对齐文本文件中的列
我有一个包含用户登录数据的纯文本文件:
dtrapani HCPD-EPD-3687 Mon 05/13/2013 9:47:01.72dlibby HCPD-COS-4611 Mon 05/13/2013 9:49:34.55
lmurdoch HCPD-SDDEB-3736 Mon 05/13/2013 9:50:38.48
lpatrick HCPD-WIN7-015 Mon 05/13/2013 9:57:44.57
mlay HCPD-WAR-3744 Mon 05/13/2013 10:00:07.94
eyoung HCPD-NLCC-0645 Mon 05/13/2013 10:03:01.83
我正在尝试打印左对齐和右对齐列中的数据:
dtrapani HCPD-EPD-3687 Mon 05/13/2013 9:47:01.72dlibby HCPD-COS-4611 Mon 05/13/2013 9:49:34.55
lmurdoch HCPD-SDDEB-3736 Mon 05/13/2013 9:50:38.48
lpatrick HCPD-WIN7-015 Mon 05/13/2013 9:57:44.57
mlay HCPD-WAR-3744 Mon 05/13/2013 10:00:07.94
eyoung HCPD-NLCC-0645 Mon 05/13/2013 10:03:01.83
我怎样才能做到这一点?
这是我到目前为止的代码:
with open(r'C:\path\to\logons.txt', 'r') as f: for line in f:
data = line.strip()
print(data)
原文由 cstafford 发布,翻译遵循 CC BY-SA 4.0 许可协议
回答:
我会选择新的(er)打印格式化程序(假设您的字段是一致的)。打印/格式语句非常易于使用,可以在 此处 找到。由于您的数据可以看作是一个列表,您可以调用一次格式并提供正确的格式化程序数据,您将获得输出。这比 ljust 或 rjust 具有更细粒度的控制,但缺点是您需要知道传入的数据是一致的。
with open(r'C:\path\to\logons.txt', 'r') as f: for line in f:
data = line.split() # Splits on whitespace
print '{0[0]:<15}{0[1]:<15}{0[2]:<5}{0[3]:<15}{0[4]:>15}'.format(data)
原文由 Jeff Langemeier 发布,翻译遵循 CC BY-SA 3.0 许可协议
回答:
str.ljust(width, [fillchar=" "]) ( http://docs.python.org/2/library/stdtypes.html#str.ljust ) 看起来像你所追求的。打印到最大长度时左对齐每个字段 + 一点点。
对于与您的示例匹配的最后一个字段,您需要右对齐而不是使用 rjust。
原文由 Sysyphus 发布,翻译遵循 CC BY-SA 3.0 许可协议
回答:
python文本对齐打印,使用 DebugInfo 模块
pip install DebugInfopython代码:
from DebugInfo.DebugInfo import *画板 = 调试模板()
with open(r'C:\path\to\logons.txt', 'r') as f:
for line in f:
data = line.strip()
画板.添加一行(data) # 把data数据添加到画板的表格中
画板.展示表格() # 展示表格的内容,就是对齐的
就以你给的数据为例,输出的效果是下面这样的: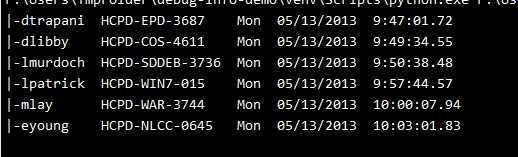
事实上,即使你的文本中存在中英混合的情况,也不用担心, 例如稍微修改你的数据如下:
dtrapani -> 张dtrapani
lmurdoch -> lmurdoch总
新的数据在打印的时候依然是对齐的,如下: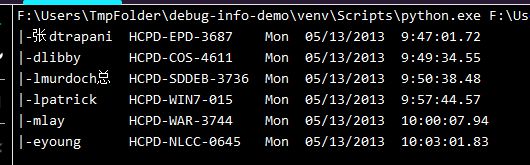
事实上,DebugInfo模型也是支持日文,韓文的对齐的,例如下面的对齐效果也是DebugInfo模块输出的: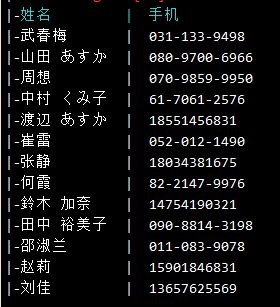
所以,你可以放心的将你的文本交给DebugInfo模块,它来负责帮你对齐打印.
以上是 对齐文本文件中的列 的全部内容, 来源链接: utcz.com/p/938670.html