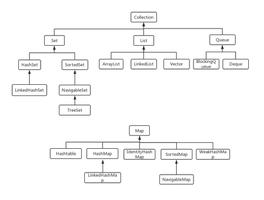
python字典解析式中能否进行聚合运算、缓存结果,或类似scala的map一样进行递归数据处理?

测试数据:
[['a','测试1'],
['a','测试1'],
['a','测试2'],
['b','测试1'],
['b','测试2'],
['c','测试1'],]
希望能够通过字典解析式对数据按照第一列进行聚合并生成如下结果:
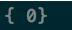
{'a':{'测试1','测试2'},'b':{'测试1','测试2'},'c':{'测试1'},}
字典解析式应该怎么做?
我发现字典解析式列表解析式面对1对1的问题时非常好用,但是在数据聚合的时候多对1的关系时该怎么办,能不能达到scala的reducebykey的效果
回答:
问题解决了,python可以像scala的map和reduce一样进行数据聚合:
from functools import reduce# 测试数据
oidproductlist = [['a', '测试1'],
['a', '测试1'],
['a', '测试2'],
['b', '测试1'],
['b', '测试2'],
['c', '测试1'], ]
oidproductdict = {key: reduce(lambda x, y: x | y, [{element1[1]} for element1 in oidproductlist if key == element1[0]]) for key in {element[0] for element in oidproductlist}}
回答:
字典推导式做不出的,要一次迭代聚合分组,怎么说也要辅助变量,做是可以做的,只是不能一行推导式实现。
或者你可以使用numpy包的groupby分组函数,这个包提供了很多数据处理工具
以上是 python字典解析式中能否进行聚合运算、缓存结果,或类似scala的map一样进行递归数据处理? 的全部内容, 来源链接: utcz.com/p/937654.html