基于tensorflow对MNIST中的手写数字进行分类,但是对训练集与测试集的像素归一化后,训练时打印显示训练集的准确地极其低!这是为什么?
我想基于tensorflow对MNIST中的手写数字进行分类,但是对训练集与测试集的像素归一化后,训练时打印显示训练集的准确地极其低!请大家帮我分析下原因,代码如下:
# 导入各种包import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data
import os
import pickle
# 超参数设置
numClasses = 10
inputSize = 784
batch_size = 64
learning_rate = 0.05
# 下载数据集
mnist = input_data.read_data_sets('original_data/', one_hot=True)
train_img = mnist.train.images
train_label = mnist.train.labels
test_img = mnist.test.images
test_label = mnist.test.labels
train_img /= 255.0
test_img /= 255.0
X = tf.compat.v1.placeholder(tf.float32, shape=[None, inputSize])
y = tf.compat.v1.placeholder(tf.float32, shape=[None, numClasses])
W = tf.Variable(tf.random_normal([inputSize, numClasses], stddev=0.1))
B = tf.Variable(tf.constant(0.1), [numClasses])
y_pred = tf.nn.softmax(tf.matmul(X, W) + B)
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=y_pred)) + 0.01 * tf.nn.l2_loss(W)
opt = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_pred, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
saver = tf.train.Saver()
multiclass_parameters = {}
# 运行
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# 开始训练 外循环控制轮数,内循环训练
for epoch in range(20):
total_batch = int(len(train_img) / batch_size) # 总批次=训练的样本总数/批次大小
for batch in range(total_batch): # 一个批次的训练
# 从训练集获取到一个批次的数据
batch_input = train_img[batch * batch_size: (batch + 1) * batch_size]
batch_label = train_label[batch * batch_size: (batch + 1) * batch_size]
_, trainingLoss = sess.run([opt, loss], feed_dict={X: batch_input, y: batch_label})
train_acc = sess.run(accuracy, feed_dict={X: train_img, y: train_label})
print("Epoch %d Training Accuracy %g" % (epoch + 1, train_acc))
打印结果如下图所示: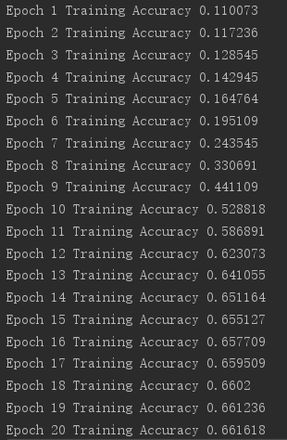
显示准确率非常的低,请各位大佬帮忙分析下原因,感谢!
回答:
# 这行代码改一下:# y_pred = tf.nn.softmax(tf.matmul(X, W) + B)
# 改为
y_pred = tf.matmul(X, W) + B
# 其他代码保持不变
这些修改看看:
# ...(导入包和设置超参数的代码部分保持不变)# 下载数据集
mnist = input_data.read_data_sets('original_data/', one_hot=True)
train_img = mnist.train.images
train_label = mnist.train.labels
test_img = mnist.test.images
test_label = mnist.test.labels
train_img /= 255.0
test_img /= 255.0
X = tf.compat.v1.placeholder(tf.float32, shape=[None, inputSize])
y = tf.compat.v1.placeholder(tf.float32, shape=[None, numClasses])
W = tf.Variable(tf.random_normal([inputSize, numClasses], stddev=0.1))
B = tf.Variable(tf.constant(0.1), [numClasses])
y_pred = tf.matmul(X, W) + B
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=y_pred)) + 0.01 * tf.nn.l2_loss(W)
opt = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(tf.nn.softmax(y_pred), 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
saver = tf.train.Saver()
multiclass_parameters = {}
# ...(运行代码部分保持不变)
以上是 基于tensorflow对MNIST中的手写数字进行分类,但是对训练集与测试集的像素归一化后,训练时打印显示训练集的准确地极其低!这是为什么? 的全部内容, 来源链接: utcz.com/p/938873.html