Difference in plotting with different matplotlib versions
A colleague of mine handed me a script that is used to collect data from a database and plot it. When I used the script myself, the plots do not look the same, and it has to do with the version of Matplotlib.
The script that does the plotting of the data is quite short:
import matplotlib.pyplot as pltimport csv
import os
from dateutil import parser
def plot(outputDir,plotsDir,FS):
allfiles = os.listdir(outputDir)
flist = []
for f in allfiles:
if 'csv' in f.lower(): flist.append(f)
for f in flist:
with open(outputDir + '/' + f, 'rt') as ff:
data = list(csv.reader(ff,delimiter=FS))
values = [i[2] for i in data[1::]]
values = ['NaN' if v is '' else v for v in values]
time = [parser.parse(i[1]) for i in data[1::]]
plt.xlabel('Time_[UTC]')
plt.plot(time, values)
plt.xticks(rotation=40)
if os.path.isdir(plotsDir) != 1:
os.mkdir(plotsDir, 777)
plt.savefig('{}/{}_Data.png'.format(plotsDir, f[:-4]), bbox_inches='tight', dpi=160)
plt.clf()
outputdir = 'C:/Users/matthijsk/Documents/Test'
plotsdir = outputdir + '/plots'
fs = ','
plot(outputdir, plotsdir, fs)
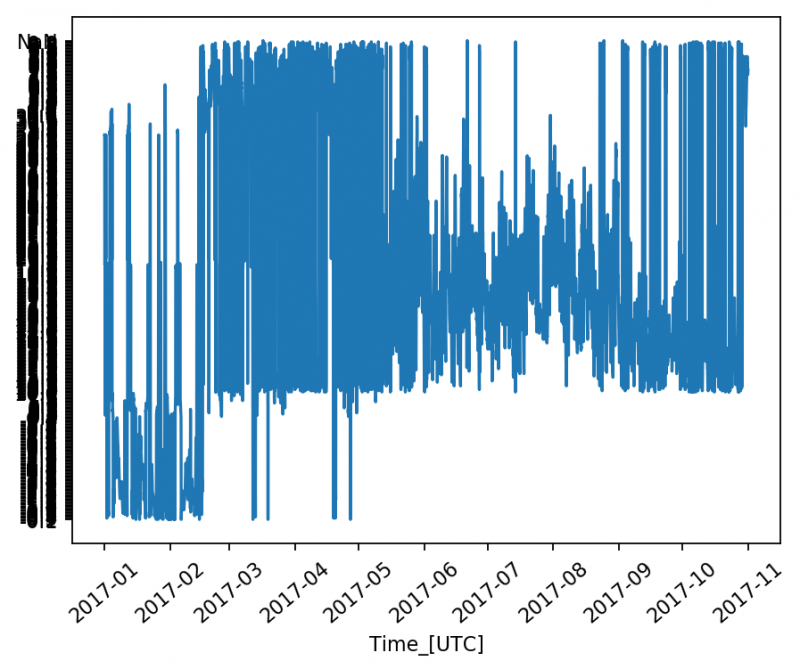
When I run it using Matplotlib version 2.1.0, my image looks like this:
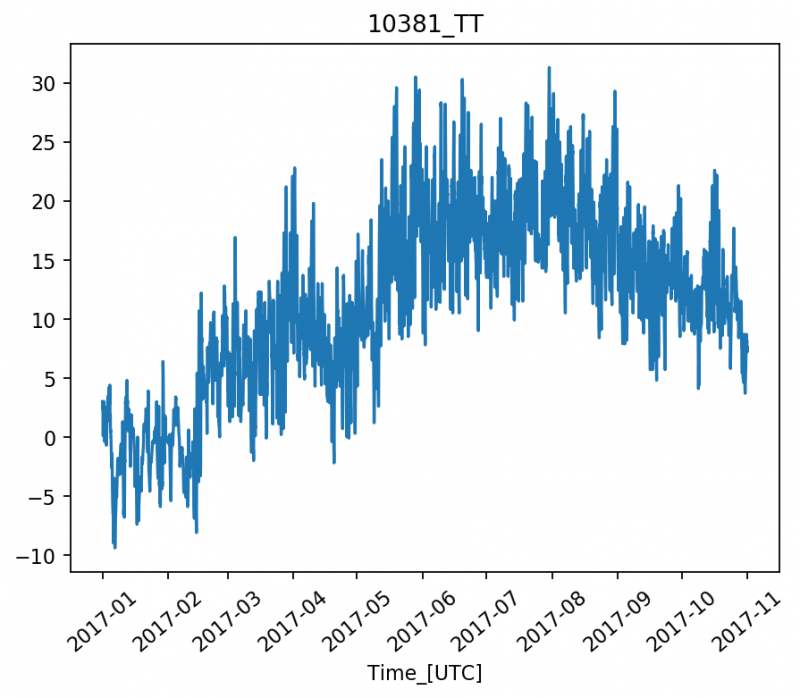
When I run it using Matplotlib version 2.0.2, it looks the way it is supposed to:
The file the script is reading looks like this:
stationNo,dtg(UTC),TT_[°C],source_TT,quality_TT10381,2017-01-01 00:00:00,3.0,ob,na
10381,2017-01-01 01:00:00,3.0,ob,na
10381,2017-01-01 02:00:00,2.4,ob,na
10381,2017-01-01 03:00:00,2.5,ob,na
10381,2017-01-01 04:00:00,2.5,ob,na
10381,2017-01-01 05:00:00,2.3,ob,na
10381,2017-01-01 06:00:00,1.9,ob,na
10381,2017-01-01 07:00:00,1.0,ob,na
10381,2017-01-01 08:00:00,0.1,ob,na
10381,2017-01-01 09:00:00,0.9,ob,na
Can anyone explain me what was changed in Matplotlib that caused this? And apparently I'm doing something wrong with the plotting that is causing this. Can anyone notice a mistake?
I've already tried using
values = [float(value) if value.isnumeric() else None for value in values]But that didn't solve it.
Note: I'd rather not use any non-standard packages (like Pandas) since it's quite a hassle to get approvement to install such packages.
Answer
The data is read in as strings. In matplotlib 2.0 those were automatically converted to floating point numbers such that they can be plotted.
In matplotlib 2.1, categorical plots have been introduced. This now allows for something like
plt.plot(["apple", "banana", "cherry"], [2,1,3])While this is of course great for certain applications, it breaks the previous option of plotting strings that are convertable to floats. I guess this if fine, it just gives the user the responsibility to do the conversion himself.
In this case you would want to do this conversion like
values = [None if v is '' else float(v) for v in values]In case you already have a numpy array: np.array(values).astype(float)
In general, one can use numpy.loadtxt to read files into float arrays. If the file contains dates, usage of a converter as in reading a comma-delimited file with a date object and a float with Python would be possible.
Another option to read in text files would be pandas.read_csv.
以上是 Difference in plotting with different matplotlib versions 的全部内容, 来源链接: utcz.com/a/38477.html