
Python自动爬取图片并保存实例代码
一、准备工作
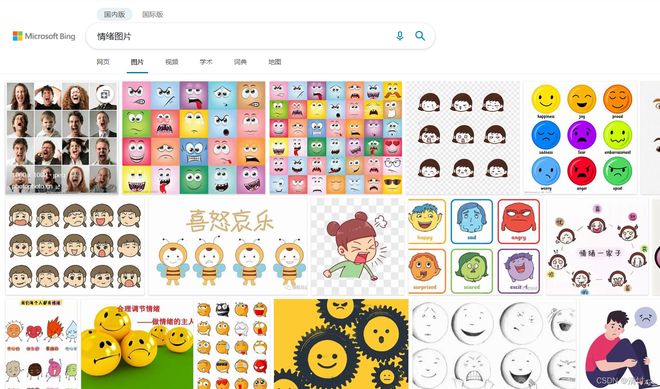
用python来实现对百度图片的爬取并保存,以情绪图片为例,百度搜索可得到下图所示
f12打开源码
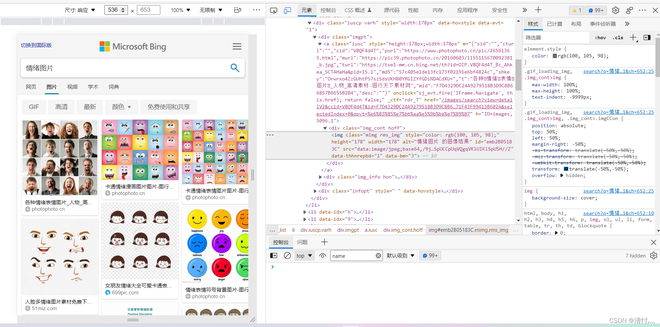
在此处可以看到这次我们要爬取的图片的基本信息是在img - scr中
二、代码实现
这次的爬取主要用了如下的第三方库
import reimport time
import requests
from bs4 import BeautifulSoup
import os
简单构思可以分为三个小部分
1.获取网页内容
2.解析网页
3.保存图片至相应位置
下面来看第一部分:获取网页内容
baseurl = 'https://cn.bing.com/images/search?q=%E6%83%85%E7%BB%AA%E5%9B%BE%E7%89%87&qpvt=%e6%83%85%e7%bb%aa%e5%9b%be%e7%89%87&form=IGRE&first=1&cw=418&ch=652&tsc=ImageBasicHover'head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Edg/92.0.902.67"}
response = requests.get(baseurl, headers=head) # 获取网页信息
html = response.text # 将网页信息转化为text形式
是不是so easy
第二部分解析网页才是大头
来看代码
Img = re.compile(r'img.*src="(.*?)"') # 正则表达式匹配图片soup = BeautifulSoup(html, "html.parser") # BeautifulSoup解析html
#i = 0 # 计数器初始值
data = [] # 存储图片超链接的列表
for item in soup.find_all('img', src=""): # soup.find_all对网页中的img—src进行迭代
item = str(item) # 转换为str类型
Picture = re.findall(Img, item) # 结合re正则表达式和BeautifulSoup, 仅返回超链接
for b in Picture:
data.append(b)
#i = i + 1
return data[-1]
# print(i)
这里就运用到了BeautifulSoup以及re正则表达式的相关知识,需要有一定的基础哦
下面就是第三部分:保存图片
for m in getdata(baseurl='https://cn.bing.com/images/search?q=%E6%83%85%E7%BB%AA%E5%9B%BE%E7%89%87&qpvt=%e6%83%85%e7%bb%aa%e5%9b%be%e7%89%87&form=IGRE&first=1&cw=418&ch=652&tsc=ImageBasicHover'):
resp = requests.get(m) #获取网页信息
byte = resp.content # 转化为content二进制
print(os.getcwd()) # os库中输出当前的路径
i = i + 1 # 递增
# img_path = os.path.join(m)
with open("path{}.jpg".format(i), "wb") as f: # 文件写入
f.write(byte)
time.sleep(0.5) # 每隔0.5秒下载一张图片放入D://情绪图片测试
print("第{}张图片爬取成功!".format(i))
各行代码的解释已经给大家写在注释中啦,不明白的地方可以直接私信或评论哦~
下面是完整的代码
import reimport time
import requests
from bs4 import BeautifulSoup
import os
# m = 'https://tse2-mm.cn.bing.net/th/id/OIP-C.uihwmxDdgfK4FlCIXx-3jgHaPc?w=115&h=183&c=7&r=0&o=5&pid=1.7'
'''
resp = requests.get(m)
byte = resp.content
print(os.getcwd())
img_path = os.path.join(m)
'''
def main():
baseurl = 'https://cn.bing.com/images/search?q=%E6%83%85%E7%BB%AA%E5%9B%BE%E7%89%87&qpvt=%e6%83%85%e7%bb%aa%e5%9b%be%e7%89%87&form=IGRE&first=1&cw=418&ch=652&tsc=ImageBasicHover'
datalist = getdata(baseurl)
def getdata(baseurl):
Img = re.compile(r'img.*src="(.*?)"') # 正则表达式匹配图片
datalist = []
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Edg/92.0.902.67"}
response = requests.get(baseurl, headers=head) # 获取网页信息
html = response.text # 将网页信息转化为text形式
soup = BeautifulSoup(html, "html.parser") # BeautifulSoup解析html
# i = 0 # 计数器初始值
data = [] # 存储图片超链接的列表
for item in soup.find_all('img', src=""): # soup.find_all对网页中的img—src进行迭代
item = str(item) # 转换为str类型
Picture = re.findall(Img, item) # 结合re正则表达式和BeautifulSoup, 仅返回超链接
for b in Picture: # 遍历列表,取最后一次结果
data.append(b)
# i = i + 1
datalist.append(data[-1])
return datalist # 返回一个包含超链接的新列表
# print(i)
'''
with open("img_path.jpg","wb") as f:
f.write(byte)
'''
if __name__ == '__main__':
os.chdir("D://情绪图片测试")
main()
i = 0 # 图片名递增
for m in getdata(
baseurl='https://cn.bing.com/images/search?q=%E6%83%85%E7%BB%AA%E5%9B%BE%E7%89%87&qpvt=%e6%83%85%e7%bb%aa%e5%9b%be%e7%89%87&form=IGRE&first=1&cw=418&ch=652&tsc=ImageBasicHover'):
resp = requests.get(m) #获取网页信息
byte = resp.content # 转化为content二进制
print(os.getcwd()) # os库中输出当前的路径
i = i + 1 # 递增
# img_path = os.path.join(m)
with open("path{}.jpg".format(i), "wb") as f: # 文件写入
f.write(byte)
time.sleep(0.5) # 每隔0.5秒下载一张图片放入D://情绪图片测试
print("第{}张图片爬取成功!".format(i))
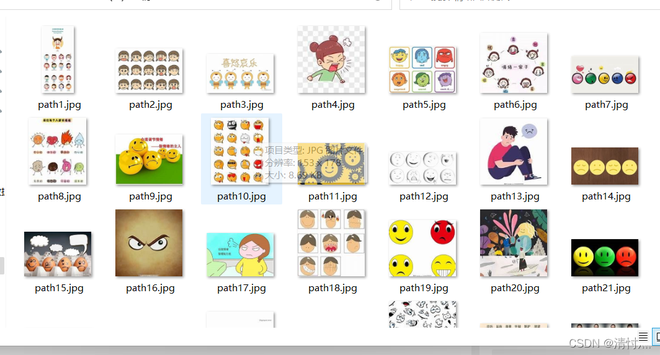
最后的运行截图
三、总结
到此这篇关于Python自动爬取图片并保存实例代码的文章就介绍到这了,更多相关Python爬取图片内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
以上是 Python自动爬取图片并保存实例代码 的全部内容, 来源链接: utcz.com/z/257003.html






