前端国际化系列之汉字翻译与替换
大乐视的美国 Bigbang 终于进行了,从6月份得知我们云的全线产品要开发英文版之后,到现在,将近 4 个月,将手上的N个系统,全部做了英文版的了,觉得还是需要总结一下的。
我们的国际化,首先是做的英文版,后期还要做台湾版、香港版、俄罗斯版,尽量第一次的时候累点,以后轻松点。
国际化,首先就是汉字的翻译了,如下图,国际友人肯定看不懂汉字。
里面的N多汉字,除了读库之外的,都需要进行汉字翻译。
除了库里的文案,网页里面的汉字还分如下几种
- JSP 界面渲染的文案
- JS 渲染的文案
- 前后端分离,html 界面的文案
这些汉字都需要进行翻译,为了保证翻译的一致性,集体聘请了第三方的翻译团队,由各产品线线提供自己产品线的中文词库,统一进行翻译。
注:我们的 css 没有在 :before :after 等伪类中写中文,故 CSS 无需处理。
1、词库抽取
JSP 界面以及 Java 里的文案,由后端 Java 工程师处理。后端的架构师,封装了一个 jar 文件,会将 jsp、Java 等文件中的词库抽取成 Excel。
我也是这个思路,写了一个 node 程序(le-translate),遍历产品线所有的 JS、Html 文件,抽出成词库列表到 Excel,思路如下:
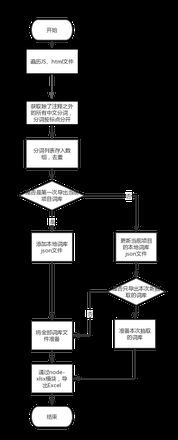
node控制台运行如下:
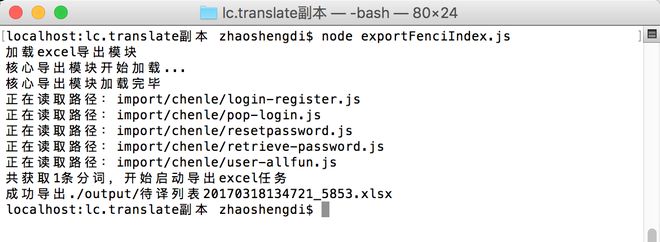
导出的 Excel 结果如下:
词库导出来提交给翻译团队了,然后就等着拿到翻译结果,需要进行具体的替换了。
2、JS 文字替换
无数次的经验、教训告诉我,我们的 JS 代码,只能有一份,来做动态切换,不能单独开一个全英文版,要不然维护成本指数上涨,后面再做其余语言版本的话,就无法整了。我们的产品线由于前期的野蛮发展,JS 都是由 jQuery 的架构开发的,写的也是很野蛮,如下:


2、1 做成大 JSON 方式
将最早拿到的翻译结果,通过扩展上面提的那个 le-translate 工程,遍历 Excel、保存 json 文件,修改成 JS 文件,做成配置文件,准备修改具体的业务 JS 代码。
第一想法就是,人力挨个把业务JS的中文,换成object键值对请求的形式,例如,将如下代码
content += "<p class='user-table-p'>产品名</p>";
替换为:
// l是根据产品线具体语境动态获取中文or英文content += "<p class='user-table-p'>" + LCTKey.l.addedService.productName + "</p>";
这样的话理论上最好,只修改一遍,以后只维护词库的配置文件即可。
但是这样的话,需要人力去将汉字手动的修改,对应到应有的JSON文件的key值,面对着当时很紧张的工期、我手上将近10个产品线的JS、还有国际化其余的工作,我一阵头晕。
这种方式适合新开发的产品线,在后来的官网改版中,我们使用了这种方法,但是注意,这样的话,会使想代码变得可读性非常差,因为好多都走了配置文件。所以,建议在代码后面加上中文注释。例如:
content += "<p class='user-table-p'>" + LCTKey.l.addedService.productName + "</p>";// 产品名...
2、2 补救式的 LCT 方式
上面所述,抽取大JSON的方式,不适合我们一下子修改 N 多旧产品线,我想了一个投机的方式,即以中文为 KEY 值,在 le-translate 产品线中扩展了功能,遍历 JS 文件,把中文分词,使用了LCT() 包起来,如下图:


如上代码,在中文环境下 LCT() 方法,直接返回中文,在英文环境下,返回对应的英文值。
这样的话,可以使用正则替换+node io操作,将JS里面90%以上的中文分词处理掉,剩下的极少数不好被正则处理的,手动检查处理,比单个处理快了N倍。
这个方式,优点是十分快速、保持了语义化,缺点有如下两个
- 1、性能小有损耗
使用 function 调用的方式,比使用键值对调用的方式,耗时要长 50%——200% 不等,不过我们最低兼容到 IE9,而且绝大部分产品线,仅需要兼容到IE11就行,JS引擎都已经非常快,就算是最大的一个业务 JS,我们测试对比发现,总执行延迟,不超过 10-20 毫秒,性能的损耗,可以忽略
- 2、维护不方便
由于配置文件使用了中文为 KEY 值,所有以后如果需要修改中文文案的话,不仅要修改 key-value 里面英文的 value,同时还需修改中文的key,增加了维护的成本。
不过我们的产品线都已经十分成熟,文案的维护频率很低,还可以接受。
3、html 文字替换
除了有 JSP 架构的系统之外,我们还有前后端分离的 html 界面,html 界面不适合做通过大 JSON、LCT 方法等异步获取文案的方式,那样的话,会使界面闪烁,十分影响用户体验,可以做的,只能是再保存一份英文的 html 文件。
于是乎,又扩展了一下 le-translate 工程,加上了翻译 html 的功能,根据词库,直接将中文 html 翻译成英文 html,单独部署。
4、借助百度翻译,提前拿到词库
上面提到很多次词库,开发过程中遇到了一个问题,集团聘请的翻译团队,因接到的翻译需求太大,返回翻译结果无法保证。
工期不能等,于是,又又又扩展了 le-translate 工程,通过 npm 的 request 模块,借助了百度翻译的 API,批量将分词进行翻译,10 秒钟可以翻译 1000 条。
虽然一些专业术语翻译不尽靠谱,但总体上还算可以继续调试,发现后续问题,深度国际化。
文案算是替换完了,本来以为国际化没多少工作量了,慢慢才发现,挑战刚刚开始。
以上是 前端国际化系列之汉字翻译与替换 的全部内容, 来源链接: utcz.com/z/264284.html