C++实现简单BP神经网络
本文实例为大家分享了C++实现简单BP神经网络的具体代码,供大家参考,具体内容如下
实现了一个简单的BP神经网络
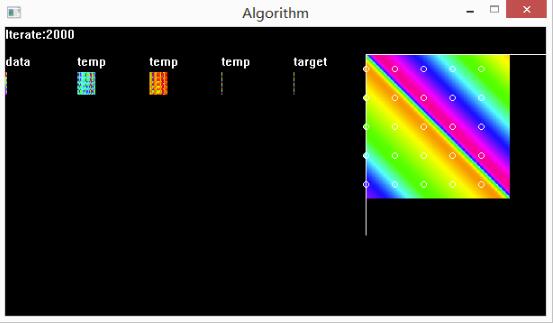
使用EasyX图形化显示训练过程和训练结果
使用了25个样本,一共训练了1万次。
该神经网络有两个输入,一个输出端
下图是训练效果,data是训练的输入数据,temp代表所在层的输出,target是训练目标,右边的大图是BP神经网络的测试结果。
以下是详细的代码实现,主要还是基本的矩阵运算。
#include <stdio.h>
#include <stdlib.h>
#include <graphics.h>
#include <time.h>
#include <math.h>
#define uint unsigned short
#define real double
#define threshold (real)(rand() % 99998 + 1) / 100000
// 神经网络的层
class layer{
private:
char name[20];
uint row, col;
uint x, y;
real **data;
real *bias;
public:
layer(){
strcpy_s(name, "temp");
row = 1;
col = 3;
x = y = 0;
data = new real*[row];
bias = new real[row];
for (uint i = 0; i < row; i++){
data[i] = new real[col];
bias[i] = threshold;
for (uint j = 0; j < col; j++){
data[i][j] = 1;
}
}
}
layer(FILE *fp){
fscanf_s(fp, "%d %d %d %d %s", &row, &col, &x, &y, name);
data = new real*[row];
bias = new real[row];
for (uint i = 0; i < row; i++){
data[i] = new real[col];
bias[i] = threshold;
for (uint j = 0; j < col; j++){
fscanf_s(fp, "%lf", &data[i][j]);
}
}
}
layer(uint row, uint col){
strcpy_s(name, "temp");
this->row = row;
this->col = col;
this->x = 0;
this->y = 0;
this->data = new real*[row];
this->bias = new real[row];
for (uint i = 0; i < row; i++){
data[i] = new real[col];
bias[i] = threshold;
for (uint j = 0; j < col; j++){
data[i][j] = 1.0f;
}
}
}
layer(const layer &a){
strcpy_s(name, a.name);
row = a.row, col = a.col;
x = a.x, y = a.y;
data = new real*[row];
bias = new real[row];
for (uint i = 0; i < row; i++){
data[i] = new real[col];
bias[i] = a.bias[i];
for (uint j = 0; j < col; j++){
data[i][j] = a.data[i][j];
}
}
}
~layer(){
// 删除原有数据
for (uint i = 0; i < row; i++){
delete[]data[i];
}
delete[]data;
}
layer& operator =(const layer &a){
// 删除原有数据
for (uint i = 0; i < row; i++){
delete[]data[i];
}
delete[]data;
delete[]bias;
// 重新分配空间
strcpy_s(name, a.name);
row = a.row, col = a.col;
x = a.x, y = a.y;
data = new real*[row];
bias = new real[row];
for (uint i = 0; i < row; i++){
data[i] = new real[col];
bias[i] = a.bias[i];
for (uint j = 0; j < col; j++){
data[i][j] = a.data[i][j];
}
}
return *this;
}
layer Transpose() const {
layer arr(col, row);
arr.x = x, arr.y = y;
for (uint i = 0; i < row; i++){
for (uint j = 0; j < col; j++){
arr.data[j][i] = data[i][j];
}
}
return arr;
}
layer sigmoid(){
layer arr(col, row);
arr.x = x, arr.y = y;
for (uint i = 0; i < x.row; i++){
for (uint j = 0; j < x.col; j++){
arr.data[i][j] = 1 / (1 + exp(-data[i][j]));// 1/(1+exp(-z))
}
}
return arr;
}
layer operator *(const layer &b){
layer arr(row, col);
arr.x = x, arr.y = y;
for (uint i = 0; i < row; i++){
for (uint j = 0; j < col; j++){
arr.data[i][j] = data[i][j] * b.data[i][j];
}
}
return arr;
}
layer operator *(const int b){
layer arr(row, col);
arr.x = x, arr.y = y;
for (uint i = 0; i < row; i++){
for (uint j = 0; j < col; j++){
arr.data[i][j] = b * data[i][j];
}
}
return arr;
}
layer matmul(const layer &b){
layer arr(row, b.col);
arr.x = x, arr.y = y;
for (uint k = 0; k < b.col; k++){
for (uint i = 0; i < row; i++){
arr.bias[i] = bias[i];
arr.data[i][k] = 0;
for (uint j = 0; j < col; j++){
arr.data[i][k] += data[i][j] * b.data[j][k];
}
}
}
return arr;
}
layer operator -(const layer &b){
layer arr(row, col);
arr.x = x, arr.y = y;
for (uint i = 0; i < row; i++){
for (uint j = 0; j < col; j++){
arr.data[i][j] = data[i][j] - b.data[i][j];
}
}
return arr;
}
layer operator +(const layer &b){
layer arr(row, col);
arr.x = x, arr.y = y;
for (uint i = 0; i < row; i++){
for (uint j = 0; j < col; j++){
arr.data[i][j] = data[i][j] + b.data[i][j];
}
}
return arr;
}
layer neg(){
layer arr(row, col);
arr.x = x, arr.y = y;
for (uint i = 0; i < row; i++){
for (uint j = 0; j < col; j++){
arr.data[i][j] = -data[i][j];
}
}
return arr;
}
bool operator ==(const layer &a){
bool result = true;
for (uint i = 0; i < row; i++){
for (uint j = 0; j < col; j++){
if (abs(data[i][j] - a.data[i][j]) > 10e-6){
result = false;
break;
}
}
}
return result;
}
void randomize(){
for (uint i = 0; i < row; i++){
for (uint j = 0; j < col; j++){
data[i][j] = threshold;
}
bias[i] = 0.3;
}
}
void print(){
outtextxy(x, y - 20, name);
for (uint i = 0; i < row; i++){
for (uint j = 0; j < col; j++){
COLORREF color = HSVtoRGB(360 * data[i][j], 1, 1);
putpixel(x + i, y + j, color);
}
}
}
void save(FILE *fp){
fprintf_s(fp, "%d %d %d %d %s\n", row, col, x, y, name);
for (uint i = 0; i < row; i++){
for (uint j = 0; j < col; j++){
fprintf_s(fp, "%lf ", data[i][j]);
}
fprintf_s(fp, "\n");
}
}
friend class network;
friend layer operator *(const double a, const layer &b);
};
layer operator *(const double a, const layer &b){
layer arr(b.row, b.col);
arr.x = b.x, arr.y = b.y;
for (uint i = 0; i < arr.row; i++){
for (uint j = 0; j < arr.col; j++){
arr.data[i][j] = a * b.data[i][j];
}
}
return arr;
}
// 神经网络
class network{
int iter;
double learn;
layer arr[3];
layer data, target, test;
layer& unit(layer &x){
for (uint i = 0; i < x.row; i++){
for (uint j = 0; j < x.col; j++){
x.data[i][j] = i == j ? 1.0 : 0.0;
}
}
return x;
}
layer grad_sigmoid(layer &x){
layer e(x.row, x.col);
e = x*(e - x);
return e;
}
public:
network(FILE *fp){
fscanf_s(fp, "%d %lf", &iter, &learn);
// 输入数据
data = layer(fp);
for (uint i = 0; i < 3; i++){
arr[i] = layer(fp);
//arr[i].randomize();
}
target = layer(fp);
// 测试数据
test = layer(2, 40000);
for (uint i = 0; i < test.col; i++){
test.data[0][i] = ((double)i / 200) / 200.0f;
test.data[1][i] = (double)(i % 200) / 200.0f;
}
}
void train(){
int i = 0;
char str[20];
data.print();
target.print();
for (i = 0; i < iter; i++){
sprintf_s(str, "Iterate:%d", i);
outtextxy(0, 0, str);
// 正向传播
layer l0 = data;
layer l1 = arr[0].matmul(l0).sigmoid();
layer l2 = arr[1].matmul(l1).sigmoid();
layer l3 = arr[2].matmul(l2).sigmoid();
// 显示输出结果
l1.print();
l2.print();
l3.print();
if (l3 == target){
break;
}
// 反向传播
layer l3_delta = (l3 - target ) * grad_sigmoid(l3);
layer l2_delta = arr[2].Transpose().matmul(l3_delta) * grad_sigmoid(l2);
layer l1_delta = arr[1].Transpose().matmul(l2_delta) * grad_sigmoid(l1);
// 梯度下降法
arr[2] = arr[2] - learn * l3_delta.matmul(l2.Transpose());
arr[1] = arr[1] - learn * l2_delta.matmul(l1.Transpose());
arr[0] = arr[0] - learn * l1_delta.matmul(l0.Transpose());
}
sprintf_s(str, "Iterate:%d", i);
outtextxy(0, 0, str);
// 测试输出
// selftest();
}
void selftest(){
// 测试
layer l0 = test;
layer l1 = arr[0].matmul(l0).sigmoid();
layer l2 = arr[1].matmul(l1).sigmoid();
layer l3 = arr[2].matmul(l2).sigmoid();
setlinecolor(WHITE);
// 测试例
for (uint j = 0; j < test.col; j++){
COLORREF color = HSVtoRGB(360 * l3.data[0][j], 1, 1);// 输出颜色
putpixel((int)(test.data[0][j] * 160) + 400, (int)(test.data[1][j] * 160) + 30, color);
}
// 标准例
for (uint j = 0; j < data.col; j++){
COLORREF color = HSVtoRGB(360 * target.data[0][j], 1, 1);// 输出颜色
setfillcolor(color);
fillcircle((int)(data.data[0][j] * 160) + 400, (int)(data.data[1][j] * 160) + 30, 3);
}
line(400, 30, 400, 230);
line(400, 30, 600, 30);
}
void save(FILE *fp){
fprintf_s(fp, "%d %lf\n", iter, learn);
data.save(fp);
for (uint i = 0; i < 3; i++){
arr[i].save(fp);
}
target.save(fp);
}
};
#include "network.h"
void main(){
FILE file;
FILE *fp = &file;
// 读取状态
fopen_s(&fp, "Text.txt", "r");
network net(fp);
fclose(fp);
initgraph(600, 320);
net.train();
// 保存状态
fopen_s(&fp, "Text.txt", "w");
net.save(fp);
fclose(fp);
getchar();
closegraph();
}
上面这段代码是在2016年初实现的,非常简陋,且不利于扩展。时隔三年,我再次回顾了反向传播算法,重构了上面的代码。
最近,参考【深度学习】一书对反向传播算法的描述,我用C++再次实现了基于反向传播算法的神经网络框架:Github: Neural-Network。该框架支持张量运算,如卷积,池化和上采样运算。除了能实现传统的stacked网络模型,还实现了基于计算图的自动求导算法,目前还有些bug。预计支持搭建卷积神经网络,并实现【深度学习】一书介绍的一些基于梯度的优化算法。
欢迎感兴趣的同学在此提出宝贵建议。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
以上是 C++实现简单BP神经网络 的全部内容, 来源链接: utcz.com/p/245221.html