MapReduce切片机制及执行流程

MapReduce的切片机制
在Map阶段会将读取进来的数据进行逻辑切片进行处理。
此切片与HDFS的切块不同,HDFS的切块是将文件按照block块的形式保存起来,mr则是将文件按照切片数进行计算
默认切片大小等于块大小,也就是128m切一片,切片数与MapTask的数量是一致的,MapTask的并行度是由客户端提交Job时的切片数决定的
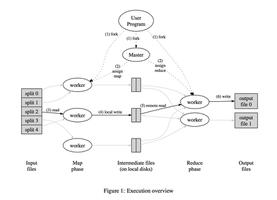
MR的执行流程
MapTask阶段 可以分为五个阶段
Read阶段:MapTask根据用户编写的Reader从中解析出一个key/vaule
Map阶段:将读取到的key/value交给用户编写的 map函数进行处理,然后产生新的key/value
Clooect收集阶段:当数据通过map函数处理过后会调用context.write此函数会将生成的key/value进行分区(调用Partition),
***(partiton可以自定义分区,也可以使用默认的分区器HashPartition,默认的分区器会按照我们设置的reduceTask的数量进行分区
也就是如果只设置了一个reduceTask就只会有一个分区,如果分区数不是1而reduceTask是1的话,不会执行分区
因为MapTask执行分区依据是先判断reduceTask的数量)***
并且写入一个环形缓冲区当中。
Spill阶段:即溢写阶段,当环形缓冲区达到80%后会对数据进行溢写,此时会对产生的小文件内部进行一次快排保证每个小文件的内部是有序的,
并在必要时对数据进行合并等操作。
Combine阶段:当所有的数据全都溢写到磁盘后会按照分区对每个分区内的所有小文件进行一次归并排序来形成一个大文件
shuffle阶段
从Map端开始对解析后的key/value进行分区到Reduce端对分区文件进行合并(归并排序)的过程叫做 shuffle。
shuffle的过程总共经过三次排序:
第一次排序是在Map端的环形缓冲区向磁盘刷写内容时,对小文件内的内容进行排序。
第二次排序是在Map端对环形缓冲区刷写出来的所有小文件进行合并,为归并排序。
第三次排序是在Reduce段按照分区对分区内文件进行合并,为归并排序。
Reduce和Combiner
combiner是MR程序中Mapper和Reducer之外的一种组件。
combiner组件的父类就是Reducer
combiner和reducer的区别在于运行的位置:
conbiner:conbiner是在每一个MapTask所在的节点进行运行,用于局部合并
Reducer:reducer是接收全局所有Mapper的输出结果,用于全局合并
combiner的意义就是对每一个maptask的输出进行局部汇总,以减小网络传输量。
并非所有的mr程序都可以使用combiner。combiner能够应用的前提是不能影响最终的业务逻辑,而且,combiner的输出kv应该跟reducer的输入kv类型要对应起来。
以上是 MapReduce切片机制及执行流程 的全部内容, 来源链接: utcz.com/z/536324.html