webpack常用构建优化策略小结
简介
读了《深入浅出webpack》总结一下常用的webpack的构建优化策略,可通过以下手段来提升项目构建时的速度
更精准的loader规则
将loader规则写清楚
仅让需要处理的文件,进入loader处理环节,如下
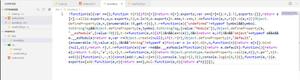
rules: [{
// 正则尽量准确
test: /\.js$/,
// 使用缓存,缓存后在文件未改变时编译会更快(缓存查找原理见补充1)
use: ['babel-loader?cacheDirectory'],
// 指定需要处理的目录
include: path.resolve(__dirname, 'src')
// 理论上只有include就够了,但是某些情况需要排除文件的时候可以用这个,排除不需要处理文件
// exclude: []
}]
更精准的查找目录
将查找路径设置精确
理论上我们项目的第三方依赖均应在自己的工程的node_modules下,所以我们可以设置查找目录,减少node的默认查找(默认查找方式见补充2)
module.exports = {
resolve: {
// 指定当前目录下的node_modules目录
modules: [path.resolve(__dirname, 'node_modules')]
}
}
更精准的扩展名
数量更多类型的文件尽量放在前面
平时写代码,我们都习惯直接写文件名,而不去写扩展名,那么解析则按照下面属性进行解析
module.exports = {
extensions: ['.js', '.jsx', '.ts', '.tsx'],
}
默认值
extensions: [".js", ".json"]
使用动态链接库预编译大模块
使用动态链接库,提前编译大模块
原理请见补充3
新建一个文件webpack_dll.config.js,内容如下
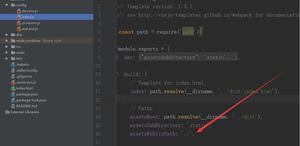
const path = require('path');
const webpack = require('webpack');
// 复用的大模块放在这里,这样每次都不需要重新编译了
const vendors = [
'react',
'react-dom',
'lodash'
];
module.exports = {
mode: 'development',
output: {
path: path.resolve(__dirname, './dist'),
filename: '[name].js',
library: '[name]',
},
entry: {
vendors,
},
plugins: [
new webpack.DllPlugin({
path: path.resolve(__dirname, './dist/manifest.json'),
name: '[name]',
}),
],
};
执行webpack --config webpack_dll.config.js进行首次编译(如果更新版本需要再次编译)
然后在你的webpack配置文件中引入manifest.json
plugins: [
new webpack.DllReferencePlugin({
manifest: require('./dist/manifest.json')
})
],
多进程处理文件
使用HappyPack同时处理多个loader编译任务
为了发挥多核CPU电脑的功能,利用HappyPack将任务分发给多个子进程并发执行
const path = require('path');
const HappyPack = require('happypack');
// 共享5个进程池
const happyThreadPool = HappyPack.ThreadPool({ size: 5 });
module.exports = {
entry: './src/index.js',
output: {
filename: 'bundle.js',
path: path.resolve(__dirname, 'dist'),
},
module: {
// noParse: [/react\.production\.min\.js$/],
rules: [{
test: /\.js$/,
// 和下面插件id一直,happypack才可以找到
use: ['happypack/loader?id=babel'],
include: path.resolve(__dirname, 'src')
}]
},
plugins: [
// 插件可以实例化多个
new HappyPack({
// 与上面对应
id: 'babel',
// 实际要使用的loader
loaders: ['babel-loader?cacheDirectory'],
// 默认开启进程数
threads: 3,
// 是否允许happyPack打印日志
verbose: true,
// 共享进程数,如果你使用超过一个happyplugin,官方建议共享进程池
threadPool: happyThreadPool
})
],
};
原理见补充4
多进程压缩文件
使用ParallelUglifyPlugin多进程同时压缩文件
ParallelUglifyPlugin是在UglifyJS基础上,增加了多进出处理的能力,加快了压缩速度
import ParallelUglifyPlugin from 'webpack-parallel-uglify-plugin';
module.exports = {
plugins: [
new ParallelUglifyPlugin({
test,
include,
exclude,
cacheDir,
workerCount,
sourceMap,
uglifyJS: {
},
uglifyES: {
}
}),
],
};
减少监听文件
减少监听文件
原理见补充5
当我们使用webpack的watch功能进行文件监听时,更好的方式是控制监听目录,如下,排除node_modules减少对该目录监听,减少编译所需要循环的文件,提高检查速度
module.export = {
watchOptions: {
ignored: /node_modules/
}
}
其他没那么重要的优化
更精准的mainFields
默认的这个值查找方式见官网点击此处
看了下react和lodash,只有一个main,目前来看使用es6看来还不普遍,所以这个值目前可能不太重要
module.exports = {
resolve: {
mainFields: ['main']
}
}
第三方库映射
为什么这个不重要,我发现react直接导出的index.js则是根据环境判断使用哪份代码,目测来看并不需要进行循环依赖的处理
通过依赖,则可以直接使用打包后代码,而不需webpack去循环依赖
resolve: {
mainFields: ["main"],
alias: {
'react': path.resolve(__dirname, './node_modules/react/cjs/react.production.min.js')
}
}
不使用inline模式的devServer
原理见补充6
默认情况下,应用程序启用内联模式(inline mode)。这意味着一段处理实时重载的脚本被插入到你的包(bundle)中,并且构建消息将会出现在浏览器控制台。
当使用inline模式时,devServer会向每个Chunk中注入一段重载的脚本代码,但是其实一个页面只需要一次,所以当Chunk过多时,可以将inline设置为false
module.export = {
devServer: {
inline: false
}
}
补充
补充1-cacheDirectory原理
当有设置cacheDirectory时,指定的目录将用来缓存loader的执行结果。之后的 webpack 构建,将会尝试读取缓存,来避免在每次执行时,可能产生的、高性能消耗的Babel重新编译过程。如果设置了一个空值 (loader: 'babel-loader?cacheDirectory') 或者 true (loader: babel-loader?cacheDirectory=true),loader 将使用默认的缓存目录 node_modules/.cache/babel-loader,如果在任何根目录下都没有找到 node_modules 目录,将会降级回退到操作系统默认的临时文件目录。
补充2-node的默认查找方式
- 查找当前目录下的node_modules目录,看是否有匹配项,如有,命中文件
- 寻找父目录的下的node_modules,如有,命中文件
- 按照这个规则一直往父目录搜索直到到根目录下的node_modules
补充3-动态链接库思想
大量项目中可以复用的模块只需要被编译一次,在之后的构建过程中被动态链接库包含的模块将不会重新编译,而是直接使用动态链接库中的代码。(注:如果升级依赖的模块版本,需要重新编译动态链接库)
补充4-HappyPack原理
webpack构建中,需要大量的loader转换操作,很耗时,由于nodejs是单线程的,如果想更好利用cpu的多核能力,可以开启多个进程,同时对文件进行处理;可以看到在配置文件中,我们每次将文件交给happypack-loader去处理,然后由happypack去调度来执行文件的处理(happypack采用哪个loaders进行处理,是通过id知道的)
补充5-文件监听原理
webpack会从入口触发,将所有的依赖项放到一个list里边,然后每次修改文件内容,回去遍历整个list里边的文件,看是否有编辑时间的变化,如果有的话则进行编译
补充6-自动刷新原理
- 向要开发的网页中注入代理客户端代码,通过代理客户端去刷新整个页面(默认)
- 将要开发的网页放进一个iframe,通过刷新iframe去看刷新效果
以上是 webpack常用构建优化策略小结 的全部内容, 来源链接: utcz.com/z/349426.html