网络字体反爬之pyspider爬取起点中文小说
这段时间正在看爬虫框架-pyspider,觉得这种网站用框架还是很方便的,所以今天就给大家带来这篇---起点中文网小说爬取。可视化我们放到下一集。
加vx:tanzhouyiwan或qq群813622576和大家免费分享Python学习资料哦!
安装使用
安装和基本使用请查看pyspider中文文档,我们这篇主要不是介绍pyspider哦。Mac安装的过程中出现了一些问题,请看Mac安装pycurl失败,装好以后使用pyspider all启动。然后打开浏览器输入:http://localhost:5000/
创建以后,我们就开始分析并编写起点爬虫了。
爬虫编写
打开起点中文网(https://www.qidian.com/),选择全部作品并按照字数排序
右键检查元素,因为是静态网页,所以我们就直接解析网页元素就行了,可以使用BeautifulSoup、PyQuery、xpath或者正在表达式。我习惯用xpath,所以就采这个坑了。
Chrome可自动生成xpath
但是生成的大部分情况下都不是很合适,比如/html/body/div[2]/div[5]/div[2]/div[2]/div/ul/li[1]/div[2]/h4/a,你看这有多长,还是自己写吧,chrome浏览器可以帮我们验证xpath这个是很方便的,有的人是按照xpathhelper插件,我觉得原生就很好用了, CTRL+F
按照此方式我们匹配到小说名、作者、更新状态、更新时间、字数信息然后存储到数据库。
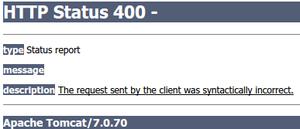
pyspider这个可视化调试的功能确实非常方便,但是我们看到了什么?框框?字数竟然是框框?我就懵逼了
网页元素里看到的竟然也是这个???我不死心,再看看网页源码
好像有些什么编码,但是为什么xpath查出来的是框框的,我百思不得骑姐,试了各种方式发现确实是方框,肿么办捏?我考虑可以把获取到的元素的html源码打印出来,然后再提取一下,是不是可以呢?
OK,得到我们需要的数据了,但是这也不是小说字数呀,这就是我写这篇文章的原因了,我们看到上面元素查看截图中的font-face了,里面有一些.ttf、.woff,这些我们应该知道是字体文件,下载下来看一下
这到底是什么鬼?不明白,那就问谷哥和度姐吧,然后我就知道了字体反爬这个概念,涨姿势呀!我明白了一个道理,要想涨姿势,就得多尝试,不然你怎么能知道还有这种姿势呢?我的意思大家都懂吧,然后我就找到了fonttools这个python库,但是还是走了很多弯路,里面提供的命令行识别不了,最后还是通过源码调试找到了getBestCmap这个接口
下载woff字体文件,然后通过BytesIO转化为内存文件,使用TTFont处理
看到打印的结果了吗?只不过对应的数字变成了英文,我们自己定义一个字典对应一下就行了
字体搞定了,那最初我们需要的数据都有了
调试成功了,启动我们的工程抓取吧
接下来是pyspider的坑(主要还是不熟悉)
首先要存储数据,我们把detail_page函数最后的print换成return就行了,在pyspider的爬虫回调函数中,return的数据将会记录在默认数据库中,默认数据库在哪里?pyspider会创建一个data目录,以Mac为例在~/data/result.db
我们在界面上看到的数据都记录在这里,我在调试的过程中发现想要删除已创建的工程非常麻烦,网上搜到的都是把group改成delete,status改成stop,然后24个小时候会删除,可以通过修改配置时间来删除,但是很麻烦,我们直接在数据库里删除岂不是更方便
还有一个task.db和result.db,result的就是我们return以后里面会写入数据
result字段里面就是我们return的值,task.db里面是我们每次访问的时候记录的url信息,为什么嘞?pyspider中有一个很方便的功能,就是过滤已爬取的网页
这个age配置的意思就是10天内再遇到这个任务就会忽略掉,所以我们在上面一个网页中获取其他的网页链接进行访问的时候,不用担心会循环访问。但是,这里又出现了另外一个问题
我们最后是通过先访问字体链接,然后解析字数,再进行存储,我本来以为起点的文字字体是每次请求的时候随机生成的,每次都不一样,结果后来发现总共也就生成了五种,这就出现了一个问题,同样的请求不会被访问,也就是当第二次出现这个字体文件的时候,我们的请求不会被处理,那么就没法解析存储了,我在网上查了怎么去除这个请求的过滤限制,没找到,可能是我没检索到有效信息吧。但是发现一个有用的信息,pyspider是通过taskid来判断重复的,就是我们在task.db中看到的taskid
这个taskid是怎么来的呢?我们在crawl函数源码中看到
taskid是url的md5码,而且在crawl的参数中如果传递了taskid,那么它就不会自动生成taskid了,那就到我灵机一动的时候了
在crawl中传入taskid参数,这个参数可以搞一个整型每次都加1,这样taskid就不会重复了,这样我们访问起点每页小说数据的时候可以过滤重复的,访问我们的字体信息时就不会过滤了,满足了需求,beautiful!!!
那么本次爬取就结束了,数据有了下次我们再搞可视化。
加vx:tanzhouyiwan或qq群813622576免费分享Python学习资料哦!
以上是 网络字体反爬之pyspider爬取起点中文小说 的全部内容, 来源链接: utcz.com/p/52144.html