python数据可视化Seaborn画热力图
1.引言
热力图的想法很简单,用颜色替换数字。
现在,这种可视化风格已经从最初的颜色编码表格走了很长一段路。热力图被广泛用于地理空间数据。这种图通常用于描述变量的密度或强度,模式可视化、方差甚至异常可视化等。
鉴于热力图有如此多的应用,本文将介绍如何使用Seaborn 来创建热力图。
2. 栗子
首先我们导入Pandas和Numpy库,这两个库可以帮助我们进行数据预处理。
import pandas as pdimport matplotlib.pyplot as plt
import seaborn as sb
import numpy as np
为了举例,我们采用的数据集是 80 种不同谷物的样本,我们来看看它们的成分。
数据集样例如下所示:
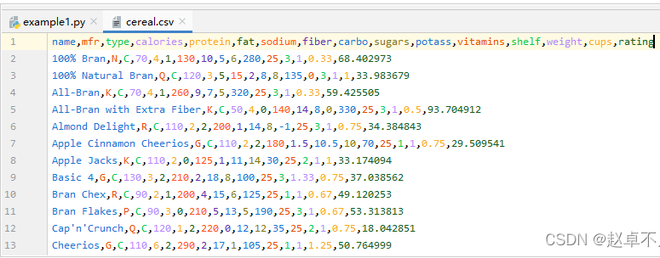
上图中,第一行为表头,接着对于每一行来说,第一列为谷物的名称,后面第4列到16列为每种谷物含有的13种主要组成成分的数值。
3. 数据预处理
解下来我们分析每种谷物13种不同成分之间的相关性,我们可以采用Pandas库中的coor()函数来计算相关性,
代码如下:
# read datasetdf = pd.read_csv('data/cereal.csv')
# get correlations
df_corr = df.corr() # 13X13
print(df_corr)
得到结果如下:
calories protein fat ... weight cups ratingcalories 1.000000 0.019066 0.498610 ... 0.696091 0.087200 -0.689376protein 0.019066 1.000000 0.208431 ... 0.216158 -0.244469 0.470618fat 0.498610 0.208431 1.000000 ... 0.214625 -0.175892 -0.409284sodium 0.300649 -0.054674 -0.005407 ... 0.308576 0.119665 -0.401295fiber -0.293413 0.500330 0.016719 ... 0.247226 -0.513061 0.584160carbo 0.250681 -0.130864 -0.318043 ... 0.135136 0.363932 0.052055sugars 0.562340 -0.329142 0.270819 ... 0.450648 -0.032358 -0.759675potass -0.066609 0.549407 0.193279 ... 0.416303 -0.495195 0.380165vitamins 0.265356 0.007335 -0.031156 ... 0.320324 0.128405 -0.240544shelf 0.097234 0.133865 0.263691 ... 0.190762 -0.335269 0.025159weight 0.696091 0.216158 0.214625 ... 1.000000 -0.199583 -0.298124cups 0.087200 -0.244469 -0.175892 ... -0.199583 1.000000 -0.203160rating -0.689376 0.470618 -0.409284 ... -0.298124 -0.203160 1.000000
[13 rows x 13 columns]
接着我们移除相关性不大的最后几个成分,代码如下:
# irrelevant fieldsfields = ['rating', 'shelf', 'cups', 'weight']
# drop rows
df_corr.drop(fields, inplace=True) # 9X13
# drop cols
df_corr.drop(fields, axis=1, inplace=True) # 9X9
print(df_corr)
得到结果如下:
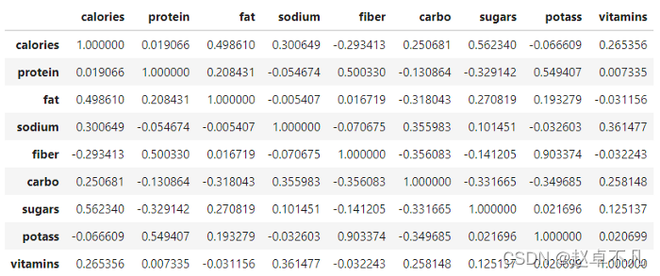
我们知道相关性矩阵是对称矩阵,矩阵中上三角和下三角的值是相同的,这带来了很大的重复。
4. 画热力图
非常幸运的是我们可以使用Mask矩阵来生成Seaborn中的热力图,那么我们首先来生成Mask矩阵。
np.ones_like(df_corr, dtype=np.bool)
结果如下:
接着我们来得到上三角矩阵,在Numpy中使用np.triu函数可以返回上三角矩阵对应的Mask,
如下所示:
mask = np.triu(np.ones_like(df_corr, dtype=np.bool))
结果如下:

接下来我们画热力图,如下所示:
sb.heatmap(df_corr,mask=mask)plt.show()
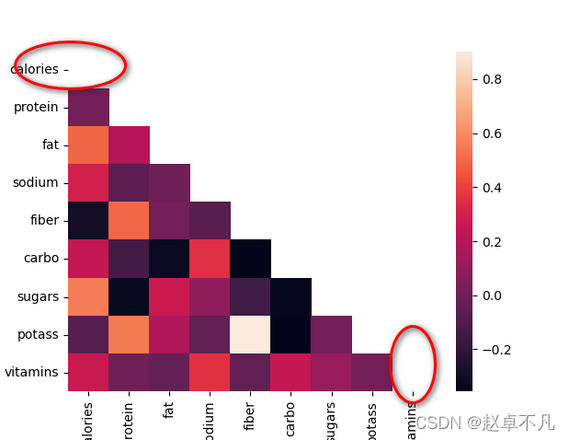
此时的运行结果如下:
5. 添加数值
观察上图,我们虽然使用Mask生成了热力图,但是图像中还有两个空的单元格(红色圆圈所示)。
我们当然可以在绘制的时候将其进行过滤。即分别将和上述圆圈对应的mask和df_corr过滤掉,
代码如下:
# adjust mask and dfmask = mask[1:, :-1]
corr = df_corr.iloc[1:, :-1].copy()
同时我们可以设置heatmap相应的参数,让其显示对应的数值,
完整代码如下:
def test2():# read dataset
df = pd.read_csv('data/cereal.csv')
# get correlations
df_corr = df.corr() # 13X13
# irrelevant fields
fields = ['rating', 'shelf', 'cups', 'weight']
df_corr.drop(fields, inplace=True) # 9X13
# drop cols
df_corr.drop(fields, axis=1, inplace=True) # 9X9
mask = np.triu(np.ones_like(df_corr, dtype=np.bool))
# adjust mask and df
mask = mask[1:, :-1]
corr = df_corr.iloc[1:, :-1].copy()
# plot heatmap
sb.heatmap(corr, mask=mask, annot=True, fmt=".2f", cmap='Blues',
vmin=-1, vmax=1, cbar_kws={"shrink": .8})
# yticks
plt.yticks(rotation=0)
plt.show()
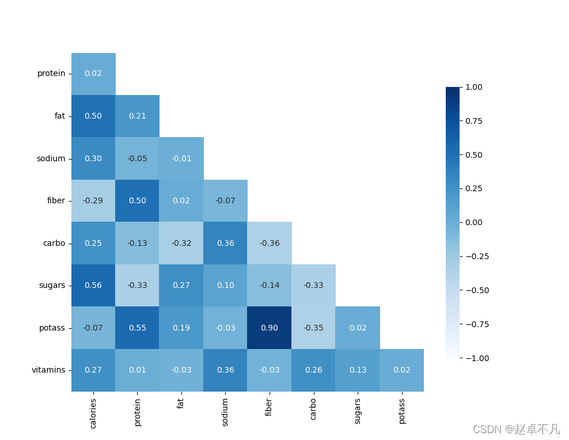
运行结果如下:
6. 调色板优化
接着我们继续优化可视化的效果,考虑到相关系数的范围为-1到1,所以颜色变化有两个方向。基于此,由中间向两侧发散的调色板相比连续的调色板视觉效果会更好。如下所示为发散的调色板示例:

在Seaborn库中存在生成发散调色板的函数 driverging_palette,该函数用于构建colormaps,每侧使用一种颜色,并在中心汇聚成另一种颜色。
这个函数的完整形式如下:
diverging_palette(h_neg, h_pos, s=75, l=50, sep=1,n=6, center=“light”, as_cmap=False)
该函数使用颜色表示形式为HUSL,即hue,Saturation和Lightness。这里我们查阅网站来选择我们接下来设置的调色板的颜色。
最后但是最最重要的一点,不要忘了在我们的图像上设置标题,使用title函数即可。
完整代码如下:
def test3():# read dataset
df = pd.read_csv('data/cereal.csv')
# get correlations
df_corr = df.corr() # 13X13
# irrelevant fields
fields = ['rating', 'shelf', 'cups', 'weight']
df_corr.drop(fields, inplace=True) # 9X13
# drop cols
df_corr.drop(fields, axis=1, inplace=True) # 9X9
fig, ax = plt.subplots(figsize=(12, 10))
# mask
mask = np.triu(np.ones_like(df_corr, dtype=np.bool))
# adjust mask and df
mask = mask[1:, :-1]
corr = df_corr.iloc[1:, :-1].copy()
# color map
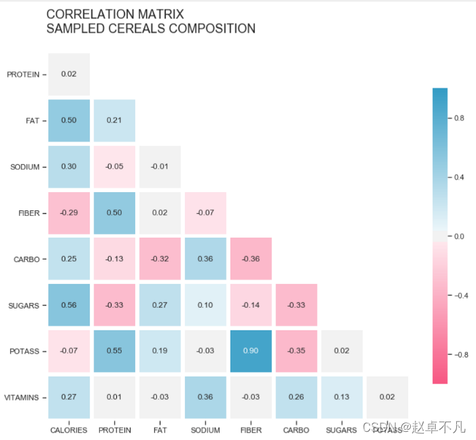
cmap = sb.diverging_palette(0, 230, 90, 60, as_cmap=True)
# plot heatmap
sb.heatmap(corr, mask=mask, annot=True, fmt=".2f",
linewidths=5, cmap=cmap, vmin=-1, vmax=1,
cbar_kws={"shrink": .8}, square=True)
# ticks
yticks = [i.upper() for i in corr.index]
xticks = [i.upper() for i in corr.columns]
plt.yticks(plt.yticks()[0], labels=yticks, rotation=0)
plt.xticks(plt.xticks()[0], labels=xticks)
# title
title = 'CORRELATION MATRIX\nSAMPLED CEREALS COMPOSITION\n'
plt.title(title, loc='left', fontsize=18)
plt.show()
运行结果如下:
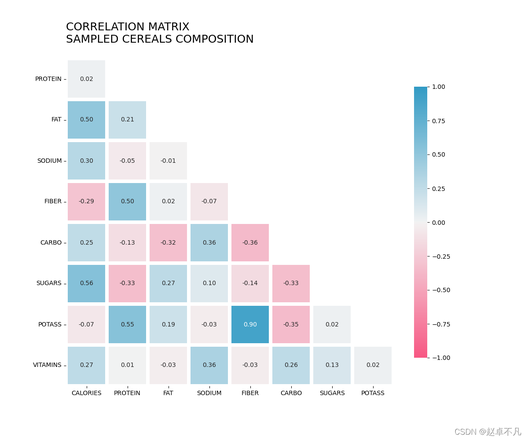
是不是看上去高大上了很多。人类果然还是视觉动物。
到此这篇关于数据可视化Seaborn画热力图的文章就介绍到这了,更多相关Seaborn画热力图内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
以上是 python数据可视化Seaborn画热力图 的全部内容, 来源链接: utcz.com/z/257002.html