d3doop学习之路(1)
1.环境:虚拟机Workstation 15 Pro,使用镜像CentOS-7-x86_64-Minimal-1908.iso
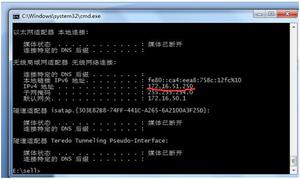
2.配置虚拟机,根据主机IP制定虚拟机网关以及IP,使用NAT模式连接,并测试.
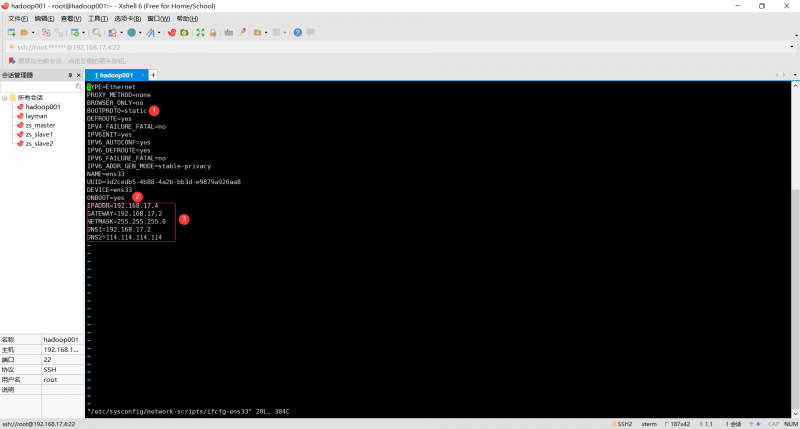
3.配置静态ip,使用ip addr查看网卡位置,并修改vi /etc/sysconfig/network-scripts/ifcfg-ens33(每个网卡名称不一样)
4.克隆并配置host,ip,hostname
5.安装jdk,hadoop,解压配置,并source /etc/profile,配置解读https://hadoop.apache.org/docs/r2.7.4/
1 core-site.xml<configuration><property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
</configuration>
2 hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop001:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
3 mapred-site.xml
复制cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- jobhistory properties -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoo001:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoo001:19888</value>
</property>
</configuration>
4 yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop001</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp/logs</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop001:19888/jobhistory/logs/</value>
<description>URL for job history server</description>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
其他的见到env,就添加JAVA_HOME

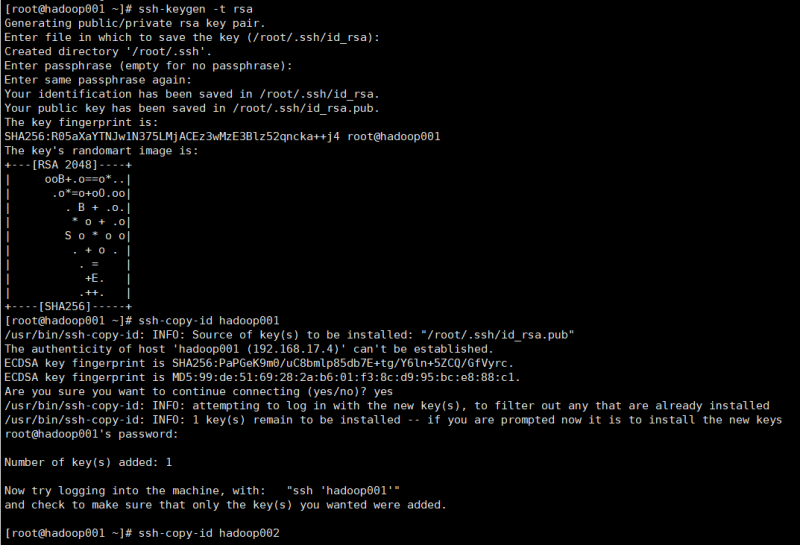
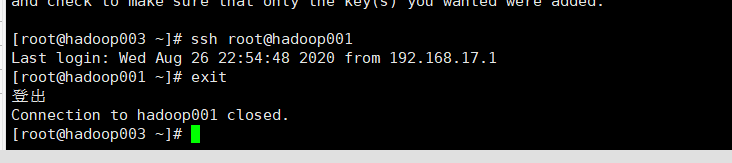
6.配置ssh免密 ssh-keygen -t rsa 三个回车,依次全部配置(包括自身本机),并验证
7.scp -r /opt/module root@hadoop002:/opt/,依次传module,以及/etc/profile
8.设置配置同步 yum install ntpdate ntp -y,
使用命令“vi /etc/ntp.conf”打开/etc/ntp.conf文件,注释掉以server开头的行,并添加:
restrict 192.168.0.0 mask 255.255.255.0 nomodify notrap
server 127.127.1.0
fudge 127.127.1.0 stratum 10
执行命令“sudo systemctl stop firewalld.service && sudo systemctl disable firewalld.service”永久性关闭防火墙,主节点和从节点都要关闭
在hadoop001节点执行命令“service ntpd start & chkconfig ntpd on”
在hadoop002/3上执行命令“ntpdate hadoop001”即可同步时间
在hadoop002/3上分别执行“service ntpd start & chkconfig ntpd on”即可启动并永久启动NTP服务。

9.在cd /opt/module/hadoop-2.7.2/sbin下面执行(我的结点都配置hadoop001上面了,就不切换主机了,nn和2nn还是别放一起)
./start-dfs.sh
./start-yarn.sh
./mr-jobhistory-daemon.sh start historyserver
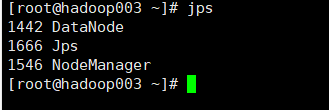
10. 浏览器查看:(这里在本机host配置了ip映射)
http://hadoop001:50070
http://hadoop001:8088
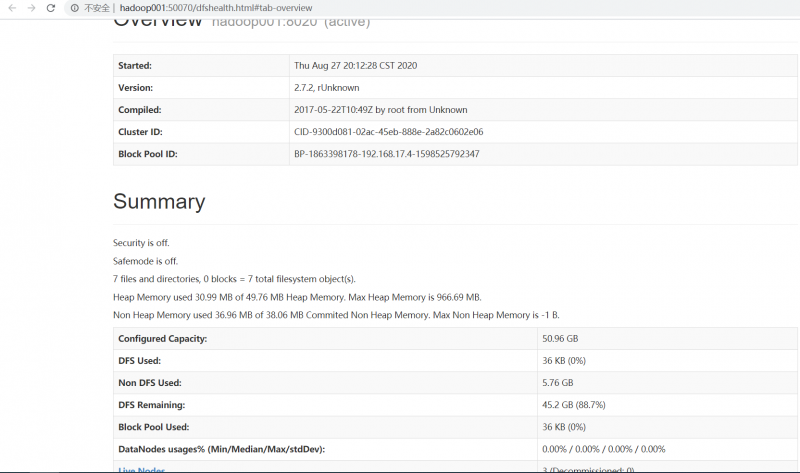
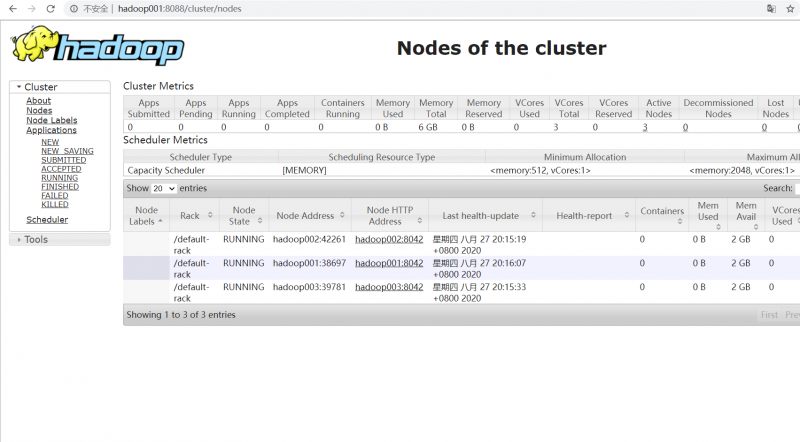
重点:注意集群同步!!!在搭建环境的过程中并没有太大问题,但由于版本原因,有一些命令执行方式不同,之前使用centos7配置完成过,但是这一次配置反而出现了点小插曲,结点在服务器上都能看到,浏览器就是访问不出来,curl也可以,后来我将时间同步,为了方便启动,结点都放在hadoop001,然后就成了~~
以上是 d3doop学习之路(1) 的全部内容, 来源链接: utcz.com/p/50284.html