MapReduce工作流程

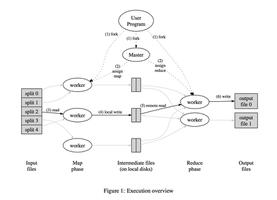
MapReduce工作流程图
流程详解(重点)
MapTask
- 待处理的文本通过submit()方法,获取待处理的数据信息,然后根据InputFormat切片方法机制,生成切片方法文件。把切片方法文件和资源配置文件全部提交在资源路径。提交的信息有:Job.split、wc.jar、Job.xml
- 把资源提交路径下的信息文件提交给YARN集群或者本地内存中,之后YARN集群根据提交的信息启动Mr appmaster主机
- Mr appmaster根据提交的切片规划机制计算出MapTask的数量,生成对应的MapTask任务。
- MapTask任务根据Mr appmaster分配的数据量,去原始文件当中读取相应切片的数据。读取数据需要借助InputFormat中定义的 RecordReader(如果没有定义,则会默认使用TextInputFormat)进行切片
- 如果使用默认切片方法,则每读取一行,在Mapper类中进行逻辑运算,即通过获取到的key-value值确定文件传到Reduce类中的key-value值
- 逻辑运算完成后,通过Context.write(k,v)方法进行数据传输。此时先将结果(<k,v>数据)写入到一个环形缓冲区,在这个环形缓冲区中一分为二,从右侧的缓冲区开始写入数据(<k,v>键值对),从左侧开始写入数据的索引。
- 在往环形缓冲区写入数据的过程中,不仅要写入数据的索引,还需要写出数据所在分区(MapReduce中分区默认有一个,也可以指定多个分区)。在声明了所在的分区之后,要对<k,v>键值对进行排序。排序不是每时每刻进行的,是在数据写入完成,或者数据往磁盘溢写的时候,要进行一次排序
- 当内存已存入80%时,将环形缓冲区中的数据溢写到磁盘中,并将缓冲区中的数据清空,之后在反向写入数据和索引(顺时针改为逆时针/逆时针改为顺时针)。如果数据过多,会进行多次溢写,溢写时根据分区溢写,并且每个分区内的数据是有序的
- 对溢写文件通过Merge进行归并排序,之后通过Combiner对数据进行合并
ReduceTask
- MapTask数据处理完成之后,将数据写入缓冲区分区或者磁盘中去,磁盘中存储的文件信息与缓冲区存储的文件信息相同,都有<k,v>键值对及其分区和索引。
- 在所有的MapTask任务完成后,Mr appmaster做出响应。Mr appmaster根据MapTask输入的分区数确定ReduceTask的数量
- 之后Mr appmaster启动相应数量的ReduceTask,并告知ReduceTask处理数据的范围(数据分区),一个分区需要有一个ReduceTask处理数据。ReduceTask1处理partition 1的数据,ReduceTask2处理partition2的数据……
- ReduceTask将MapTask中相应分区中的数据下载到ReduceTask本地磁盘中,并将文件进行合并,之后再对文件中的数据进行归并排序
- 通过GroupingComparator(k,knext)方法对文件进行分组,之后将key值相同的数据调用Reduce(k,v)方法,一次读取一组
- 通过OutPutFormat将数据输入到结果文件中(默认调用TextOutPutFormat)。如果有多个ReduceTask,则写入到多个输出文件中
Shuffle
- maptask收集我们的map()方法输出的kv对,放到内存缓冲区中
- 从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
- 多个溢出文件会被合并成大的溢出文件
- 在溢出过程中及合并的过程中,都要调用partitioner进行分区和针对key进行排序
- reducetask根据自己的分区号,去各个maptask机器上取相应的结果分区数据
- reducetask会取到同一个分区的来自不同maptask的结果文件,reducetask会将这些文件再进行合并(归并排序)
- 合并成大文件后,shuffle的过程也就结束了,后面进入reducetask的逻辑运算过程(从文件中取出一个一个的键值对group,调用用户自定义的reduce()方法)
总结
- MR流程总共分为四个阶段:
- submit阶段:切片job.split和配置项信息job.xml形成文件提交到一个资源路径,然后通过YARN启动运行
- MapTask任务处理阶段:读取切片数据、处理切片数据
- Shuffle阶段(MapTask任务执行结束到ReduceTask任务执行之前):MapTask写出数据到环形缓冲区、分区、排序、溢写文件……
- ReduceTask任务处理阶段:读取环形缓冲区数据、读取溢写文件数据、reduce运算逻辑、输出结果到输出文件
- 注意:
Shuffle中的缓冲区大小会影响到mapreduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快。
缓冲区的大小可以通过参数调整,参数:io.sort.mb 默认100M
以上是 MapReduce工作流程 的全部内容, 来源链接: utcz.com/z/535817.html