Python调用Prometheus监控数据并计算
Prometheus是什么
Prometheus是一套开源监控系统和告警为一体,由go语言(golang)开发,是监控+报警+时间序列数
据库的组合。适合监控docker容器。因为kubernetes(k8s)的流行带动其发展。
Prometheus的主要特点
- 多维度数据模型,由指标名称和键/值对标识的时间序列数据。
- 作为一个时间序列数据库,其采集的数据会以文件的形式存储在本地中。
- 灵活的查询语言,PromQL(Prometheus Query Language)函数式查询语言。
- 不依赖分布式存储,单个服务器节点是自治的。
- 以HTTP方式,通过pull模型拉取时间序列数据。
- 也可以通过中间网关支持push模型。
- 通过服务发现或者静态配置,来发现目标服务对象。
- 支持多种多样的图表和界面展示。
Prometheus原理架构图
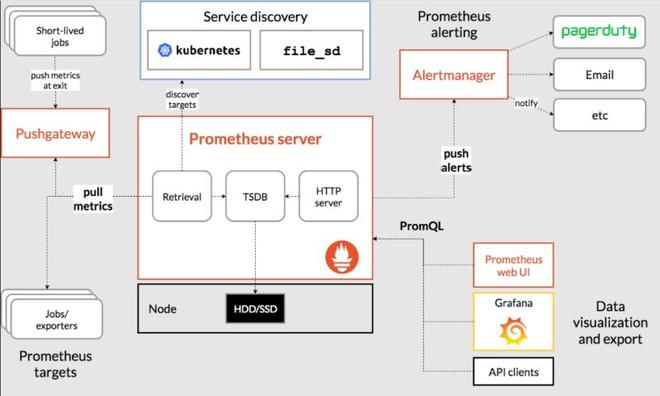
Prometheus基础概念
什么是时间序列数据
时间序列数据(TimeSeries Data) : 按照时间顺序记录系统、设备状态变化的数据被称为时序数据。
应用的场景很多,如:
- 无人驾驶运行中记录的经度,纬度,速度,方向,旁边物体距离等。
- 某一个地区的各车辆的行驶轨迹数据。
- 传统证券行业实时交易数据。
- 实时运维监控数据等。
时间序列数据特点:
- 性能好、存储成本低
什么是targets(目标)
Prometheus 是一个监控平台,它通过抓取监控目标(targets)上的指标 HTTP 端点来从这些目标收集指标。
安装完Prometheus Server端之后,第一个targets就是它本身。
具体可以参考官方文档
什么是metrics(指标)
Prometheus存在多种不同的监控指标(Metrics),在不同的场景下应该要选择不同的Metrics。
Prometheus的merics类型有四种,分别为Counter、Gauge、Summary、Histogram。
- Counter:只增不减的计数器
- Gauge:可增可减的仪表盘
- Histogram:分析数据分布情况
- Summary:使用较少
简单了解即可,暂不需要深入理解。
通过浏览器访问http://被监控端IP:9100(被监控端口)/metrics
就可以查到node_exporter在被监控端收集的监控信息
什么是PromQL(函数式查询语言)
Prometheus内置了一个强大的数据查询语言PromQL。 通过PromQL可以实现对监控数据的查询、聚合。
同时PromQL也被应用于数据可视化(如Grafana)以及告警当中。
通过PromQL可以轻松回答以下问题:
- 在过去一段时间中95%应用延迟时间的分布范围?
- 预测在4小时后,磁盘空间占用大致会是什么情况?
- CPU占用率前5位的服务有哪些?(过滤)
具体查询细节可以参考官方。
如何监控远程Linux主机
安装Prometheus组件其实很简单,下载包--解压--后台启动运行即可,不做具体演示。
在远程linux主机(被监控端)上安装node_exporter组件,可看下载地址

下载解压后,里面就一个启动命令node_exporter,直接启动即可。
nohup /usr/local/node_exporter/node_exporter >/dev/null 2>&1 &
lsof -i:9100
nohup:如果直接启动node_exporter的话,终端关闭进程也会随之关闭,这个命令帮你解决问题。
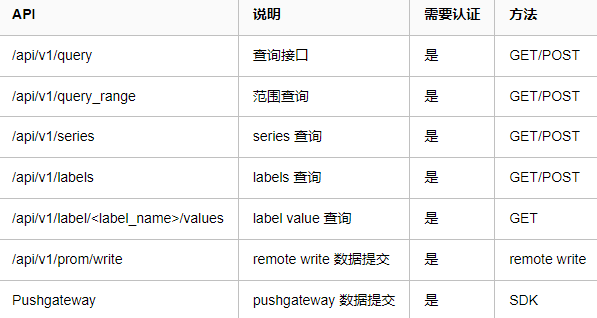
Prometheus HTTP API
Prometheus 所有稳定的 HTTP API 都在 /api/v1 路径下。当我们有数据查询需求时,可以通过查询 API 请求监控数据,提交数据可以使用 remote write 协议或者 Pushgateway 的方式。
支持的 API
认证方法
默认开启认证,因此所有的接口都需要认证,且所有的认证方式都支持 Bearer Token和 Basic Auth。
调用接口的时候,我们需要携带Basic Auth请求头的认证,否则会出现401。
Bearer Token
Bearer Token 随着实例产生而生成,可以通过控制台进行查询。了解 Bearer Token 更多信息,请参见 Bearer Authentication。
Basic Auth
Basic Auth 兼容原生 Prometheus Query 的认证方式,用户名为用户的 APPID,密码为 bearer token(实例产生时生成),可以通过控制台进行查询。了解 Basic Auth 更多信息,请参见 Basic Authentication。
数据返回格式
所有 API 的响应数据格式都为 JSON。每一次成功的请求会返回 2xx 状态码。
无效的请求会返回一个包含错误对象的 JSON 格式数据,同时也将包含一个如下表格的状态码:

无效请求响应返回模板如下:
{
"status": "success" | "error",
"data": <data>,
// 当 status 状态为 error 时,下面的数据将被返回
"errorType": "<string>",
"error": "<string>",
// 当执行请求时有警告信息时,该字段将被填充返回
"warnings": ["<string>"]
}
数据写入
运维过程不需要对数据进行写入,所以暂时不深入理解。
有兴趣的同学可以看看官方文档
监控数据查询
当我们有数据查询需求时,可以通过查询 API 请求监控数据。
查询 API 接口
GET /api/v1/query
POST /api/v1/query
查询参数:
query= : Prometheus:查询表达式。
time= <rfc3339 | unix_timestamp>: 时间戳, 可选。
timeout= :检测超时时间, 可选。 默认由 -query.timeout 参数指定。
简单的查询
查询当前状态为up的监控主机:
curl -u "appid:token" 'http://IP:PORT/api/v1/query?query=up'
范围查询
GET /api/v1/query_range
POST /api/v1/query_range
根据时间范围查询需要的数据,这也是我们用得最多的场景,
这时我们需要用到 /api/v1/query_range 接口,示例如下:
$ curl 'http://localhost:9090/api/v1/query_range?query=up&start=2015-07-01T20:10:30.781Z&end=2015-07-01T20:11:00.781Z&step=15s'
{
"status" : "success",
"data" : {
"resultType" : "matrix",
"result" : [
{
"metric" : {
"__name__" : "up",
"job" : "prometheus",
"instance" : "localhost:9090"
},
"values" : [
[ 1435781430.781, "1" ],
[ 1435781445.781, "1" ],
[ 1435781460.781, "1" ]
]
},
{
"metric" : {
"__name__" : "up",
"job" : "node",
"instance" : "localhost:9091"
},
"values" : [
[ 1435781430.781, "0" ],
[ 1435781445.781, "0" ],
[ 1435781460.781, "1" ]
]
}
]
}
}
什么是Grafana
Grafana是一个开源的度量分析和可视化工具,可以通过将采集的数据分析、查询,
然后进行可视化的展示,并能实现报警。
网址: https://grafana.com/
使用Grafana连接Prometheus
连接不再做具体演示,操作思路如下:
1.在Grafana服务器上安装,下载地址:https://grafana.com/grafana/download
2.浏览器http://grafana服务器IP:3000登录,默认账号密码都是admin,就可以登陆了。
3.把Prometheus服务器收集的数据做为一个数据源添加到Grafana,得到Prometheus数据。
4.然后为添加好的数据源做图形显示,最后在dashboard就可以查看到。
操作流程不难,就不讲解重点,后面正式开始上查询脚本。
工作使用场景
工作中需要通过CPU、内存生成资源利用率报表,可以通过Prometheus的API写一个Python脚本。

可通过API获取数据,然后再进行数据排序、过滤、运算、聚合,最后写入Mysql数据库。
CPU峰值计算
取最近一周CPU数值,再排序取最高的值。
def get_cpu_peak(self):
"""
CPU取最近一周所有数值,再排序取最高的值,TOP1
:return: {'IP' : value}
"""
# 拼接URL
pre_url = self.server_ip + '/api/v1/query_range?query='
expr = '100 - (avg by(instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) ' \
'&start=%s&end=%s&step=300' % (self.time_list[0], self.time_list[-1] - 1)
url = pre_url + expr
# print(url)
result = {}
# 请求URL后将Json数据转为字典对象
res = json.loads(requests.post(url=url, headers=self.headers).content.decode('utf8', 'ignore'))
# print(data)
# 循环取出字典里每个IP的values,排序取最高值,最后存入result字典
for da in res.get('data').get('result'):
values = da.get('values')
cpu_values = [float(v[1]) for v in values] # 取出数值并存入列表
# 取出IP并消除端口号
ip = da.get('metric').get('instance')
ip = ip[:ip.index(':')] if ':' in ip else ip
# if ip == '10.124.58.181':
# print (ip)
# cpu_peak = round(sorted(cpu_values, reverse=True)[0], 2)
cpu_peak = sorted(cpu_values, reverse=True)[0]
# 取出IP和最高值之后,写入字典
result[ip] = cpu_peak
# print(result)
return result
CPU均值计算
取最近一周CPU每一天的TOP20除以20得到当时忙时平均值,
再将7天平均值的和除以n,得到时间范围内忙时平均值。
def get_cpu_average(self):
"""
CPU忙时平均值:取最近一周CPU数据,每一天的TOP20除以20得到忙时平均值;
再将一周得到的忙时平均值相加,再除以7,得到时间范围内一周的忙时平均值。
:return:
"""
cpu_average = {}
for t in range(len(self.time_list)):
if t + 1 < len(self.time_list):
start_time = self.time_list[t]
end_time = self.time_list[t + 1]
# print(start_time, end_time)
# 拼接URL
pre_url = server_ip + '/api/v1/query_range?query='
expr = '100 - (avg by(instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) ' \
'&start=%s&end=%s&step=300' % (start_time, end_time - 1)
url = pre_url + expr
# print(url)
# 请求接口数据
data = json.loads(requests.post(url=url, headers=self.headers).content.decode('utf8', 'ignore'))
for da in data.get('data').get('result'): # 循环拿到result数据
values = da.get('values')
cpu_load = [float(v[1]) for v in values] # 循环拿到values里面的所有值
ip = da.get('metric').get('instance') # 拿到instance里面的ip
ip = ip[:ip.index(':')] if ':' in ip else ip # 去除个别后面带的端口号
# avg_cup_load = sum(sorted(cpu_load, reverse=True)[:20]) / 20
# 取top20% 再除以20%,得出top20%的平均值
# avg_cup_load = round(sum(sorted(cpu_load, reverse=True)[:round(len(cpu_load) * 0.2)]) / round(len(cpu_load) * 0.2), 2)
# 倒序后取前面20%除以个数,得到前20%的平均值
avg_cup_load = sum(sorted(cpu_load, reverse=True)[:round(len(cpu_load) * 0.2)]) / round(len(cpu_load) * 0.2)
# print(avg_cup_load)
# 将计算后的数据以ip为key写入字典
if cpu_average.get(ip):
cpu_average[ip].append(avg_cup_load)
else:
cpu_average[ip] = [avg_cup_load]
# 每日top20的平均值累加,共7天的再除以7
for k, v in cpu_average.items():
# cpu_average[k] = round(sum(v) / 7, 2)
cpu_average[k] = sum(v)
# print(cpu_average)
return cpu_average
内存峰值计算
取7天内存数值,排序后取最高峰值TOP1
def get_mem_peak(self):
"""
内存单台峰值:取7天内存最高峰值TOP1
:return: 7天内存使用率最高峰值
"""
pre_url = self.server_ip + '/api/v1/query_range?query='
# expr = '(node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100&start=%s&end=%s&step=300' % (start_time, end_time)
# 字符太长会导致报错,所以这里进行拆分字段计算
expr_MenTotal = 'node_memory_MemTotal_bytes&start=%s&end=%s&step=300' % (self.time_list[0], self.time_list[-1] - 1)
expr_MemFree = 'node_memory_MemFree_bytes&start=%s&end=%s&step=300' % (self.time_list[0], self.time_list[-1] - 1)
expr_Buffers = 'node_memory_Buffers_bytes&start=%s&end=%s&step=300' % (self.time_list[0], self.time_list[-1] - 1)
expr_Cached = 'node_memory_Cached_bytes&start=%s&end=%s&step=300' % (self.time_list[0], self.time_list[-1] - 1)
result = {}
# 循环分别取出总内存、可用内存、Buffer块、缓存块四个字段
for ur in expr_MenTotal, expr_MemFree, expr_Buffers, expr_Cached:
url = pre_url + ur
data = json.loads(requests.post(url=url, headers=self.headers).content.decode('utf8', 'ignore'))
ip_dict = {}
# 循环单个字段所有值
for da in data.get('data').get('result'):
ip = da.get('metric').get('instance')
ip = ip[:ip.index(':')] if ':' in ip else ip
# if ip != '10.124.53.12':
# continue
if ip_dict.get(ip): # 过滤重复的ip,重复ip会导致计算多次
# print("重复ip:%s" % (ip))
continue
values = da.get('values')
# 将列表里的值转为字典方便计算
values_dict = {}
for v in values:
values_dict[str(v[0])] = v[1]
# 标记ip存在
ip_dict[ip] = True
# 建立列表追加字典
if result.get(ip):
result[ip].append(values_dict)
else:
result[ip] = [values_dict]
# print(result)
# 对取出的四个值进行计算,得出峰值
for ip, values in result.items():
values_list = []
for k, v in values[0].items():
try:
values_MenTotal = float(v)
values_MemFree = float(values[1].get(k, 0))
values_Buffers = float(values[2].get(k, 0)) if values[2] else 0
values_Cached = float(values[3].get(k, 0)) if values[3] else 0
# 如果是0,不参与计算
if values_MemFree==0.0 or values_Buffers==0.0 or values_Cached==0.0:
continue
# values_list.append(round((values_MenTotal - (values_MemFree + values_Buffers + values_Cached)) / values_MenTotal * 100, 2))
# 合并后计算,得出列表
values_list.append((values_MenTotal - (values_MemFree + values_Buffers + values_Cached)) / values_MenTotal * 100)
# 对得出结果进行排序
result[ip] = sorted(values_list, reverse=True)[0]
except Exception as e:
# print(values[0])
logging.exception(e)
# print(result)
return result
内存均值计算
先取出7天的日期,根据多条链接循环取出每天数据,排序value取top20除以20,最终7天数据再除以7
def get_mem_average(self):
"""
内存忙时平均值:先取出7天的日期,根据多条链接循环取出每天数据,排序value取top20除以20,最终7天数据再除以7
:return:
"""
avg_mem_util = {}
for t in range(len(self.time_list)):
if t + 1 < len(self.time_list):
start_time = self.time_list[t]
end_time = self.time_list[t + 1]
# 根据多条链接循环取出每天数据
pre_url = self.server_ip + '/api/v1/query_range?query='
# expr = '(node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100&start=%s&end=%s&step=300' % (start_time, end_time)
expr_MenTotal = 'node_memory_MemTotal_bytes&start=%s&end=%s&step=600' % (start_time, end_time - 1)
expr_MemFree = 'node_memory_MemFree_bytes&start=%s&end=%s&step=600' % (start_time, end_time - 1)
expr_Buffers = 'node_memory_Buffers_bytes&start=%s&end=%s&step=600' % (start_time, end_time - 1)
expr_Cached = 'node_memory_Cached_bytes&start=%s&end=%s&step=600' % (start_time, end_time - 1)
result = {}
# 循环取出四个字段
for ur in expr_MenTotal, expr_MemFree, expr_Buffers, expr_Cached:
url = pre_url + ur
data = json.loads(requests.post(url=url, headers=self.headers).content.decode('utf8', 'ignore'))
ip_dict = {}
# 循环单个字段所有值
for da in data.get('data').get('result'):
ip = da.get('metric').get('instance')
ip = ip[:ip.index(':')] if ':' in ip else ip
if ip_dict.get(ip):
# print("重复ip:%s" % (ip))
continue
values = da.get('values')
# 将列表里的值转为字典方便计算
values_dict = {}
for v in values:
values_dict[str(v[0])] = v[1]
# 标记ip存在
ip_dict[ip] = True
# 建立列表追加字典
if result.get(ip):
result[ip].append(values_dict)
else:
result[ip] = [values_dict]
# print(result)
for ip, values in result.items():
values_list = []
for k, v in values[0].items():
try:
values_MenTotal = float(v)
values_MemFree = float(values[1].get(k, 0)) if values[1] else 0
values_Buffers = float(values[2].get(k, 0)) if values[2] else 0
values_Cached = float(values[3].get(k, 0)) if values[3] else 0
if values_MemFree == 0.0 or values_Buffers == 0.0 or values_Cached == 0.0:
continue
value_calc = (values_MenTotal - (values_MemFree + values_Buffers + values_Cached)) / values_MenTotal * 100
if value_calc != float(0):
values_list.append(value_calc)
except Exception as e:
print(values[0])
# logging.exception(e)
continue
# 排序value取top20除以20
# avg_mem = round(sum(sorted(values_list, reverse=True)[:round(len(values_list) * 0.2)]) / round(len(values_list) * 0.2), 2)
try:
avg_mem = sum(sorted(values_list, reverse=True)[:round(len(values_list) * 0.2)]) / round(len(values_list) * 0.2)
except Exception as e:
avg_mem = 0
logging.exception(e)
if avg_mem_util.get(ip):
avg_mem_util[ip].append(avg_mem)
else:
avg_mem_util[ip] = [avg_mem]
# 最终7天数据再除以7
for k, v in avg_mem_util.items():
# avg_mem_util[k] = round(sum(v) / 7, 2)
avg_mem_util[k] = sum(v)
return avg_mem_util
导出excel
将采集到的数据导出excel
def export_excel(self, export):
"""
将采集到的数据导出excel
:param export: 数据集合
:return:
"""
try:
# 将字典列表转换为DataFrame
pf = pd.DataFrame(list(export))
# 指定字段顺序
order = ['ip', 'cpu_peak', 'cpu_average', 'mem_peak', 'mem_average', 'collector']
pf = pf[order]
# 将列名替换为中文
columns_map = {
'ip': 'ip',
'cpu_peak': 'CPU峰值利用率',
'cpu_average': 'CPU忙时平均峰值利用率',
'mem_peak': '内存峰值利用率',
'mem_average': '内存忙时平均峰值利用率',
'collector': '来源地址'
}
pf.rename(columns=columns_map, inplace=True)
# 指定生成的Excel表格名称
writer_name = self.Host + '.xlsx'
writer_name.replace(':18600', '')
# print(writer_name)
file_path = pd.ExcelWriter(writer_name.replace(':18600', ''))
# 替换空单元格
pf.fillna(' ', inplace=True)
# 输出
pf.to_excel(file_path, encoding='utf-8', index=False)
# 保存表格
file_path.save()
except Exception as e:
print(e)
logging.exception(e)
因为机房需要保留数据方便展示,后面改造成采集直接入库mysql。
参考链接:
Prometheus操作指南
官方查询API
以上就是Python调用Prometheus监控数据并计算 的详细内容,更多关于Python Prometheus监控数据并计算 的资料请关注其它相关文章!
以上是 Python调用Prometheus监控数据并计算 的全部内容, 来源链接: utcz.com/z/256964.html