python数据分析实战之信用卡违约风险预测

文章目录
* * * 1、明确需求和目的* 2、 数据收集
* 3、数据预处理
* * 3.1 数据整合
* * 3.1.1 加载相关库和数据集
* 3.1.2 主要数据集概览
* 3.2 数据清洗
* * 3.2.1 多余列的删除
* 3.2.2 数据类型转换
* 3.2.3 缺失值处理
* 3.2.4 异常值处理
* 3.2.5 重复值处理
* 4、数据分析
* * 4.1 相关系数分析
* 5、模型训练
* * 5.1 数据标准化
* 5.2 使用逻辑回归训练
* 5.3 简单优化
* 5.4 使用随机森林训练
* 6、总结
1、明确需求和目的
- 现代社会,越来越多的人使用信用卡进行消费,大部分人使用信用卡之后会按时还款,但仍然有少部分人不能在约定时间进行还款,这大大的增加了银行或者金融机构的风险。
- 本文以某金融机构的历史数据进行建模分析,对客户的还款能力进行评估,以预测新客户是否有信用卡的违约风险,从而决定是否贷款给新客户使用。
- 本文使用AUC(ROC)作为模型的评估标准。
2、 数据收集
- 本文使用的数据集来源于kaggle平台,主要有两份数据集。
- application_train , application_test :训练集和测试集数据,包括每个贷款申请的信息。每笔贷款都有自己的行,并由特性SK_ID_CURR标识。训练集的TARGET 0:贷款已还清,1:贷款未还清。
3、数据预处理
3.1 数据整合
3.1.1 加载相关库和数据集
- 使用的库主要有:pandas、numpy、matplotlib、seaborn
- 使用的数据集:kaggle平台提供的数据集文件
import numpy as np import pandas as pd
import os
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings(\'ignore\')
print(os.listdir("../input/")) # List files available
-------------------------------------------------
[\'sample_submission.csv\', \'credit_card_balance.csv\', \'installments_payments.csv\', \'HomeCredit_columns_description.csv\', \'previous_application.csv\', \'POS_CASH_balance.csv\', \'bureau_balance.csv\', \'application_test.csv\', \'bureau.csv\', \'application_train.csv\']
3.1.2 主要数据集概览
首先看一下训练集数据:
# Training data app_train = pd.read_csv(\'../input/application_train.csv\')
print(\'Training data shape: \', app_train.shape)
--------------------------------------
Training data shape: (307511, 122)
app_train.head()
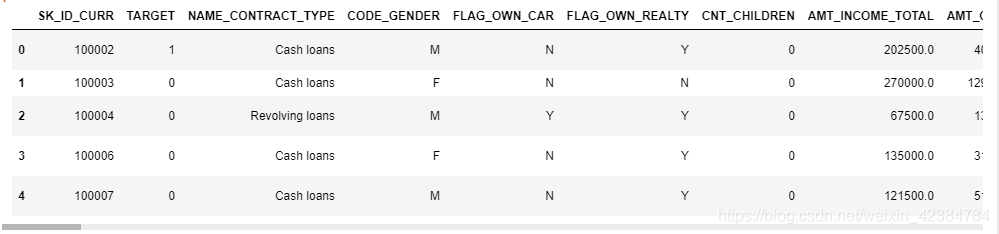
从上面可以看出,训练集数据有122个特征,307511条数据。
再来看一下测试集数据:
# Testing data app_test = pd.read_csv(\'../input/application_test.csv\')
print(\'Testing data shape: \', app_test.shape)
---------------------------------------------
Testing data shape: (48744, 121)
app_test.head()
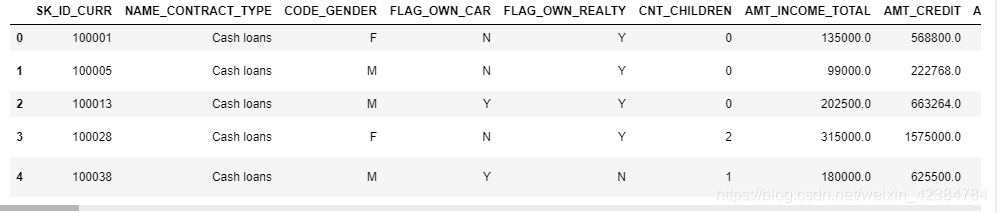
从上面可以看出,测试集数据有121个特征,48744条数据,相比训练集,少了一个特征
TARGET,即我们需要预测的目标值(0表示贷款按时偿还,1表示贷款未按时偿还。)。
检查一下TARGET列的分布,看看每一类贷款的数量:
app_train[\'TARGET\'].value_counts() ----------------------------------------
0 282686
1 24825
Name: TARGET, dtype: int64
可以看出按时还款的类别明显要比未按时还款的类别多, 属于样本不均衡的问题,后续可以考虑使用权重法或采样法等办法来进行解决。
转化成图形更直观的对比一下:
app_train[\'TARGET\'].astype(int).plot.hist()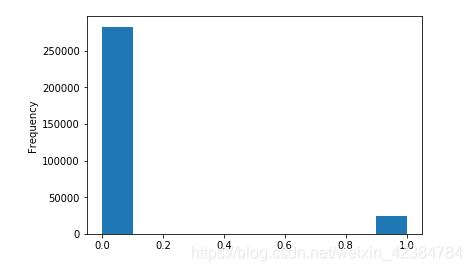
3.2 数据清洗
3.2.1 多余列的删除
首先删除空白值超过一半的列 :
app_train = app_train.dropna(thresh=len(app_train) / 2 , axis=1) 定义一个函数,看一下剩余数据的缺失值情况:
# Function to calculate missing values by column# Funct def missing_values_table(df):
# Total missing values
mis_val = df.isnull().sum()
# Percentage of missing values
mis_val_percent = 100 * df.isnull().sum() / len(df)
# Make a table with the results
mis_val_table = pd.concat([mis_val, mis_val_percent], axis=1)
# Rename the columns
mis_val_table_ren_columns = mis_val_table.rename(
columns = {0 : \'Missing Values\', 1 : \'% of Total Values\'})
# Sort the table by percentage of missing descending
mis_val_table_ren_columns = mis_val_table_ren_columns[
mis_val_table_ren_columns.iloc[:,1] != 0].sort_values(
\'% of Total Values\', ascending=False).round(1)
# Print some summary information
print ("Your selected dataframe has " + str(df.shape[1]) + " columns.\n"
"There are " + str(mis_val_table_ren_columns.shape[0]) +
" columns that have missing values.")
# Return the dataframe with missing information
return mis_val_table_ren_columns
# Missing values statistics missing_values = missing_values_table(app_train)
---------------------------------------------------
Your selected dataframe has 81 columns.
There are 26 columns that have missing values.
missing_values.head(10)
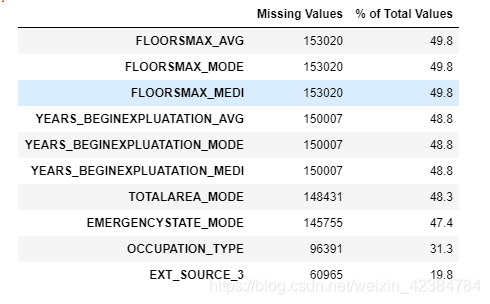
从上面可以看出,还有好几列的值缺失将近50%,缺失比例较高,我们一并将这些列进行删除。当然,也可以选择进行缺失值填充,这里选择删除。
drop_columns = ["FLOORSMAX_AVG","FLOORSMAX_MODE","FLOORSMAX_MEDI","YEARS_BEGINEXPLUATATION_AVG","YEARS_BEGINEXPLUATATION_MODE", "YEARS_BEGINEXPLUATATION_MEDI","TOTALAREA_MODE","EMERGENCYSTATE_MODE"]
app_train = app_train.drop(drop_columns, axis=1)
删除了缺失值较多的列之后,还有其它列的缺失值需要处理,我们可以先进行数据类型转换,后面再统一采用填充的方式进行处理。
3.2.2 数据类型转换
先来看一下各个类型的数据有多少:
# Number of each type of column app_train.dtypes.value_counts()
----------------------------------
int64 41
float64 20
object 12
dtype: int64
object类型的有12个,需要将其转换成数值类型,我们先看一下它们各自的特征类别有多少:
注意 nunique 不考虑空值。
# Number of unique classes in each object column app_train.select_dtypes(\'object\').apply(pd.Series.nunique, axis = 0)
-------------------------------------
NAME_CONTRACT_TYPE 2
CODE_GENDER 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NAME_TYPE_SUITE 7
NAME_INCOME_TYPE 8
NAME_EDUCATION_TYPE 5
NAME_FAMILY_STATUS 6
NAME_HOUSING_TYPE 6
OCCUPATION_TYPE 18
WEEKDAY_APPR_PROCESS_START 7
ORGANIZATION_TYPE 58
dtype: int64
- 标签编码 ( Label Encoding):它给类别一个任意的顺序。分配给每个类别的值是随机的,不反映类别的任何固有方面。所以我们在只有两个类别的时候使用标签编码。例如上面的‘NAME_CONTRACT_TYPE’等,我们就可以使用标签编码。
- 独热编码 (One-Hot Encoding):为分类变量中的每个类别创建一个新列。当类别>2的时候,我们将使用独热编码。例如上面的‘CODE_GENDER’等。当然独热编码的缺点也很明显,就是特征可能会暴增,但我们可以使用PCA或其他降维方法来减少维数。
对于类别只有2个的特征,我们使用 Label Encoding 进行数据的转换(注意测试集也同样需要进行转换):
from sklearn.preprocessing import LabelEncoder # Create a label encoder object
le = LabelEncoder()
le_count = 0
# Iterate through the columns
for col in app_train:
if app_train[col].dtype == \'object\':
# If 2 or fewer unique categories
if len(list(app_train[col].unique())) <= 2:
# Train on the training data
le.fit(app_train[col])
# Transform both training and testing data
app_train[col] = le.transform(app_train[col])
app_test[col] = le.transform(app_test[col])
# Keep track of how many columns were label encoded
le_count += 1
print(\'%d columns were label encoded.\' % le_count)
-------------------------------------------------
3 columns were label encoded.
从上面可以看出3个类别全部完成了转换,接下来使用 One-Hot Encoding
进行剩余数据的转换,此处选择使用pandas的get_dummies()函数,直接映射为数值型(测试集一并进行转换):
# one-hot encoding of categorical variables app_train = pd.get_dummies(app_train)
app_test = pd.get_dummies(app_test)
print(\'Training Features shape: \', app_train.shape)
print(\'Testing Features shape: \', app_test.shape)
----------------------------------------------------
Training Features shape: (307511, 182)
Testing Features shape: (48744, 239)
从上面可以看出,此时测试集列数多于训练集,因为训练集删除了一些多余的列,我们对两份数据取并集,只需要处理共同拥有的列即可:
train_labels = app_train[\'TARGET\'] # Align the training and testing data, keep only columns present in both dataframes
app_train, app_test = app_train.align(app_test, join = \'inner\', axis = 1)
# Add the target back in
app_train[\'TARGET\'] = train_labels
print(\'Training Features shape: \', app_train.shape)
print(\'Testing Features shape: \', app_test.shape)
------------------------------------------------
Training Features shape: (307511, 179)
Testing Features shape: (48744, 178)
3.2.3 缺失值处理
数据类型转换完成,我们就可以统一进行缺失值处理,可以采用中位数进行填充:
from sklearn.preprocessing import Imputer imputer = Imputer(strategy = \'median\')
train = app_train.drop(columns = [\'TARGET\'])
column_list = train.columns.tolist()
# fit with Training_data, fill both Training_data and Testing_data
imputer.fit(train)
train = imputer.transform(train)
test = imputer.transform(app_test)
train = pd.DataFrame(train, columns = column_list)
app_train = pd.concat([train, app_train[\'TARGET\']], axis=1)
app_test = pd.DataFrame(test, columns = column_list)
print(\'Training data shape: \', app_train.shape)
print(\'Testing data shape: \', app_test.shape)
--------------------------------------------------
Training data shape: (307511, 179)
Testing data shape: (48744, 178)
检查是否还有缺失值:
print(app_train.isnull().sum()) print(app_test.isnull().sum())
需要注意的是,此处"SK_ID_CURR" 经过处理之后变成float类型,需要重新转换成 int类型:
app_train["SK_ID_CURR"] = app_train["SK_ID_CURR"].astype(int) app_test["SK_ID_CURR"] = app_test["SK_ID_CURR"].astype(int)
3.2.4 异常值处理
对年龄进行异常值检查(原始数据为天,需要除以365,并且取负数):
(app_train[\'DAYS_BIRTH\'] / -365).describe() -----------------------------------------------
count 307511.000000
mean 43.936973
std 11.956133
min 20.517808
25% 34.008219
50% 43.150685
75% 53.923288
max 69.120548
Name: DAYS_BIRTH, dtype: float64
看起来很正常,无异常,再看一下在职天数:
app_train[\'DAYS_EMPLOYED\'].describe() -----------------------------------------
count 307511.000000
mean 63815.045904
std 141275.766519
min -17912.000000
25% -2760.000000
50% -1213.000000
75% -289.000000
max 365243.000000
Name: DAYS_EMPLOYED, dtype: float64
最大值为365243天,换算成年即100年,明显不合理,属于异常值。
出于好奇,对异常客户进行分析,看看他们的违约率比其他客户高还是低。
anom = app_train[app_train[\'DAYS_EMPLOYED\'] == 365243] non_anom = app_train[app_train[\'DAYS_EMPLOYED\'] != 365243]
print(\'The non-anomalies default on %0.2f%% of loans\' % (100 * non_anom[\'TARGET\'].mean()))
print(\'The anomalies default on %0.2f%% of loans\' % (100 * anom[\'TARGET\'].mean()))
print(\'There are %d anomalous days of employment\' % len(anom))
-------------------------------------------------------------
The non-anomalies default on 8.66% of loans
The anomalies default on 5.40% of loans
There are 55374 anomalous days of employment
可以看到,这些异常值的客户违约率比其他客户还要低,且数量还不少。
我们需要对异常值进行处理,处理异常值取决于具体情况,没有固定的规则。最安全的方法之一就是将异常值视为缺失值处理,然后在使用算法之前填充它们。这里我们将用(np.nan)填充异常值,然后创建一个新的布尔列,指示该值是否异常。
# Create an anomalous flag column app_train[\'DAYS_EMPLOYED_ANOM\'] = app_train["DAYS_EMPLOYED"] == 365243
# Replace the anomalous values with nan
app_train[\'DAYS_EMPLOYED\'].replace({365243: np.nan}, inplace = True)
同样对测试集进行异常值处理:
app_test[\'DAYS_EMPLOYED_ANOM\'] = app_test["DAYS_EMPLOYED"] == 365243 app_test["DAYS_EMPLOYED"].replace({365243: np.nan}, inplace = True)
print(\'There are %d anomalies in the test data out of %d entries\' % (app_test["DAYS_EMPLOYED_ANOM"].sum(), len(app_test)))
---------------------------------------------------
There are 9274 anomalies in the test data out of 48744 entries
使用中位数对异常值转换后的缺失值进行填充:
from sklearn.preprocessing import Imputer imputer = Imputer(strategy = \'median\')
train = app_train[\'DAYS_EMPLOYED\'].values.reshape(-1, 1)
imputer.fit(train)
train = imputer.transform(app_train[\'DAYS_EMPLOYED\'].values.reshape(-1, 1))
test = imputer.transform(app_test[\'DAYS_EMPLOYED\'].values.reshape(-1, 1))
app_train[\'DAYS_EMPLOYED\'] = train
app_test[\'DAYS_EMPLOYED\'] = test
print(app_train[\'DAYS_EMPLOYED\'].describe())
print(app_test[\'DAYS_EMPLOYED\'].describe())
---------------------------------------------
count 307511.000000
mean -2251.606131
std 2136.193492
min -17912.000000
25% -2760.000000
50% -1648.000000
75% -933.000000
max 0.000000
Name: DAYS_EMPLOYED, dtype: float64
count 48744.000000
mean -2319.063639
std 2102.150130
min -17463.000000
25% -2910.000000
50% -1648.000000
75% -1048.000000
max -1.000000
Name: DAYS_EMPLOYED, dtype: float64
从上面可以看出,已经没有异常值了。
3.2.5 重复值处理
看一下有没有重复值,有则直接删除:
print(app_train.duplicated().sum()) # 查看重复值的数量 ------------------------------------------
0
没有重复值,不需要进行处理。
4、数据分析
4.1 相关系数分析
使用.corr方法计算每个变量与目标之间的相关系数。
相关系数并不是表示特征“相关性”的最佳方法,但它确实让我们了解了数据中可能存在的关系。
# Find correlations with the target and sort correlations = app_train.corr()[\'TARGET\'].sort_values()
# Display correlations
print(\'Most Positive Correlations:\n\', correlations.tail(15))
print(\'\nMost Negative Correlations:\n\', correlations.head(15))
---------------------------------------------------------------
Most Positive Correlations:
OCCUPATION_TYPE_Laborers 0.043019
FLAG_DOCUMENT_3 0.044346
REG_CITY_NOT_LIVE_CITY 0.044395
FLAG_EMP_PHONE 0.045982
NAME_EDUCATION_TYPE_Secondary / secondary special 0.049824
REG_CITY_NOT_WORK_CITY 0.050994
DAYS_ID_PUBLISH 0.051457
CODE_GENDER_M 0.054713
DAYS_LAST_PHONE_CHANGE 0.055218
NAME_INCOME_TYPE_Working 0.057481
REGION_RATING_CLIENT 0.058899
REGION_RATING_CLIENT_W_CITY 0.060893
DAYS_EMPLOYED 0.063368
DAYS_BIRTH 0.078239
TARGET 1.000000
Name: TARGET, dtype: float64
Most Negative Correlations:
EXT_SOURCE_2 -0.160295
EXT_SOURCE_3 -0.155892
NAME_EDUCATION_TYPE_Higher education -0.056593
CODE_GENDER_F -0.054704
NAME_INCOME_TYPE_Pensioner -0.046209
DAYS_EMPLOYED_ANOM -0.045987
ORGANIZATION_TYPE_XNA -0.045987
AMT_GOODS_PRICE -0.039623
REGION_POPULATION_RELATIVE -0.037227
NAME_CONTRACT_TYPE -0.030896
AMT_CREDIT -0.030369
FLAG_DOCUMENT_6 -0.028602
NAME_HOUSING_TYPE_House / apartment -0.028555
NAME_FAMILY_STATUS_Married -0.025043
HOUR_APPR_PROCESS_START -0.024166
Name: TARGET, dtype: float64
从上面看出,和目标值有较大正相关性的有 DAYS_BIRTH 这个特征,有较大负相关性的有 EXT_SOURCE_2 和 EXT_SOURCE_3
这两个特征,可以进一步进行分析:
plt.figure(figsize=(10, 8)) # KDE图中按时偿还的贷款
sns.kdeplot(app_train.loc[app_train[\'TARGET\'] == 0, \'DAYS_BIRTH\'] / -365, label = \'target == 0\')
# KDE图中未按时偿还的贷款
sns.kdeplot(app_train.loc[app_train[\'TARGET\'] == 1, \'DAYS_BIRTH\'] / -365, label = \'target == 1\')
plt.xlabel(\'Age (years)\')
plt.ylabel(\'Density\')
plt.title(\'Distribution of Ages\')
plt.show()
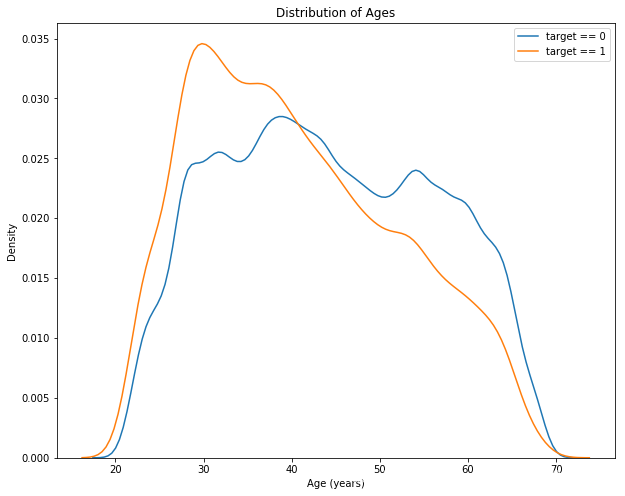
target ==
1曲线向范围的较年轻端倾斜,说明随着客户年龄的增长,他们往往会更经常地按时偿还贷款。虽然这不是一个显著的相关性(-0.07相关系数),但这个变量很可能在机器学习模型中有用,因为它确实会影响目标。
对于其余两个特征,也可以进行相应的分析,并可以利用这几个特征进行特征工程的选择。(本文为简单起见,未进行特征工程)
5、模型训练
5.1 数据标准化
- 在使用算法之前,进行 数据标准化处理,将数据集中的特征转换成相同的量纲,从而消除不同量纲对算法造成的负面影响。
from sklearn.preprocessing import Imputer, MinMaxScaler imputer = Imputer(strategy = \'median\')
scaler = MinMaxScaler(feature_range = [0,1])
train = app_train.drop(columns = [\'TARGET\'])
scaler.fit(train)
train = scaler.transform(train)
test = scaler.transform(app_test)
print(\'Training data shape: \', train.shape)
print(\'Testing data shape: \', test.shape)
--------------------------------------------
Training data shape: (307511, 183)
Testing data shape: (48744, 183)
5.2 使用逻辑回归训练
- 直接使用简单的逻辑回归
from sklearn.linear_model import LogisticRegression log_reg = LogisticRegression()
log_reg.fit(train, train_labels)
log_reg_pred = log_reg.predict_proba(test)[:, 1]
submit = app_test[[\'SK_ID_CURR\']]
submit[\'TARGET\'] = log_reg_pred
submit.head()
submit.to_csv(\'log_reg_baseline.csv\', index = False)
提交之后,分数如下:
Private Score:0.72683, Public Score:0.73322- 使用网格交叉验证计算出最佳参数的逻辑回归:
from sklearn.linear_model import LogisticRegression from sklearn.model_selection import GridSearchCV
param_grid = {\'C\' : [0.01,0.1,1,10,100],
\'penalty\' : [\'l1\',\'l2\']}
log_reg = LogisticRegression()
grid_search = GridSearchCV(log_reg, param_grid, scoring = \'roc_auc\', cv = 5)
grid_search.fit(train, train_labels)
# Train on the training data
log_reg_best = grid_search.best_estimator_
log_reg_pred = log_reg_best.predict_proba(test)[:, 1]
submit = app_test[[\'SK_ID_CURR\']]
submit[\'TARGET\'] = log_reg_pred
submit.head()
submit.to_csv(\'log_reg_baseline_gridsearch2.csv\', index = False)
使用交叉验证,效果有一点提升,分数如下:
Private Score:0.72770, Public Score:0.734525.3 简单优化
增加领域知识特征,我们可以创建几个特性,试图捕捉我们认为对于判断客户是否会拖欠贷款可能很重要的信息。
- CREDIT_INCOME_PERCENT: 信贷金额占客户收入的百分比
- ANNUITY_INCOME_PERCENT: 贷款年金占客户收入的百分比
- CREDIT_TERM: 以月为单位支付的期限(因为年金是每月到期的金额)
- DAYS_EMPLOYED_PERCENT: 就职天数占客户年龄的百分比
app_train_domain = app_train.copy() app_train[\'CREDIT_INCOME_PERCENT\'] = app_train_domain[\'AMT_CREDIT\'] / app_train_domain[\'AMT_INCOME_TOTAL\']
app_train[\'ANNUITY_INCOME_PERCENT\'] = app_train_domain[\'AMT_ANNUITY\'] / app_train_domain[\'AMT_INCOME_TOTAL\']
app_train[\'CREDIT_TERM\'] = app_train_domain[\'AMT_ANNUITY\'] / app_train_domain[\'AMT_CREDIT\']
app_train[\'DAYS_EMPLOYED_PERCENT\'] = app_train_domain[\'DAYS_EMPLOYED\'] / app_train_domain[\'DAYS_BIRTH\']
测试集进行同样处理:
app_test_domain = app_test.copy() app_test[\'CREDIT_INCOME_PERCENT\'] = app_test_domain[\'AMT_CREDIT\'] / app_test_domain[\'AMT_INCOME_TOTAL\']
app_test[\'ANNUITY_INCOME_PERCENT\'] = app_test_domain[\'AMT_ANNUITY\'] / app_test_domain[\'AMT_INCOME_TOTAL\']
app_test[\'CREDIT_TERM\'] = app_test_domain[\'AMT_ANNUITY\'] / app_test_domain[\'AMT_CREDIT\']
app_test[\'DAYS_EMPLOYED_PERCENT\'] = app_test_domain[\'DAYS_EMPLOYED\'] / app_test_domain[\'DAYS_BIRTH\']
增加领域特征之后,再次使用简单的逻辑回归进行训练(交叉验证太耗时间,用简单的比较看看效果):
from sklearn.linear_model import LogisticRegression log_reg = LogisticRegression()
log_reg.fit(train, train_labels)
log_reg_pred = log_reg.predict_proba(test)[:, 1]
submit = app_test[[\'SK_ID_CURR\']]
submit[\'TARGET\'] = log_reg_pred
submit.head()
submit.to_csv(\'log_reg_baseline_domain.csv\', index = False)
增加领域特征之后,效果有一点提升,分数如下:
Private Score:0.72805, Public Score:0.734345.4 使用随机森林训练
- 增加领域特征之后,使用随机森林训练,看看效果怎么样
from sklearn.ensemble import RandomForestClassifier # 随机森林
random_forest = RandomForestClassifier(n_estimators = 100, random_state = 50, verbose = 1, n_jobs = -1)
random_forest.fit(train, train_labels)
predictions = random_forest.predict_proba(test)[:, 1]
submit = app_test[[\'SK_ID_CURR\']]
submit[\'TARGET\'] = predictions
submit.to_csv(\'random_forest_baseline_domain.csv\', index = False)
使用随机森林,效果比逻辑回归还要差一些:
Private Score:0.70975, Public Score:0.70120 6、总结
- 本文仅仅使用一个数据集进行模型训练,并使用逻辑回归和随机森林分别预测,并通过简单优化提升了模型效果。
- 如果进一步进行特征分析,并且使用其它数据集进行训练的话,应该会得到更好的训练模型。
以上是 python数据分析实战之信用卡违约风险预测 的全部内容, 来源链接: utcz.com/z/387611.html