之对应,一般我们最经常使用的是ByteBuffer。
2、Buffer的操作API使用案例
举一个IntBuffer的使用案例:
/**
* @author csp
* @date 2021-11-26 3:51 下午
*/
public class IntBufferDemo {
public static void main(String[] args) {
// 分配新的int缓冲区,参数为缓冲区容量。
// 新缓冲区的当前位置为0,其界限(限制位置)为其容量。它具有一个底层实现数组,其数组偏移量为0。
IntBuffer buffer = IntBuffer.allocate(8);
for (int i = 0; i < buffer.capacity(); i++) {
int j = 2 * (i + 1);
// 将给定整数写入此缓冲区的当前位置,当前位置递增。
buffer.put(j);
}
// 重设此缓冲区,将限制位置设置为当前位置,然后将当前位置设置为0。
buffer.flip();
// 查看在当前位置和限制位置之间是否有元素:
while (buffer.hasRemaining()){
// 读取此缓冲区当前位置的整数,然后当前位置递增。
int j = buffer.get();
System.out.print(j + " ");
}
}
}
运行结果:
2 4 6 8 10 12 14 16
从该案例中可以看出,其实本质上这里就是把IntBuffer看作成一个数组容器使用,可以通过get方法向容器中读取数据(put方法向容器中写入数据)。
3、Buffer的基本原理
Buffer缓冲区本质上就是一个特殊类型的数组对象,与普通数组不同的地方在于,其内置了一些机制,能够跟踪和记录缓冲区的状态变化情况,如果我们使用get()方法从缓冲区获取数据或者使用put()方法把数据写入缓冲区,都会引起缓冲区状态的变化。
Buffer内置数组实现状态变化与追踪的原理,本质上是通过三个字段变量实现的:
- position:指定下一个将要被写入或者读取的元素索引,它的值由
get()/put()方法自动更新,在新创建一个Buffer对象时,position被初始化为0。 - limit:指定还有多少数据需要取出(在从缓冲区写入通道时),或者还有多少空间可以放入数据(在从通道读入缓冲区时)。
- capacity:指定了可以存储在缓冲区中的最大数据容量,实际上,它指定了底层数组的大小,或者至少是指定了准许我们 使用的底层数组的容量。
源码如下:
public abstract class Buffer {
// 三个字段属性之间的数值关系:0 <= position <= limit <= capacity
private int position = 0;
private int limit;
private int capacity;
...
}
如果我们创建一个新的容量大小为10的ByteBuffer对象,在初始化的时候,position设置为0,limit和 capacity设置为10,在以后使用ByteBuffer对象过程中,capacity的值不会再发生变化,而其他两个将会随着使用而变化。
我们来看一个例子:
准备一个txt文档,存放在项目目录下,文档中输入以下内容:
Java
我们用一段代码来验证position、limit和capacity这三个值的变 化过程,代码如下:
/**
* @author csp
* @date 2021-11-26 4:09 下午
*/
public class BufferDemo {
public static void main(String[] args) throws IOException {
FileInputStream fileInputStream = new FileInputStream("/Users/csp/IdeaProjects/netty-study/test.txt");
// 创建文件的操作管道
FileChannel channel = fileInputStream.getChannel();
// 分配一个容量为10的缓冲区(本质上就是一个容量为10的byte数组)
ByteBuffer buffer = ByteBuffer.allocate(10);
output("初始化", buffer);
channel.read(buffer);// 从管道将数据读取到buffer容器中
output("调用read()", buffer);
// 准备操作之前,先锁定操作范围:
buffer.flip();
output("调用flip()", buffer);
// 判断有没有可读数据
while (buffer.remaining() > 0){
byte b = buffer.get();
}
output("调用get()", buffer);
// 可以理解为解锁
buffer.clear();
output("调用clear()", buffer);
// 最后把管道关闭
fileInputStream.close();
}
/**
* 将缓冲区里的实时状态打印出来
*
* @param step
* @param buffer
*/
public static void output(String step, Buffer buffer) {
System.out.println(step + " : ");
// 容量(数组大小):
System.out.print("capacity" + buffer.capacity() + " , ");
// 当前操作数据所在的位置,也可以叫做游标:
System.out.print("position" + buffer.position() + " , ");
// 锁定值,flip,数据操作范围索引只能在 position - limit 之间:
System.out.println("limit" + buffer.limit());
System.out.println();
}
}
输出结果如下:
初始化 :
capacity10 , position0 , limit10
调用read() :
capacity10 , position4 , limit10
调用flip() :
capacity10 , position0 , limit4
调用get() :
capacity10 , position4 , limit4
调用clear() :
capacity10 , position0 , limit10
下面我们来对上面代码的执行结果进行图解分析(围绕position、limit、capacity三个字段值):

// 分配一个容量为10的缓冲区(本质上就是一个容量为10的byte数组)
ByteBuffer buffer = ByteBuffer.allocate(10);
// 从管道将数据读取到buffer容器中
channel.read(buffer);
output("调用read()", buffer);
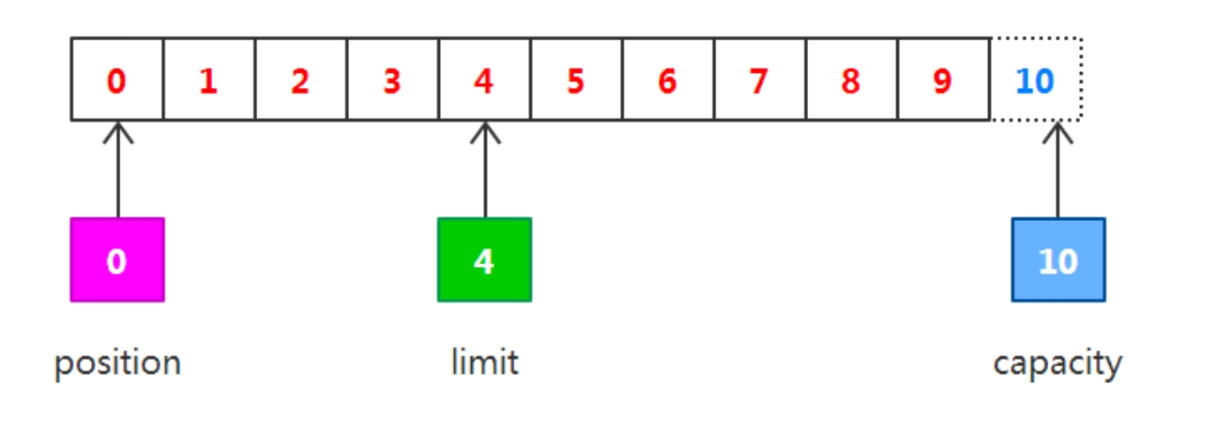
首先从通道中读取一些数据到缓冲区中(注意从通道读取数据,相当于往缓冲区写入数据)。如果读取4个字节的数据,则此时 position的值为4,即下一个将要被写入的字节索引为4,而limit仍然是10,如下图所示。

// 准备操作之前,先锁定操作范围:
buffer.flip();
output("调用flip()", buffer);
下一步把读取的数据写入输出通道,相当于从缓冲区中读取数据,在此之前,必须调用flip()方法。该方法将会完成以下两件事情:
- 一是把limit设置为当前的position值。
- 二是把position设置为 0。
由于position被设置为0,所以可以保证在下一步输出时读取的是缓冲区的第一个字节,而limit被设置为当前的position,可以保证读取的数据正好是之前写入缓冲区的数据,如下图所示。
// 判断有没有可读数据
while (buffer.remaining() > 0){
byte b = buffer.get();
}
output("调用get()", buffer);
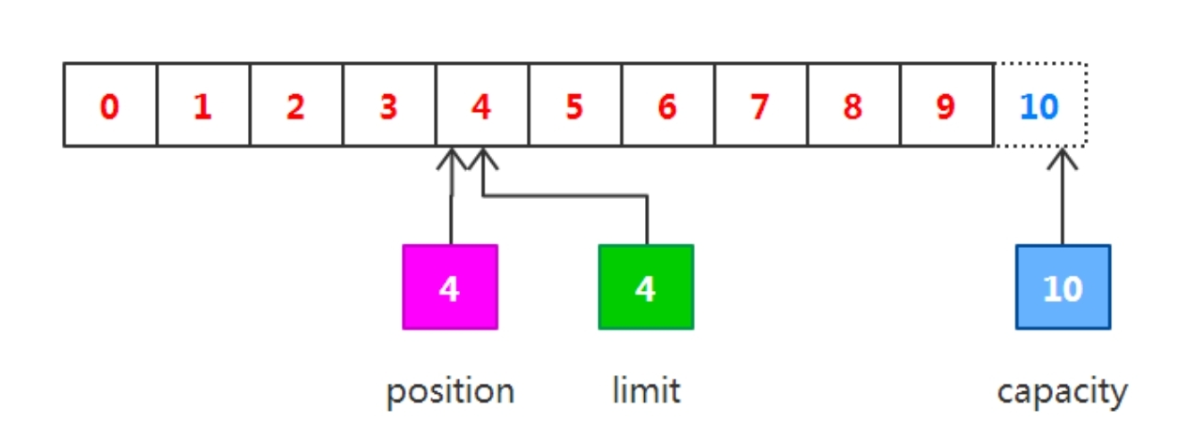
调用get()方法从缓冲区中读取数据写入输出通道,这会导致 position的增加而limit保持不变,但position不会超过limit的值, 所以在读取之前写入缓冲区的4字节之后,position和limit的值都为 4,如下图所示。
// 可以理解为解锁
buffer.clear();
output("调用clear()", buffer);
// 最后把管道关闭
fileInputStream.close();
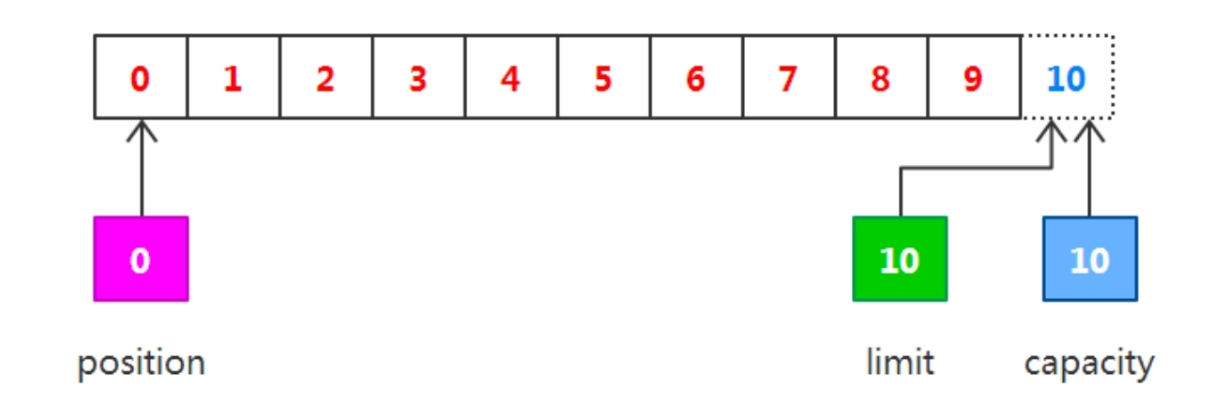
在从缓冲区中读取数据完毕后,limit的值仍然保持在调用flip()方法时的值,调用clear()方法能够把所有的状态变化设置为初始化时的值,最后关闭流,如下图所示。
通过上述案例,更能突出Buffer是一个特殊的数组容器,与普通数组区别就在于其内置三个 “指针变量”:position、limit、capacity 用于跟踪和记录缓冲区的状态变化情况!
4、allocate方法初始化一个指定容量大小的缓冲区
在创建一个缓冲区对象时,会调用静态方法allocate()来指定缓冲区的容量,其实调用allocate()方法相当于创建了一个指定大小的数组,并把它包装为缓冲区对象。
allocate()源码如下:
// 位于ByteBuffer下
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
// 新建一个ByteBuffer数组对象,容量为:capacity,limit参数值为:capacity
return new HeapByteBuffer(capacity, capacity);
}
// 位于HeapByteBuffer下,父类为:ByteBuffer
HeapByteBuffer(int cap, int lim) {
super(-1, 0, lim, cap, new byte[cap], 0);// 调用ByteBuffer的有参构造函数
}
// 位于ByteBuffer下,父类为:Buffer
ByteBuffer(int mark, int pos, int lim, int cap,
byte[] hb, int offset){
super(mark, pos, lim, cap);// 调用 Buffer构造函数
this.hb = hb;// final byte[] hb; 不可变的byte数组
this.offset = offset;// 偏移量
}
// Buffer构造函数
Buffer(int mark, int pos, int lim, int cap) {
if (cap < 0)
throw new IllegalArgumentException("Negative capacity: " + cap);
this.capacity = cap;// 数组容量
limit(lim);// 数组的了limit
position(pos);// 数组的positio
if (mark >= 0) {
if (mark > pos)
throw new IllegalArgumentException("mark > position: ("
+ mark + " > " + pos + ")");
this.mark = mark;
}
}
本质上等同于如下代码:
// 初始化一个byte数组
byte[] bytes = new byte[10];
// 将该数组包装给ByteBuffer
ByteBuffer buffer = ByteBuffer.wrap(bytes);
5、slice方法缓冲区分片
Java NIO中,可以根据先用的缓冲区Buffer对象创建一个子缓冲区。即,在现有缓冲区上切出一片作为一个新的缓冲区,但现有的缓冲区与创建的子缓冲区在底层数组层面上是数据共享的。
示例代码如下所示:
/**
* @author csp
* @date 2021-11-28 6:20 下午
*/
public class BufferSlice {
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(10);
// 向缓冲区中put数据: 0~9
for (int i = 0; i < buffer.capacity(); i++) {
buffer.put((byte) i);
}
// 创建子缓冲区:即从数组下标为3的位置到下标为7的位置
buffer.position(3);
buffer.limit(7);
ByteBuffer slice = buffer.slice();
// 改变子缓冲区的内容
for (int i = 0; i < slice.capacity(); i++) {
byte b = slice.get(i);
b *= 10;
slice.put(i, b);
}
// position和limit恢复到初始位置:
buffer.position(0);
buffer.limit(buffer.capacity());
// 输出buffer容器中的内容:
while (buffer.hasRemaining()) {
System.out.println(buffer.get());
}
}
}
在该示例中,分配了一个容量大小为10的缓冲区,并在其中放入 了数据0~9,而在该缓冲区基础上又创建了一个子缓冲区,并改变子缓冲区中的内容,从最后输出的结果来看,只有子缓冲区“可见的” 那部分数据发生了变化,并且说明子缓冲区与原缓冲区是数据共享 的,输出结果如下所示:
0
1
2
30
40
50
60
7
8
9
6、只读缓冲区
只读缓冲区,顾名思义就是只可以从缓冲区中读取数据,而不可以向其中写入数据。
将现有缓冲区让其调用asReadOnlyBuffer()方法,使其转换成只读缓冲区。这个方法返回一个与原缓冲区完全相同的缓冲区,并与原缓冲区共享数据,只不过它是只读的。如果原缓冲区的 内容发生了变化,只读缓冲区的内容也随之发生变化。
示例代码如下所示:
/**
* @author csp
* @date 2021-11-28 6:33 下午
*/
public class ReadOnlyBuffer {
public static void main(String[] args) {
// 初始化一个容量为10的缓冲区
ByteBuffer buffer = ByteBuffer.allocate(10);
// 向缓冲区中put数据: 0~9
for (int i = 0; i < buffer.capacity(); i++) {
buffer.put((byte) i);
}
// 将该缓冲区转变为只读缓冲区
ByteBuffer readOnlyBuffer = buffer.asReadOnlyBuffer();
// 由于buffer和readOnlyBuffer本质上共享一个byte[]数组对象,
// 所以,改变buffer缓冲区的内容时,会导致只读缓冲区readOnlyBuffer的内容也随着改变。
for (int i = 0; i < buffer.capacity(); i++) {
byte b = buffer.get(i);
b *= 10;
buffer.put(i, b);
}
// position和limit恢复到初始位置:
readOnlyBuffer.position(0);
readOnlyBuffer.limit(buffer.capacity());
// 输出readOnlyBuffer容器中的内容:
while (readOnlyBuffer.hasRemaining()) {
System.out.println(readOnlyBuffer.get());
}
}
}
输出结果如下:
0
10
20
30
40
50
60
70
80
90
如果尝试修改只读缓冲区的内容,则会报 ReadOnlyBufferException异常。只可以把常规缓冲区转换为只读缓冲区,而不能将只读缓冲区转换为 可写的缓冲区。
7、直接缓冲区
参考文章:Java NIO学习篇之直接缓冲区和非直接缓冲区
对于直接缓冲区的定义,《深入理解Java虚拟机》这本书是这样介绍的:
- Java NIO字节缓冲区(ByteBuffer)要么是直接的,要么是非直接的。如果为直接字节缓冲区,则java虚拟机会尽最大努力直接在此缓冲区上执行本机的IO操作,也就是说,在每次调用基础操作系统的一个本机IO操作前后,虚拟机都会尽量避免将内核缓冲区内容复制到用户进程缓冲区中,或者反过来,尽量避免从用户进程缓冲区复制到内核缓冲区中。
- 直接缓冲区可以通过调用该缓冲区类的
allocateDirect(int capacity)方法创建,此方法返回的缓冲区进行分配和取消分配所需的成本要高于非直接缓冲区。直接缓冲区的内容驻留在垃圾回收堆之外,因此他们对应用程序内存(JVM内存)需求不大。所以建议直接缓冲区要分配给那些大型,持久(就是缓冲区的数据会被重复利用)的缓冲区,一般情况下,最好仅在直接缓冲区能在程序性能带来非常明显的好处时才分配它们。 - 直接缓冲区还可以通过FileCHannel的
map()方法将文件区域映射到内存中来创建,该方法返回MappedByteBuffer。Java平台的实现有助于通过JNI本地代码创建直接字节缓冲区,如果以上这些缓冲区中某个缓冲区实例指向的是不可访问的内存区域,则试图方法该区域不会更改缓冲区的内容,并且会在访问期间或者稍后的某个时间导致报出不确定性异常。 - 字节缓冲区是直接缓冲区还是非直接缓冲区可以通过调用其
isDIrect()方法来判断。
案例代码:
/**
* @author csp
* @date 2021-11-28 7:07 下午
*/
public class DirectBuffer {
public static void main(String[] args) throws IOException {
// 从磁盘中读取test.txt文件内容
FileInputStream fileInputStream = new FileInputStream("/Users/csp/IdeaProjects/netty-study/test.txt");
// 创建文件的操作管道
FileChannel inputStreamChannel = fileInputStream.getChannel();
// 把读取的内容写入到新的文件中
FileOutputStream fileOutputStream = new FileOutputStream("/Users/csp/IdeaProjects/netty-study/test2.txt");
FileChannel outputStreamChannel = fileOutputStream.getChannel();
// 创建直接缓冲区
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(1024);
while (true){
byteBuffer.clear();
int read = inputStreamChannel.read(byteBuffer);
if (read == -1){
break;
}
byteBuffer.flip();
outputStreamChannel.write(byteBuffer);
}
}
}
要分配 直接缓冲区,需要调用allocateDirect()方法,而不是allocate()方 法,使用方式与普通缓冲区并无区别。
8、内存映射
内存映射是一种读和写文件数据的方法,可以比常规的基于流或者基于通道的I/O快得多。内存映射文件I/O通过使文件中的数据表现为内存数组的内容来完成,这初听起来似乎不过就是将整个文件读到内存中,但事实上并不是这样的。一般来说,只有文件中实际读取或 写入的部分才会映射到内存中。来看下面的示例代码:
/**
* @author csp
* @date 2021-11-28 7:16 下午
*/
public class MapperBuffer {
static private final int start = 0;
static private final int size = 10;
public static void main(String[] args) throws IOException {
RandomAccessFile randomAccessFile = new RandomAccessFile("/Users/csp/IdeaProjects/netty-study/test.txt", "rw");
FileChannel channel = randomAccessFile.getChannel();
// 把缓冲区跟文件系统进行一个映射关联,只要操作缓冲区里面的内容,文件内容也会随之改变
MappedByteBuffer mappedByteBuffer = channel.map(FileChannel.MapMode.READ_WRITE, start, size);
mappedByteBuffer.put(4, (byte) 97);// a
mappedByteBuffer.put(5, (byte) 122);// z
randomAccessFile.close();
}
}
原来test.txt文件内容为:
Java
执行完上述代码之后,test.txt文件内容更新为:
Javaaz
以上就是Java NIO Buffer实现原理详解的详细内容,更多关于Java NIO Buffer的资料请关注其它相关文章!
以上是 Java NIO Buffer实现原理详解 的全部内容, 来源链接: utcz.com/p/251199.html