一个艺术风格化的神经网络算法

效果图
快读

a 图的 style 和 p 图的 content 进行融合,得到第三幅图 x

代价函数 Loss
正文

对于好的艺术,尤其是画作,人们掌握了通过在内容和风格中构成复杂的影响来创造独特的视觉体验的技能。因此这个过程的算法基础是未知的而且不存在任一人工系统有同样的能力。但是,在其他基于视觉概念的关键领域,比如说接近于人类表现的物体和脸部识别最近已由一系列仿生的称为深度神经网络的视觉模型做到了。
在这时我们介绍一种其于深度神经网络的人工系统,它可以生成具有高感知品质的艺术图片.这个系统使用了神经的表达来分离并且再结合任意图片的内容和风格,为生成艺术图片提供了一个神经算法.而且,按照要去表现最优的人工神经网络和生物视觉中找到相同.我们的工作提供了人类是怎样创作和认知艺术图像的算法理解。
处理图像任务最有效的深度神经网络是卷积神经网络。卷积神经网络由几层小的在前馈中分层处理视觉信息的可计算单元组成。每一层单元都可以被理解为一个图片过滤器的集合(collection),每一个从中提取特定的特征。因此,一个给定的层的输出包括我们称为特征谱(map):输入图片的不同的被过滤的版本。
当卷积网络在物体识别上被训练时,它们生成了一种对于图片的表达,能够沿着层次使特征的信息不断(increasingly)明确。因此,沿着网络的层次,这个输入图片被转化为的呈现越来越关注实际的图片内容,对比于它具体的像素值。我们可以直接可视化每层包括的关于输入图片的信息,通过只重构该层的特征图谱。网络的更高层捕捉了物体在高层的内容和在输入图片的应用,但是不含重构的精确的像素值。与此相反,从更低的层次的重构简单地重新生成了原始图像的具体像素值。
我们因此参考了网络高层的特征反应作为内容表现。为了获取一个输入图片的风格表现,我们使用了一个特征空间被原始地设计来捕获纹理信息。这个特征空间是建立在网络每一层的过滤器的响应(response)上的。它由空间范围内的特征图谱不同的过滤响应间的联系组成(细节看method部分)。通过包括多层的特征关联,我们获得了一个固定的(stationry),多层规模的对于输入图片的陈述,这个表现可以捕获宽的纹理信息而不是全局的应用(arrangement)。
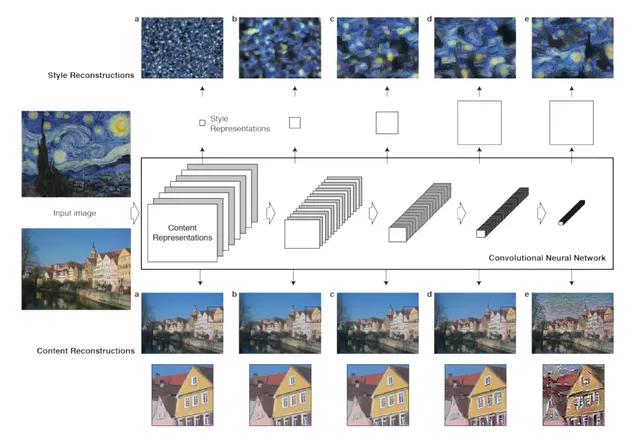
图像1 :卷积神经网络(CNN)
一个给定的输入图像由一个被过滤过的存在于卷积网络各个处理过程中的图像集呈现。当不同的过滤器的数量沿着处理的层次增长时,过滤后图像的大小被一些下采样机制减小,导致了在网络每一层的单元总数的减小。
内容重构。我们可以通过从一个已知特定层的网络的响应重构输入图片来可视化CNN中不同处理层的信息。我们重构了输入图像从VGG的‘conv1 1’ (a), ‘conv2 1’ (b), ‘conv3 1’ (c), ‘conv4 1’ (d) and
‘conv5 1’ (e)。发现从较低层重构的几乎可以称完美(a,b,c)。在网络的较高层,具体的像素值信息在更高层次的内容被保存的时候丢失了(d,e)。
风格重构。在原始的CNN的最高层我们建立了一个新的特征空间来捕获输入图片的风格。风格表现计算了CNN不同层中不同特征的联系。我们重构了输入图像的风格,建立在以下CNN层的子集( ‘conv1 1’ (a), ‘conv1 1’ and ‘conv21’ (b), ‘conv1 1’, ‘conv2 1’ and ‘conv3 1’ (c), ‘conv1 1’, ‘conv2 1’, ‘conv3 1’ and ‘conv4 1’ (d), ‘conv1 1’, ‘conv2 1’, ‘conv3 1’, ‘conv4 1’ and ‘conv5 1’ (e))。这创作的图像在增长的规模上符合了给定图像的风格,同时丢弃了全局的场景应用的信息。
再一次,我们可以通过重构一个可以符合(match)输入图风格表现的图像来可视化由在网络不同层风格特征空间捕获的信息(图1,风格重构)。事实上从风格特征重建产生的纹理化的输入图片,捕获了它依照颜色和局部结构捕获的外观。而且,沿着处理的层次,输入图片局部的图片结构的大小和复杂性增加,这可以解释为增长的感受野的大小和特征的复杂性。我们参考了多层的呈现现作为风格表达。
这篇论文的关键发现在于风格和内容在卷积神经网络中的表达是可以分开的。也就是说,我们可以独立地操纵两种表达来产生新的、可以感受的有意义的图片。为了展示这个发现,我们生成了一些混合了不同源图片的内容和风格表现的图片。特别的,我们匹配了一张照片描绘 the “Neckarfront” in Tubingen, Germany和一张几个不同时期的有名的艺术作品作为风格。
这类图片是发现一张和照片的内容表现和各自的艺术作品的风格表现两相匹配的图片合成的(图2)。

这些图片是通过寻找一个同时匹配照片的内容表现和各类艺术的图片合成的(see method for details)。在原始照片的全局布置被保留的同时,构成全局景色的颜色和局部结构则由艺术作品提供.实际上,它把照片渲染成了艺术作品的风格,比如说合成图片的表现类似于艺术作品,尽管它的内容和照片相同。
正如概述所言,风格表现是一个多层次的表达,包括了多层神经网络.在我们在图2中展示的图片那样,这个风格表现包括了整个神经网络结构的各个层次.风格也可以被定义为更为局部化,因为它只包含了少量的低层结构,这些结构能产生不同的视觉效果(图2,along the rows).当风格表现匹配到网络的更高层时,局部的图片结构会逐渐在大的尺寸上匹配,产生了一个更平滑更连续的视觉体验.因此,视觉上更有感染力的图片通常是由风格表现匹配到更高层网络的方法产生的(图2,last row).
当然,图片内容和风格不能被完全分离.当合成一张结合了某张图片的内容和另一张图片的风格时,通常不存在一个图片能同时完美的匹配这两张图片.然而,这个我们在合成过程中要最小化的loss函数包含了我们很好分离开的两个方面,内容和风格(see method).因此我们可以平滑地调节在重构内容或者是风格时的重点(图3,along the columns).着重强调风格产生的图片可以匹配艺术作品的表现,实际上也就是给了一个纹理化的版本,但是几乎不能表现任何照片的内容(图 3,first column).当把比重放在内容上时,结果可以很清晰得确认到照片,但是画作的风格就不能很好地匹配(图3,last column).对于一对特定的源图片我们可以调节在内容和风格间的协调来产生视觉上有感染力的图片.

图3:合成 *Composition VII * by Wassily Kandinsky的风格的细节结果.每一行展示的结果,要匹配的风格表现用到的CNN的子集层数逐渐增加(see Methods).我们发现由风格表现捕获的局部的图片结构的大小和复杂性随着包括了更高的网络层次增加.这可以解释为是由于沿成网络处理的结构感受域的大小和特征复杂性增加.每一列展示了在内容和风格上取不同的相关权值的结果.每一列上方的数值指示了比值a/b(alpha/beta).
在这里我们展示了一个可以达到分离图片内容和风格的人工神经网络,因此它也可以用另一个图片的风格改写某张图片的内容.我们通过生成新的,艺术化的结合了一些有名的画作的风格和任意选定的照片的内容的合成图片来展示.特别的,我们推导出图片的内容和风格在神经网络中的表现的特征响应为了物体识别而训练的表现很好的深度神经网络.就我们所知,这是把整个自然图片的风格和内容的图片特征分开的首次展示.之前的在分离图片内容和风格上的工作所评估的图片的输入要简单很多,比如说不同的手写单词或者是人脸或者是不同姿势的小图片.
在我们的展示中,我们提供了一个在不同的有名的艺术作品风格下的给定图片.这个问题通常是由计算机视觉中的被称为相片拟真处理技术(photorealistic rendering)的方法研究的.在概念上更相关的方法使用了纹理转化来达到艺术风格转换.与此相反,通过使用为了物体识别训练的深度神经网络,我们在特征空间中使用的手法清楚得表现了图片高层的内容。
从为了物体识别训练的深度神经网络中提取的物征已经被应用到风格识别上来根据艺术作品产生的时期分类.那里,分类器是由原始的网络激活层训练的,我们将其称为内容表现.我们猜测向一个固定的特征空间的转化比如说我们的风格表现或许可以在风格分类上有一个更好的表现。
一般来说,我们合成图片的方法,混合了不同来源的内容和风格,提供了一个新的,有趣的工具来学习感知和艺术,风格和内容独立的图片通常的神经表现。
我们可以设计新颖的激励(novel stiluli(?))来介绍两个独立的,感官上有意义的变体的源:图的表现(appearance)和内容.我们想像这可能对于很多关于视觉感知的研究都会很有意义,范围从心理物理学(psychophysics)的功能影像到电生理学(electrophysiological)的神经记录.事实上,我们的工作提供了一个神经表达是怎样独立得捕获图片的内容和它被表达的风格的算法理解.重要的是,我们的风格表达的数学形式生成了一个清楚的,可检验的层次结构关于图现外观的表现,一直细微到一个神经元的层次.这个风格的表现简单地计算了在网络中不同种神经元的相互关系.提取的不同神经元间的相互关系是一种生物上可信的计算,也就是说,比如,由主要视觉系统中被称为的复杂细胞来执行.我们的结果表明了表现一个复杂细胞像沿着腹侧流(ventral stream)的不同处理过程的计算是一个可能的获得一个视觉输入的外观的内容独立的表达的方法.
总而言之一个被训练来处理一个生物视觉的核计算任务的神经系统,自动地学习允许图片内容和风格分离是很神奇的.或许可以这样解释,当学习物体识别时,这个网络变得对于所有的保留物体特征的图片变量都保持不变.因此,our ability to abstract content from style and therefore our ability to create and enjoy art might be primarily a preeminent(优秀的) signature of the powerful inference(推理)
capabilities of our visual system.
Method
在正文中展示的结果是以VGG网络为基础产生的,一个在一般视觉物体识别的基准任务上可以和人类表现对抗的卷积神经网络,并且被大量地应用.我们使用由VGG19中的16个卷积层和5个池化层特征空间.我们不需要使用任何全连接层.这个模型公开可用而且可以在caffe框架中找到.为了图片合成我们用平均池化替代了最大池化来改进梯度流而且可以获得稍微更有感染力的结果.
事实上网络的每一层都定义了一个非线性的过滤器组,它的复杂性随着在网络中所在层的位置而增加.因此一个给定的输入图片x在CNN的每一层的编码的过滤器是响应图片的.一个有着Nl个不同的过滤器的层有Nl个特征图谱,每个图谱的大小Ml,Ml是特征图谱的长与宽的乘积.所以对于层L的响应可以被存储在矩阵中Fl中,Fij表示第i个过滤器在层L中的第j个位置的激活.为了可视化由不同层次编码的图片信息(图1,内容重构)我们对一个白噪声图片进行坡度下降来找到另外一张可以匹配原图的特征反应的图片.

根据这个式子关于图片x的梯度可以用标准差反向传播计算出来.因此我们可以改变原始的随机图片x直到它在特定的CNN的某层生成了和原始图片P相同的响应. The five content reconstructions in Fig 1 are from layers ‘conv1_1’ (a), ‘conv2_1’ (b), ‘conv3_1’ (c), ‘conv4_1’ (d) and ‘conv5_1’(e) of the original VGG-Network.
在CNN的顶端对网络每层的响应我们建立了一个风格表达来计算不同的过滤器响应间的相互联系,期望是接办输入图的空间扩展(taken over the spatial extend of the input image).这些特征间的相互联系是由Gram矩阵计算的,其中Gij(l)是向量化(vectorised)特征图谱i和j在层l上的内积:
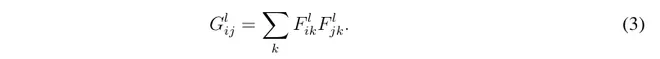
为了生成一个匹配给定图片的纹理(图1,风格重构),我们从一个白噪声图梯度下降,找到一张与原始图片的风格匹配的图片.这是通过最小化原始图片的Gram矩阵和待生成图片的Gram矩阵之间的平均方差做到的.

在这里wl是每一层在total loss中所占的权值.El的导数可以用解析的方法计算出来:
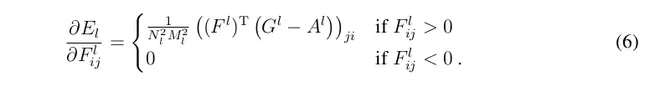
El在更低层的导数可以很轻易地用标准差反向传播计算出来.图1中五个风格的重构是通过匹配在‘conv1_1’ (a), ‘conv1_1’ and ‘conv2_1’(b), ‘conv1_1’, ‘conv2_1’ and ‘conv3_1’(c),‘ conv1_1’, ‘conv2_1’, ‘conv3_1’ and ‘conv4_1’ (d),‘conv1_1’, ‘conv2_1’, ‘conv3_1’, ‘conv4_1’ and ‘conv5_1’ (e)的风格表现生成的.
为了生成混合了照片的内容和画作的风格的图片,我们共同最小化了白噪声在网络某一层到照片的内容表达的距离以及在CNN网络多层上到风格表达的距离.我们最小化的loss function是


References and Notes
- Krizhevsky, A., Sutskever, I. & Hinton, G. E. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, 1097–1105(2012). URL http://papers.nips.cc/paper/4824-imagenet.
- Taigman, Y., Yang, M., Ranzato, M. & Wolf, L. Deepface:
Closing the gap to human-level performance in face verification. In Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on, 1701–1708 (IEEE, 2014). URL http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=6909616.
- G ̈uc ̧l ̈u, U. & Gerven, M. A. J. v. Deep Neural Networks Reveal a Gradient in the Complexity of Neural Representations across the Ventral Stream. The Journal of Neuroscience 35, 10005–10014 (2015). URL http://www.jneurosci.org/content/35/27/10005.
- Yamins, D. L. K. et al. Performance-optimized hierarchical models predict neural responses in higher visual cortex. Proceedings of the National Academy of Sciences 201403112 (2014). URL http://www.pnas.org/content/early/2014/05/08/1403112111.
- Cadieu, C. F. et al. Deep Neural Networks Rival the Representation of Primate IT Cortex for Core Visual Object Recognition.
PLoS Comput Biol 10, e1003963 (2014). URL http://dx.doi.org/10.1371/journal.pcbi.1003963.
- K ̈ummerer, M., Theis, L. & Bethge, M. Deep Gaze I: Boosting Saliency Prediction with Feature Maps Trained on ImageNet. In ICLR Workshop (2015). URL /media/publications/1411.1045v4.pdf.
- Khaligh-Razavi, S.-M. & Kriegeskorte, N. Deep Supervised, but Not Unsupervised, Models May Explain IT Cortical Representation. PLoS Comput Biol 10, e1003915 (2014). URL
http://dx.doi.org/10.1371/journal.pcbi.1003915.
- Gatys, L. A., Ecker, A. S. & Bethge, M. Texture synthesis and the controlled generation of natural stimuli using convolutional neural networks. arXiv:1505.07376 [cs, q-bio] (2015). URL http://arxiv.org/abs/1505.07376. ArXiv: 1505.07376.
- Mahendran, A. & Vedaldi, A. Understanding Deep Image Representations by Inverting Them. arXiv:1412.0035 [cs] (2014). URL http://arxiv.org/abs/1412.0035. ArXiv: 1412.0035.
- Heeger, D. J. & Bergen, J. R. Pyramid-based Texture Analysis/Synthesis. In Proceedings of the 22Nd Annual Conference on Computer Graphics and Interactive Techniques, SIGGRAPH ’95, 229–238 (ACM, New York, NY, USA, 1995). URL http://doi.acm.org/10.1145/218380.218446.
- Portilla, J. & Simoncelli, E. P.A Parametric Texture Model Based on Joint Statistics of Complex Wavelet Coefficients. International Journal of Computer Vision 40, 49–70 (2000). URL http://link.springer.com/article/10.1023/A%3A1026553619983.
- Tenenbaum, J. B. & Freeman, W. T. Separating style and content with bilinear models. Neural computation 12, 1247–1283 (2000).
URL http://www.mitpressjournals.org/doi/abs/10.1162/089976600300015349.
- Elgammal, A. & Lee, C.-S. Separating style and content on a nonlinear manifold. In Computer Vision and Pattern Recognition, 2004.
CVPR 2004. Proceedings of the 2004 IEEE Computer Society Conference on, vol. 1, I–478 (IEEE, 2004). URL http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=1315070.
- Kyprianidis, J. E., Collomosse, J., Wang, T. & Isenberg, T.
State of the ”Art”: A Taxonomy of Artistic Stylization Techniques for Images and Video. Visualization and Computer 14Graphics, IEEE Transactions on 19, 866–885 (2013). URL http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=6243138.
- Hertzmann, A., Jacobs, C. E., Oliver, N., Curless, B. & Salesin, D. H. Image analogies. In Proceedings of the 28th annual conference on Computer graphics and interactive techniques, 327–340 (ACM, 2001). URL http://dl.acm.org/citation.cfm?id=383295.
- Ashikhmin, N. Fast texture transfer. IEEE Computer Graphics and Applications 23, 38–43(2003).
- Efros, A. A. & Freeman, W. T. Image quilting for texture synthesis and transfer. In Proceedings of the 28th annual conference on Computer graphics and interactive techniques, 341–346 (ACM, 2001). URL http://dl.acm.org/citation.cfm?id=383296.
- Lee, H., Seo, S., Ryoo, S. & Yoon, K. Directional Texture Transfer. In Proceedings of the 8th International Symposium on Non-Photorealistic Animation and Rendering, NPAR ’10, 43–48 (ACM, New York, NY, USA, 2010). URL http://doi.acm.org/10.1145/1809939.1809945.
- Xie, X., Tian, F. & Seah, H. S. Feature Guided Texture Synthesis (FGTS) for Artistic Style Transfer. In Proceedings of the 2Nd International Conference on Digital Interactive Media in Entertainment and Arts, DIMEA ’07, 44–49 (ACM, New York, NY, USA, 2007). URL http://doi.acm.org/10.1145/1306813.1306830.
- Karayev, S. et al. Recognizing image style. arXiv preprint arXiv:1311.3715 (2013). URL http://arxiv.org/abs/1311.3715.
- Adelson, E. H. & Bergen, J. R. Spatiotemporal energy models for the perception of motion. JOSA A 2, 284–299 (1985). URL http://www.opticsinfobase.org/josaa/fulltext.cfm?uri=josaa-2-2-284.
- Simonyan, K. & Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv:1409.1556 [cs] (2014). URL http://arxiv.org/abs/1409.1556. ArXiv: 1409.1556.
- Russakovsky, O. et al. ImageNet Large Scale Visual Recognition Challenge. arXiv:1409.0575 [cs] (2014). URL http://arxiv.org/abs/1409.0575. ArXiv:1409.0575.
- Jia, Y. et al. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the ACM International Conference on Multimedia, 675–678 (ACM, 2014). URL http://dl.acm.org/citation.cfm?id=2654889.
原文:https://arxiv.org/abs/1508.06576
以上是 一个艺术风格化的神经网络算法 的全部内容, 来源链接: utcz.com/z/264686.html