Java版赫夫曼编码
PS:本文系转载文章,阅读原文可读性会更好,文章末尾有原文链接
目录
1、赫夫曼编码
1、1 赫夫曼编码的基本介绍 1、2 通信领域中信息的处理方式
1、2、1 定长编码
1、2、2 变长编码
1、2、3 赫夫曼编码
1、赫夫曼树编码
1、1 赫夫曼编码的基本介绍
赫夫曼编码是一种编码方式,也是—种程序算法;赫夫曼编码是赫夫曼树在电讯通信中的经典的应用之—;赫夫曼编码广泛地用于数据文件压缩,其压缩率一般在20%~90%之间;赫夫曼码是可变字长编码的一种,Huffman于1952年提出一种编码方法,称之为最佳编码。
1、2 通信领域中信息的处理方式
1、2、1 定长编码
我们列举通信领域中信息的处理方式-定长编码,假设我要发送一句话给别人 “the virus mutated and became weaker and weaker” ,按照定长编码的方式,这句话转化成二进制编码后长度是多少呢?我们先给出一张 Ascill 编码表,如图1所示;
图片
图1
空格(图1未给出空格)的十进制 Ascill 编码是 32,二进制 Ascill 编码是 00100000 ; 看图1,a 的十进制 Ascill 编码是 97,二进制 Ascill 编码是 01100001 ;看懂了图1的 a 字符 Ascill 编码,其他字符的Ascill 编码也应该能看懂了吧?图1中的其他字符 Ascill 编码我不再一一描述,但不管怎么看图1中的字符,它的二进制 Ascill 编码都是8位。我们把上面要发送的一句话放在记事本统计一下字符数,如图2所示;
图片
图2看图2,发送的这句话字符长度是46个;然后再看图1字符二进制的 Ascill 码,一个字符占8位,所以发送的这句话换成二进制,长度就是 46 X 8 = 368 。
1、2、2 变长编码
假设我要发送一句话给别人也是 “the virus mutated and became weaker and weaker”,要进行传输的过程,肯定是要转换成二进制编码的,用变长编码的方式可以减少字节所占用的内存;好,我们现在开始进行变长编码分析,我们先把 “the virus mutated and became weaker and weaker” 这句话中每个字符出现的个数用表格列举出来,如下表1所示;
图片
好,我们现在对表1的字符进行二进制编码,原则上出现次数越多的,编码就越小;例如,字符 e ,出现的次数是最多的,我们把它的编码弄成0,好了,现在我们也把表1的字符弄一个编码表出来,如表2所示;
图片
我们把 “the virus mutated and became weaker and weaker” 这句话,全部转换成用表2中的二进制编码表示,得到表3;
图片
表3中的字符装不下那么多,我就省略了;“the virus mutated and became weaker and weaker” 这句话按照表2的规则转换成二进制编码就是 1001101011011110011111111011000111100101000101110110101111110100001010000110010101010011110110101110010101010011 ;把这串二进制编码放入记事本总计其长度,得到如图3的长度统计;
图片
图3二进制长度为112,相对于定长编码来说,“the virus mutated and became weaker and weaker” 这句话的压缩率为 (368-112)/ 368 X 100% = 70% ,但是我们解码的时候就麻烦了,比如开头的编码是解码成10呢还是101,如果是解码成10就变成字母 a 了,就解码错了。
1、2、3 赫夫曼编码
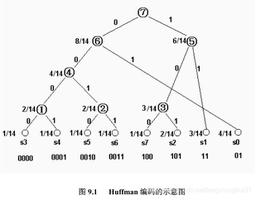
赫夫曼编码使用了定长编码和变长编码的一些优点,例如它要用到十进制的 Ascill 码和用到字符出现的次数作为二进制编码,这样就可以做到压缩字节码又可以解码无损失。好,我们现在先画一棵含有赫夫曼编码的一棵树,方便下面说的内容好理解,如图3所示;
图片
看图3,节点左边的路径就用0表示,右边的路径用1表示,a 字符的编码是 10 。
我们继续使用 “the virus mutated and became weaker and weaker” 这句话进行传输,这次我们用赫夫曼编码,步骤如下所示;
(1)还是使用表1中字符。
(2)将表1中字符出现的次数作为权值构建赫夫曼树(构建赫夫曼树的过程可以看Java版赫夫曼树这篇文章)。
(3)根据赫夫曼树,向左的路径为0,向右的路径为1,我们要发送的字符串中字符二进制编码如表2所示。
(4)用十进制的 Ascill 码作为叶子节点的 data 值,用节点的权值转化为二进制码。
(5)构建成赫夫曼编码的这棵树肯定是赫夫曼树,最后根据赫夫曼编码使得 “the virus mutated and became weaker and weaker” 这句话转化成二进制码是:1000101111001100011101111010110110000010000100100010101000101001010111100
好,我们现在代码实现一把;
(1)创建一个节点类 Node :
/**
- Node 实现 Comparable 是为了让Node 对象持续排序 Collections 集合排序
*/
public class Node implements Comparable<Node>{
private Byte data;//存放十进制的 Ascill 码,比 'a' 字符,那么 Ascill 码就是97
private int weight;//权值
private Node left;//左孩子
private Node right;//右孩子
@Override
public int compareTo(Node arg0) {
// 从小到大排序return this.weight - arg0.weight;
}
public Node(Byte data, int weight) {
super();this.data = data;
this.weight = weight;
}
public Byte getData() {
return data;}
public Node getLeft() {
return left;}
public void setLeft(Node left) {
this.left = left;}
public Node getRight() {
return right;}
public void setRight(Node right) {
this.right = right;}
public int getWeight() {
return weight;}
}
(2)创建一个生成赫夫曼编码的类 Test :
public class Test {
Node root;public static void main(String[] args) {
String s = "the virus mutated and became weaker and weaker";byte[] bs = s.getBytes();
System.out.println("s的长度为:" + s.length());
Test test = new Test();
List<Node> list = test.getNode(bs);
test.root = test.createHuffmanTree(list);
//生成赫夫曼编码表,将 赫夫曼编码表 存放到 huffumanCodes 中
test.getCodes(test.root, "", test.sb);
s = "";
for (Map.Entry<Byte, String> map : test.huffumanCodes.entrySet()){
s = s + map.getValue();
}
System.out.println("s根据赫夫曼编码而生成对应的二进制码是" + s);
}
//拼接赫夫曼树的节点的路径,节点的左路径用“0” 表示,右路径用“1”表示
StringBuilder sb = new StringBuilder();
Map<Byte,String> huffumanCodes = new HashMap<Byte,String>();
//生成赫夫曼编码表
/**
- @param node 传入的节点
- @param code 节点的左路径用“0” 表示,右路径用“1”表示
- @param sb 拼接code
- @return
*/
private void getCodes(Node node,String code,StringBuilder sb) {
StringBuilder sb2 = new StringBuilder(sb);//将code 加入到 sb2 中
sb2.append(code);
if (node != null) {
//非叶子节点
if (node.getData() == null) {
//向左递归处理
getCodes(node.getLeft(), "0", sb2);
//向右递归处理
getCodes(node.getRight(), "1", sb2);
//是叶子节点
} else {
huffumanCodes.put(node.getData(), sb2.toString());
}
}
}
private List<Node> getNode(byte[] bs) {
ArrayList<Node> list = new ArrayList<Node>();//统计byte出现的次数
Map<Byte,Integer> map = new HashMap<Byte,Integer>();
for (int i = 0; i<bs.length; i++) {
Integer count = map.get(bs[i]);
//第一次存放该字节
if (count == null) {
map.put(bs[i],1);
} else {
map.put(bs[i], count + 1);
}
}
for (Map.Entry<Byte, Integer> entry : map.entrySet()) {
Byte data = entry.getKey();
int weight = entry.getValue();
Node node = new Node(data,weight);
list.add(node);
}
return list;
}
//创建赫夫曼树
private Node createHuffmanTree(List<Node> list) {
while (list.size() > 1) { // 排序,从小到大排序
Collections.sort(list);
// System.out.println("list = " + list);
/**
* 这个一定是权值最小的节点
*/
Node minNode = list.get(0);
/**
* 除了 minNode 节点,该节点就是权值最小的节点,只是该节点比 minNode 节点大, 比其他节点都小
*/
Node secondMinNode = list.get(1);
/**
* 构建一棵新的二叉树
*/
Node parentNode = new Node(null,minNode.getWeight()
+ secondMinNode.getWeight());
parentNode.setLeft(minNode);
parentNode.setRight(secondMinNode);
/**
* 从 list 集合中删除2棵已经构建成一棵二叉树的2个节点
*/
list.remove(minNode);
list.remove(secondMinNode);
/**
* 将新的二叉树的父节点加入到 list 集合中
*/
list.add(parentNode);
}
/**
* 构建完哈夫曼树后,list 集合中的第一个节点肯定是根节点
*/
return list.get(0);
}
}
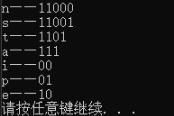
日志打印如下所示:
图片
从日志可以看出,跟我们上面所说的结果,根据赫夫曼编码转化成二进制码是一样的;这里说的是赫夫曼编码,下一篇会写赫夫曼解码,敬请期待。
以上是 Java版赫夫曼编码 的全部内容, 来源链接: utcz.com/z/267431.html