python使用webbrowser时候,for循环打印都成功但是网页只打开最后一行
python">#代码如下import webbrowser
import time
for url in open("urls.txt"):
try:
print(url)
webbrowser.open(url)
time.sleep(1)
except:
continue
#urls.txt 内容如下,没有空格和空行,只有三行网址https://www.baidu.com
https://www.4399.com
https://www.bing.com
运行结果是三个网址都打印出来了,系统默认浏览器打开了4个tab,前三个为空,只有第四个成功打开了最后一行的链接。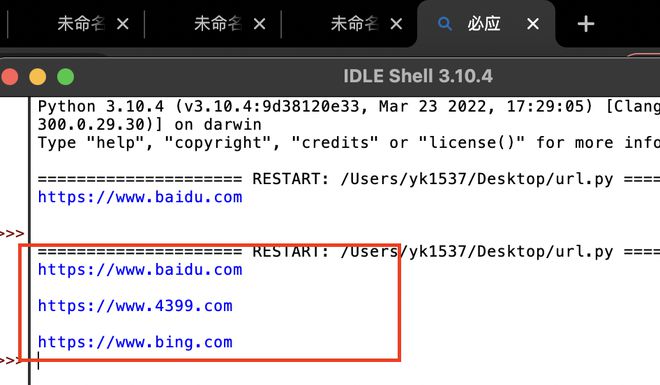
问题:不明白为什么只有最后一个链接能成功,按print来看三个链接都有读到。
以上是 python使用webbrowser时候,for循环打印都成功但是网页只打开最后一行 的全部内容, 来源链接: utcz.com/p/938523.html