opencv+mediapipe实现人脸检测及摄像头实时示例
单张人脸关键点检测
定义可视化图像函数
导入三维人脸关键点检测模型
导入可视化函数和可视化样式
读取图像
将图像模型输入,获取预测结果
BGR转RGB
将RGB图像输入模型,获取预测结果
预测人人脸个数
可视化人脸关键点检测效果
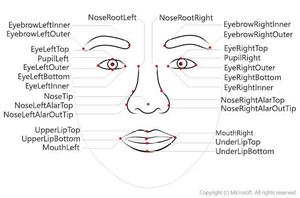
绘制人来脸和重点区域轮廓线,返回annotated_image
绘制人脸轮廓、眼睫毛、眼眶、嘴唇
在三维坐标中分别可视化人脸网格、轮廓、瞳孔
import cv2 as cv
import mediapipe as mp
from tqdm import tqdm
import time
import matplotlib.pyplot as plt
# 定义可视化图像函数
def look_img(img):
img_RGB=cv.cvtColor(img,cv.COLOR_BGR2RGB)
plt.imshow(img_RGB)
plt.show()
# 导入三维人脸关键点检测模型
mp_face_mesh=mp.solutions.face_mesh
# help(mp_face_mesh.FaceMesh)
model=mp_face_mesh.FaceMesh(
static_image_mode=True,#TRUE:静态图片/False:摄像头实时读取
refine_landmarks=True,#使用Attention Mesh模型
min_detection_confidence=0.5, #置信度阈值,越接近1越准
min_tracking_confidence=0.5,#追踪阈值
)
# 导入可视化函数和可视化样式
mp_drawing=mp.solutions.drawing_utils
mp_drawing_styles=mp.solutions.drawing_styles
# 读取图像
img=cv.imread('img.png')
# look_img(img)
# 将图像模型输入,获取预测结果
# BGR转RGB
img_RGB=cv.cvtColor(img,cv.COLOR_BGR2RGB)
# 将RGB图像输入模型,获取预测结果
results=model.process(img_RGB)
# 预测人人脸个数
len(results.multi_face_landmarks)
print(len(results.multi_face_landmarks))
# 结果:1
# 可视化人脸关键点检测效果
# 绘制人来脸和重点区域轮廓线,返回annotated_image
annotated_image=img.copy()
if results.multi_face_landmarks: #如果检测出人脸
for face_landmarks in results.multi_face_landmarks:#遍历每一张脸
#绘制人脸网格
mp_drawing.draw_landmarks(
image=annotated_image,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACEMESH_TESSELATION,
#landmark_drawing_spec为关键点可视化样式,None为默认样式(不显示关键点)
# landmark_drawing_spec=mp_drawing_styles.DrawingSpec(thickness=1,circle_radius=2,color=[66,77,229]),
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles.get_default_face_mesh_tesselation_style()
)
#绘制人脸轮廓、眼睫毛、眼眶、嘴唇
mp_drawing.draw_landmarks(
image=annotated_image,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACEMESH_CONTOURS,
# landmark_drawing_spec为关键点可视化样式,None为默认样式(不显示关键点)
# landmark_drawing_spec=mp_drawing_styles.DrawingSpec(thickness=1,circle_radius=2,color=[66,77,229]),
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles.get_default_face_mesh_tesselation_style()
)
#绘制瞳孔区域
mp_drawing.draw_landmarks(
image=annotated_image,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACEMESH_IRISES,
# landmark_drawing_spec为关键点可视化样式,None为默认样式(不显示关键点)
landmark_drawing_spec=mp_drawing_styles.DrawingSpec(thickness=1,circle_radius=2,color=[128,256,229]),
# landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles.get_default_face_mesh_tesselation_style()
)
cv.imwrite('test.jpg',annotated_image)
look_img(annotated_image)
# 在三维坐标中分别可视化人脸网格、轮廓、瞳孔
mp_drawing.plot_landmarks(results.multi_face_landmarks[0],mp_face_mesh.FACEMESH_TESSELATION)
mp_drawing.plot_landmarks(results.multi_face_landmarks[0],mp_face_mesh.FACEMESH_CONTOURS)
mp_drawing.plot_landmarks(results.multi_face_landmarks[0],mp_face_mesh.FACEMESH_IRISES)

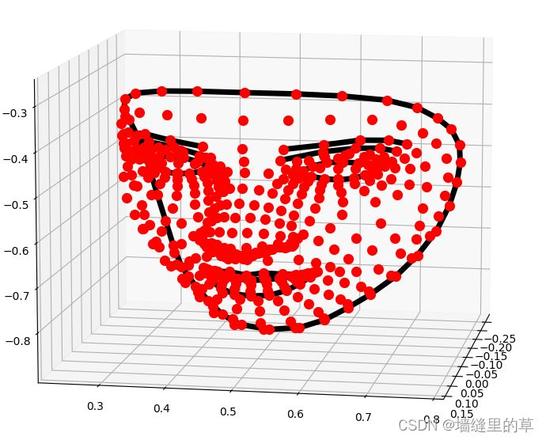
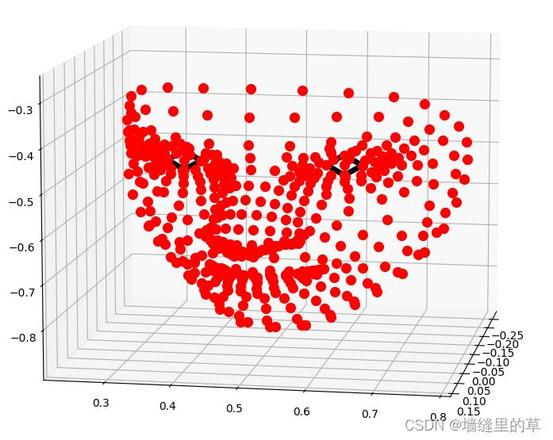
单张图像人脸检测
可以通过调用open3d实现3d模型建立,部分代码与上面类似
import cv2 as cv
import mediapipe as mp
import numpy as np
from tqdm import tqdm
import time
import matplotlib.pyplot as plt
# 定义可视化图像函数
def look_img(img):
img_RGB=cv.cvtColor(img,cv.COLOR_BGR2RGB)
plt.imshow(img_RGB)
plt.show()
# 导入三维人脸关键点检测模型
mp_face_mesh=mp.solutions.face_mesh
# help(mp_face_mesh.FaceMesh)
model=mp_face_mesh.FaceMesh(
static_image_mode=True,#TRUE:静态图片/False:摄像头实时读取
refine_landmarks=True,#使用Attention Mesh模型
max_num_faces=40,
min_detection_confidence=0.2, #置信度阈值,越接近1越准
min_tracking_confidence=0.5,#追踪阈值
)
# 导入可视化函数和可视化样式
mp_drawing=mp.solutions.drawing_utils
# mp_drawing_styles=mp.solutions.drawing_styles
draw_spec=mp_drawing.DrawingSpec(thickness=2,circle_radius=1,color=[223,155,6])
# 读取图像
img=cv.imread('../人脸三维关键点检测/dkx.jpg')
# width=img1.shape[1]
# height=img1.shape[0]
# img=cv.resize(img1,(width*10,height*10))
# look_img(img)
# 将图像模型输入,获取预测结果
# BGR转RGB
img_RGB=cv.cvtColor(img,cv.COLOR_BGR2RGB)
# 将RGB图像输入模型,获取预测结果
results=model.process(img_RGB)
# # 预测人人脸个数
# len(results.multi_face_landmarks)
#
# print(len(results.multi_face_landmarks))
if results.multi_face_landmarks:
for face_landmarks in results.multi_face_landmarks:
mp_drawing.draw_landmarks(
image=img,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACEMESH_CONTOURS,
landmark_drawing_spec=draw_spec,
connection_drawing_spec=draw_spec
)
else:
print('未检测出人脸')
look_img(img)
mp_drawing.plot_landmarks(results.multi_face_landmarks[0],mp_face_mesh.FACEMESH_TESSELATION)
mp_drawing.plot_landmarks(results.multi_face_landmarks[1],mp_face_mesh.FACEMESH_CONTOURS)
mp_drawing.plot_landmarks(results.multi_face_landmarks[1],mp_face_mesh.FACEMESH_IRISES)
# 交互式三维可视化
coords=np.array(results.multi_face_landmarks[0].landmark)
# print(len(coords))
# print(coords)
def get_x(each):
return each.x
def get_y(each):
return each.y
def get_z(each):
return each.z
# 分别获取所有关键点的XYZ坐标
points_x=np.array(list(map(get_x,coords)))
points_y=np.array(list(map(get_y,coords)))
points_z=np.array(list(map(get_z,coords)))
# 将三个方向的坐标合并
points=np.vstack((points_x,points_y,points_z)).T
print(points.shape)
import open3d
point_cloud=open3d.geometry.PointCloud()
point_cloud.points=open3d.utility.Vector3dVector(points)
open3d.visualization.draw_geometries([point_cloud])

这是建立的3d的可视化模型,可以通过鼠标拖动将其旋转
摄像头实时关键点检测
定义可视化图像函数
导入三维人脸关键点检测模型
导入可视化函数和可视化样式
读取单帧函数
主要代码和上面的图像类似
import cv2 as cv
import mediapipe as mp
from tqdm import tqdm
import time
import matplotlib.pyplot as plt
# 导入三维人脸关键点检测模型
mp_face_mesh=mp.solutions.face_mesh
# help(mp_face_mesh.FaceMesh)
model=mp_face_mesh.FaceMesh(
static_image_mode=False,#TRUE:静态图片/False:摄像头实时读取
refine_landmarks=True,#使用Attention Mesh模型
max_num_faces=5,#最多检测几张人脸
min_detection_confidence=0.5, #置信度阈值,越接近1越准
min_tracking_confidence=0.5,#追踪阈值
)
# 导入可视化函数和可视化样式
mp_drawing=mp.solutions.drawing_utils
mp_drawing_styles=mp.solutions.drawing_styles
# 处理单帧的函数
def process_frame(img):
#记录该帧处理的开始时间
start_time=time.time()
img_RGB=cv.cvtColor(img,cv.COLOR_BGR2RGB)
results=model.process(img_RGB)
if results.multi_face_landmarks:
for face_landmarks in results.multi_face_landmarks:
# mp_drawing.draw_detection(
# image=img,
# landmarks_list=face_landmarks,
# connections=mp_face_mesh.FACEMESH_TESSELATION,
# landmarks_drawing_spec=None,
# landmarks_drawing_spec=mp_drawing_styles.get_default_face_mesh_tesselation_style()
# )
# 绘制人脸网格
mp_drawing.draw_landmarks(
image=img,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACEMESH_TESSELATION,
# landmark_drawing_spec为关键点可视化样式,None为默认样式(不显示关键点)
# landmark_drawing_spec=mp_drawing_styles.DrawingSpec(thickness=1,circle_radius=2,color=[66,77,229]),
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles.get_default_face_mesh_tesselation_style()
)
# 绘制人脸轮廓、眼睫毛、眼眶、嘴唇
mp_drawing.draw_landmarks(
image=img,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACEMESH_CONTOURS,
# landmark_drawing_spec为关键点可视化样式,None为默认样式(不显示关键点)
# landmark_drawing_spec=mp_drawing_styles.DrawingSpec(thickness=1,circle_radius=2,color=[66,77,229]),
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles.get_default_face_mesh_tesselation_style()
)
# 绘制瞳孔区域
mp_drawing.draw_landmarks(
image=img,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACEMESH_IRISES,
# landmark_drawing_spec为关键点可视化样式,None为默认样式(不显示关键点)
# landmark_drawing_spec=mp_drawing_styles.DrawingSpec(thickness=1, circle_radius=2, color=[0, 1, 128]),
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles.get_default_face_mesh_tesselation_style())
else:
img = cv.putText(img, 'NO FACE DELECTED', (25 , 50 ), cv.FONT_HERSHEY_SIMPLEX, 1.25,
(218, 112, 214), 1, 8)
#记录该帧处理完毕的时间
end_time=time.time()
#计算每秒处理图像的帧数FPS
FPS=1/(end_time-start_time)
scaler=1
img=cv.putText(img,'FPS'+str(int(FPS)),(25*scaler,100*scaler),cv.FONT_HERSHEY_SIMPLEX,1.25*scaler,(0,0,255),1,8)
return img
# 调用摄像头
cap=cv.VideoCapture(0)
cap.open(0)
# 无限循环,直到break被触发
while cap.isOpened():
success,frame=cap.read()
# if not success:
# print('ERROR')
# break
frame=process_frame(frame)
#展示处理后的三通道图像
cv.imshow('my_window',frame)
if cv.waitKey(1) &0xff==ord('q'):
break
cap.release()
cv.destroyAllWindows()
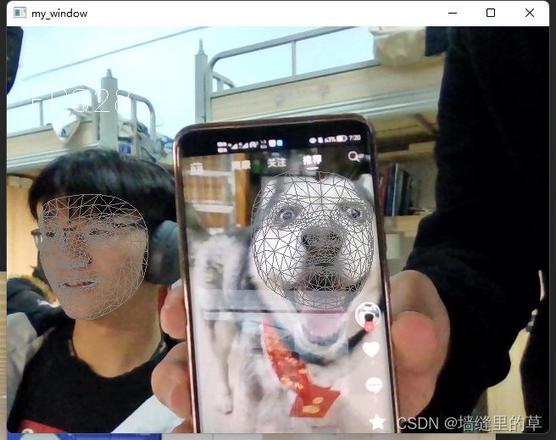
到此这篇关于opencv+mediapipe实现人脸检测及摄像头实时的文章就介绍到这了,更多相关opencv 人脸检测及摄像头实时内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
以上是 opencv+mediapipe实现人脸检测及摄像头实时示例 的全部内容, 来源链接: utcz.com/z/256963.html