详解C/C++性能优化背后的方法论TMAM
前言
性能优化的难点在于找出关键的性能瓶颈点,如果不借助一些工具辅助定位这些瓶颈是非常困难的,例如:c++程序通常大家可能都会借助perf /bcc这些工具来寻找存在性能瓶颈的地方。性能出现瓶颈的原因很多比如 CPU、内存、磁盘、架构等。本文就仅仅是针对CPU调优进行调优,即如何榨干CPU的性能,将CPU吞吐最大化。(实际上CPU出厂的时候就已经决定了它的性能,我们需要做的就是让CPU尽可能做有用功),所以针对CPU利用率优化,实际上就是找出我们写的不够好的代码进行优化。
一、示例
先敬上代码:
#include <stdlib.h>
#define CACHE_LINE __attribute__((aligned(64)))
struct S1
{
int r1;
int r2;
int r3;
S1 ():r1 (1), r2 (2), r3 (3){}
} CACHE_LINE;
void add(const S1 smember[],int members,long &total) {
int idx = members;
do {
total += smember[idx].r1;
total += smember[idx].r2;
total += smember[idx].r3;
}while(--idx);
}
int main (int argc, char *argv[]) {
const int SIZE = 204800;
S1 *smember = (S1 *) malloc (sizeof (S1) * SIZE);
long total = 0L;
int loop = 10000;
while (--loop) { // 方便对比测试
add(smember,SIZE,total);
}
return 0;
}
注:代码逻辑比较简单就是做一个累加操作,仅仅是为了演示。
编译+运行:
g++ cache_line.cpp -o cache_line ; task_set -c 1 ./cache_line
下图是示例cache_line在CPU 1核心上运行,CPU利用率达到99.7%,此时CPU基本上是满载的,那么我们如何知道这个cpu运行cache_line 服务过程中是否做的都是有用功,是否还有优化空间?

有的同学可能说,可以用perf 进行分析寻找热点函数。确实是可以使用perf,但是perf只能知道某个函数是热点(或者是某些汇编指令),但是没法确认引起热点的是CPU中的哪些操作存在瓶颈,比如取指令、解码、.....
如果你还在为判断是CPU哪些操作导致服务性能瓶颈而不知所措,那么这篇文章将会你给你授道解惑。本文主要通过介绍自顶向下分析方法(TMAM)方法论来快速、精准定位CPU性能瓶颈以及相关的优化建议,帮助大家提升服务性能。为了让大家更好的理解本文介绍的方法,需要准备些知识。
二、CPU 流水线介绍
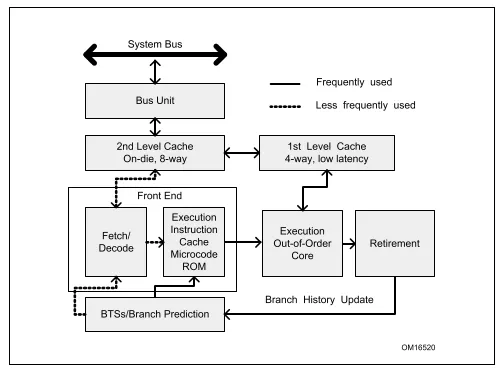
现代的计算机一般都是冯诺依曼计算机模型都有5个核心的组件:运算、存储、控制、输入、输出。本文介绍的方法与CPU有关,CPU执行过程中涉及到取指令、解码、执行、回写这几个最基础的阶段。最早的CPU执行过程中是一个指令按照以上步骤依次执行完之后,才能轮到第二条指令即指令串行执行,很显然这种方式对CPU各个硬件单元利用率是非常低的,为了提高CPU的性能,Intel引入了多级流水、乱序执行等技术提升性能。一般intel cpu是5级流水线,也就是同一个cycle 可以处理5个不同操作,一些新型CPU中流水线多达15级,下图展示了一个5级流水线的状态,在7个CPU指令周期中指令1,2,3已经执行完成,而指令4,5也在执行中,这也是为什么CPU要进行指令解码的目的:将指令操作不同资源的操作分解成不同的微指令(uops),比如ADD eax,[mem1] 就可以解码成两条微指令,一条是从内存[mem1]加载数据到临时寄存器,另外一条就是执行运算,这样就可以在加载数据的时候运算单元可以执行另外一条指令的运算uops,多个不同的资源单元可以并行工作。
CPU内部还有很多种资源比如TLB、ALU、L1Cache、register、port、BTB等而且各个资源的执行速度各不相同,有的速度快、有的速度慢,彼此之间又存在依赖关系,因此在程序运行过程中CPU不同的资源会出现各种各样的约束,本文运用TMAM更加客观的分析程序运行过程中哪些内在CPU资源出现瓶颈。
三、自顶向下分析(TMAM)
TMAM 即 Top-down Micro-architecture Analysis Methodology自顶向下的微架构分析方法。这是Intel CPU 工程师归纳总结用于优化CPU性能的方法论。TMAM 理论基础就是将各类CPU各类微指令进行归类从大的方面先确认可能出现的瓶颈,再进一步下钻分析找到瓶颈点,该方法也符合我们人类的思维,从宏观再到细节,过早的关注细节,往往需要花费更多的时间。这套方法论的优势在于:
- 即使没有硬件相关的知识也能够基于CPU的特性优化程序
- 系统性的消除我们对程序性能瓶颈的猜测:分支预测成功率低?CPU缓存命中率低?内存瓶颈?
- 快速的识别出在多核乱序CPU中瓶颈点
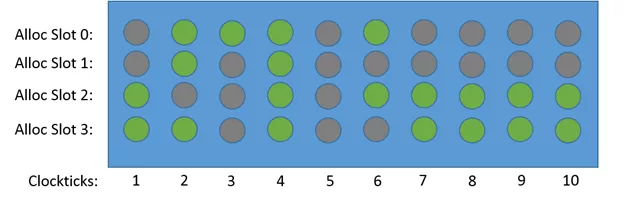
TMAM 评估各个指标过程中采用两种度量方式一种是cpu时钟周期(cycle[6]),另外一种是CPU pipeline slot[4]。该方法中假定每个CPU 内核每个周期pipeline都是4个slot即CPU流水线宽是4。下图展示了各个时钟周期四个slot的不同状态,注意只有Clockticks 4 ,cycle 利用率才是100%,其他的都是cycle stall(停顿、气泡)。
3.1、基础分类
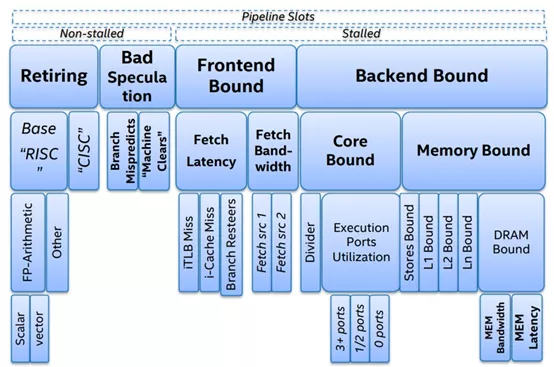
TMAM将各种CPU资源进行分类,通过不同的分类来识别使用这些资源的过程中存在瓶颈,先从大的方向确认大致的瓶颈所在,然后再进行深入分析,找到对应的瓶颈点各个击破。在TMAM中最顶层将CPU的资源操作分为四大类,接下来介绍下这几类的含义。
3.1.1、Retiring
Retiring表示运行有效的uOps 的pipeline slot,即这些uOps[3]最终会退出(注意一个微指令最终结果要么被丢弃、要么退出将结果回写到register),它可以用于评估程序对CPU的相对比较真实的有效率。理想情况下,所有流水线slot都应该是"Retiring"。100% 的Retiring意味着每个周期的 uOps Retiring数将达到最大化,极致的Retiring可以增加每个周期的指令吞吐数(IPC)。需要注意的是,Retiring这一分类的占比高并不意味着没有优化的空间。例如retiring中Microcode assists的类别实际上是对性能有损耗的,我们需要避免这类操作。
3.1.2、Bad Speculation
Bad Speculation表示错误预测导致浪费pipeline 资源,包括由于提交最终不会retired的 uOps 以及部分slots是由于从先前的错误预测中恢复而被阻塞的。由于预测错误分支而浪费的工作被归类为"错误预测"类别。例如:if、switch、while、for等都可能会产生bad speculation。
3.1.3、Front-End-Boun
Front-End 职责:
- 取指令
- 将指令进行解码成微指令
- 将指令分发给Back-End,每个周期最多分发4条微指令
Front-End Bound表示处理其的Front-End 的一部分slots没法交付足够的指令给Back-End。Front-End 作为处理器的第一个部分其核心职责就是获取Back-End 所需的指令。在Front-End 中由预测器预测下一个需要获取的地址,然后从内存子系统中获取对应的缓存行,在转换成对应的指令,最后解码成uOps(微指令)。Front-End Bound 意味着,会导致部分slot 即使Back-End 没有阻塞也会被闲置。例如因为指令cache misses引起的阻塞是可以归类为Front-End Bound。
3.1.4、Back-End-Bound
Back-End 的职责:
- 接收Front-End 提交的微指令
- 必要时对Front-End 提交的微指令进行重排
- 从内存中获取对应的指令操作数
- 执行微指令、提交结果到内存
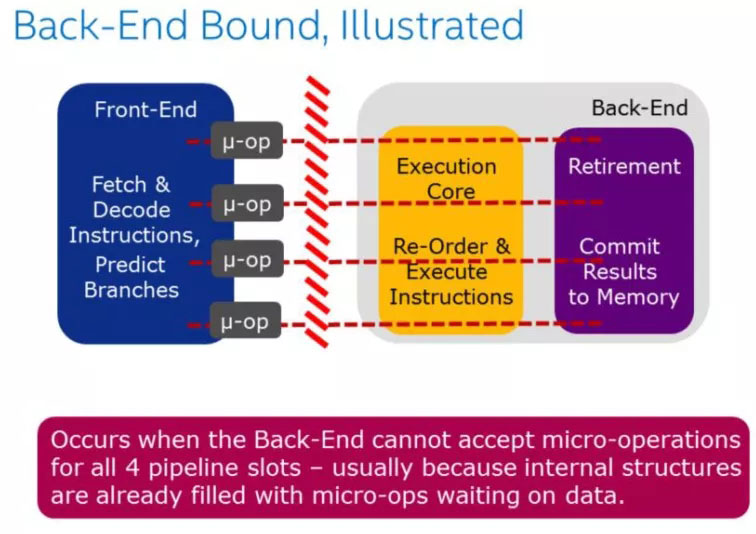
Back-End Bound 表示部分pipeline slots 因为Back-End缺少一些必要的资源导致没有uOps交付给Back-End。
Back-End 处理器的核心部分是通过调度器乱序地将准备好的uOps分发给对应执行单元,一旦执行完成,uOps将会根据程序的顺序返回对应的结果。例如:像cache-misses 引起的阻塞(停顿)或者因为除法运算器过载引起的停顿都可以归为此类。此类别可以在进行细分为两大类:Memory-Bound 、Core Bound。
归纳总结一下就是:
Front End Bound = Bound in Instruction Fetch -> Decode (Instruction Cache, ITLB)
Back End Bound = Bound in Execute -> Commit (Example = Execute, load latency)
Bad Speculation = When pipeline incorrectly predicts execution (Example branch mispredict memory ordering nuke)
Retiring = Pipeline is retiring uops
一个微指令状态可以按照下图决策树进行归类:
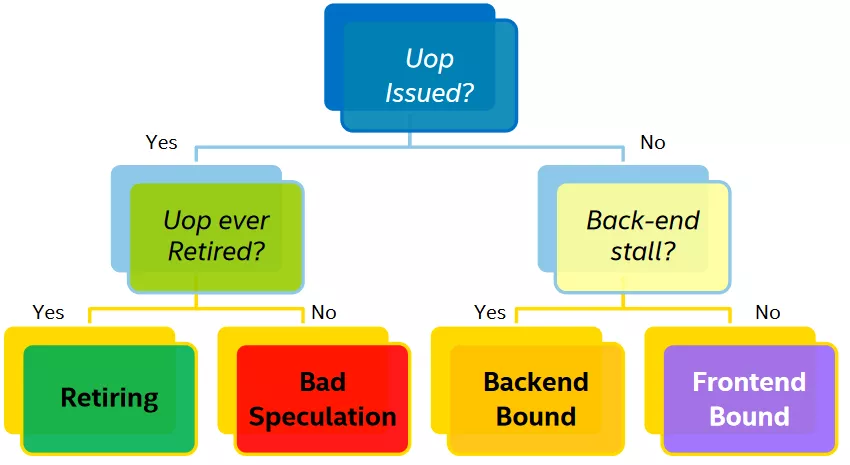
上图中的叶子节点,程序运行一定时间之后各个类别都会有一个pipeline slot 的占比,只有Retiring 的才是我们所期望的结果,那么每个类别占比应该是多少才是合理或者说性能相对来说是比较好,没有必要再继续优化?intel 在实验室里根据不同的程序类型提供了一个参考的标准:
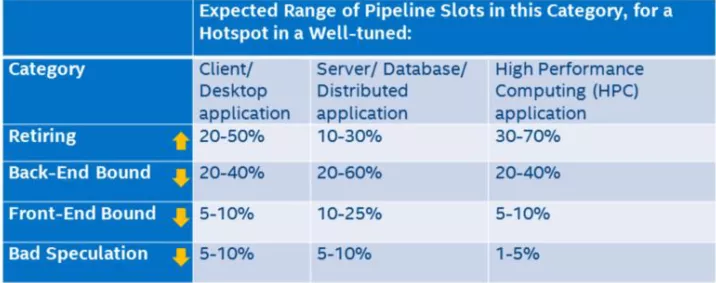
只有Retiring 类别是越高越好,其他三类都是占比越低越好。如果某一个类别占比比较突出,那么它就是我们进行优化时重点关注的对象。
目前有两个主流的性能分析工具是基于该方法论进行分析的:Intel vtune(收费而且还老贵~),另外一个是开源社区的pm-tools。
有了上面的一些知识之后我们在来看下开始的示例的各分类情况:
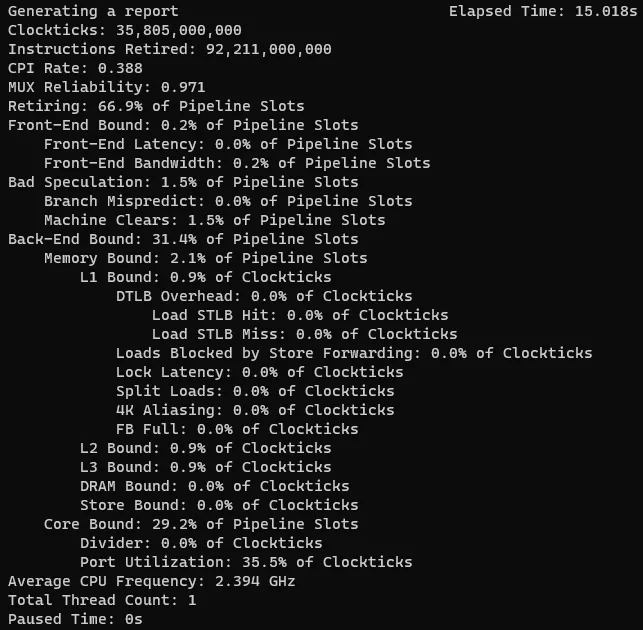
虽然各项指标都在前面的参照表的范围之内,但是只要retiring 没有达到100%都还是有可优化空间的。上图中显然瓶颈在Back-End。
3.3、如何针对不同类别进行优化?
使用Vtune或者pm-tools 工具时我们应该关注的是除了retired之外的其他三个大分类中占比比较高,针对这些较为突出的进行分析优化。另外使用工具分析工程中需要关注MUX Reliability (多元分析可靠性)这个指标,它越接近1表示当前结果可靠性越高,如果低于0.7 表示当前分析结果不可靠,那么建议加长程序运行时间以便采集足够的数据进行分析。下面我们来针对三大分类进行分析优化。
3.3.1、Front-End Bound
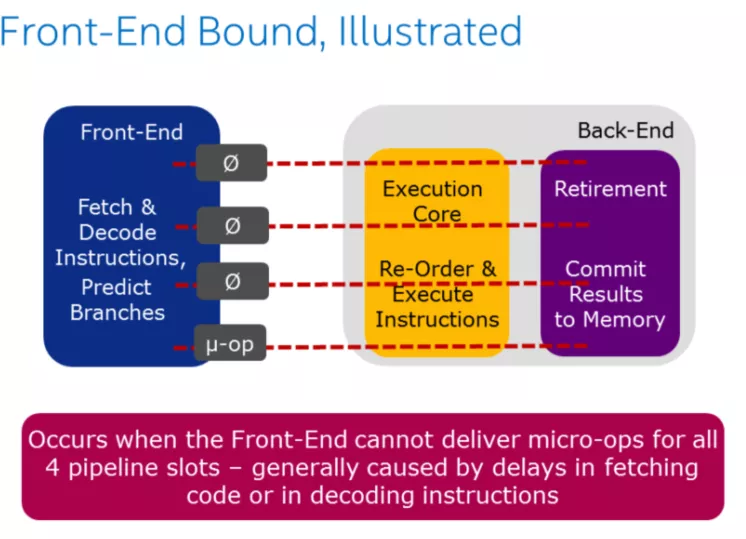
上图中展示了Front-End的职责即取指令(可能会根据预测提前取指令)、解码、分发给后端pipeline, 它的性能受限于两个方面一个是latency、bandwidth。对于latency,一般就是取指令(比如L1 ICache、iTLB未命中或解释型编程语言python\java等)、decoding (一些特殊指令或者排队问题)导致延迟。当Front-End 受限了,pipeline利用率就会降低,下图非绿色部分表示slot没有被使用,ClockTicks 1 的slot利用率只有50%。对于BandWidth 将它划分成了MITE,DSB和LSD三个子类,感兴趣的同学可以通过其他途径了解下这三个子分类。
3.3.1.1 于Front-End的优化建议:代码尽可能减少代码的footprint7:
C/C++可以利用编译器的优化选项来帮助优化,比如GCC -O* 都会对footprint进行优化或者通过指定-fomit-frame-pointer也可以达到效果;
充分利用CPU硬件特性:宏融合(macro-fusion)
宏融合特性可以将2条指令合并成一条微指令,它能提升Front-End的吞吐。 示例:像我们通常用到的循环:
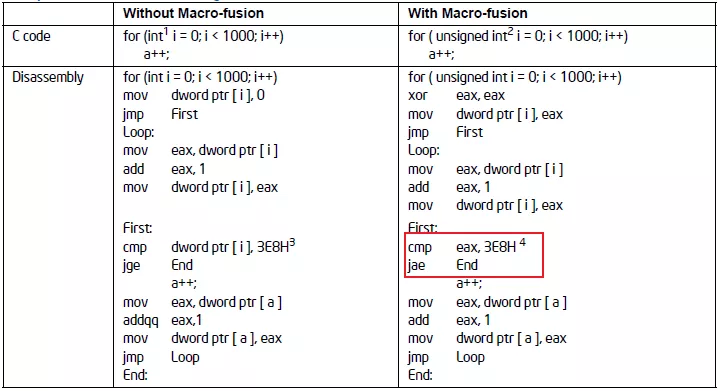
所以建议循环条件中的类型采用无符号的数据类型可以使用到宏融合特性提升Front-End 吞吐量。
调整代码布局(co-locating-hot-code):
①充分利用编译器的PGO 特性:-fprofile-generate -fprofile-use
②可以通过__attribute__ ((hot)) __attribute__ ((code))来调整代码在内存中的布局,hot的代码
在解码阶段有利于CPU进行预取。
其他优化选项,可以参考:GCC优化选项GCC通用属性选项
分支预测优化
① 消除分支可以减少预测的可能性能:比如小的循环可以展开比如循环次数小于64次(可以使用GCC选项 -funroll-loops)
② 尽量用if 代替:?,不建议使用a=b>0? x:y因为这个是没法做分支预测的
③ 尽可能减少组合条件,使用单一条件比如:if(a||b) {}else{}这种代码CPU没法做分支预测的
④对于多case的switch,尽可能将最可能执行的case 放在最前面
⑤ 我们可以根据其静态预测算法投其所好,调整代码布局,满足以下条件:
前置条件,使条件分支后的的第一个代码块是最有可能被执行的
bool is_expect = true;
if(is_expect) {
// 被执行的概率高代码尽可能放在这里
} else {
// 被执行的概率低代码尽可能放在这里
}
后置条件,使条件分支的具有向后目标的分支不太可能的目标
do {
// 这里的代码尽可能减少运行
} while(conditions);
3.3.2、Back-End Bound
这一类别的优化涉及到CPU Cache的使用优化,CPU cache[14]它的存在就是为了弥补超高速的 CPU与DRAM之间的速度差距。CPU 中存在多级cache(register\L1\L2\L3) ,另外为了加速virtual memory address 与 physical address 之间转换引入了TLB。
如果没有cache,每次都到DRAM中加载指令,那这个延迟是没法接受的。
3.3.2.1 优化建议:
- 调整算法减少数据存储,减少前后指令数据的依赖提高指令运行的并发度
- 根据cache line调整数据结构的大小
- 避免L2、L3 cache伪共享
(1)合理使用缓存行对齐
CPU的缓存是弥足珍贵的,应该尽量的提高其使用率,平常使用过程中可能存在一些误区导致CPU cache有效利用率比较低。下面来看一个不适合进行缓存行对齐的例子:
#include <stdlib.h>
#define CACHE_LINE
struct S1
{
int r1;
int r2;
int r3;
S1 ():r1 (1), r2 (2), r3 (3){}
} CACHE_LINE;
int main (int argc, char *argv[])
{
// 与前面一致
}
下面这个是测试效果:

做了缓存行对齐:
#include <string.h>
#include <stdio.h>
#define CACHE_LINE __attribute__((aligned(64)))
struct S1 {
int r1;
int r2;
int r3;
S1(): r1(1),r2(2),r3(3){}
} CACHE_LINE;
int main(int argc,char* argv[]) {
// 与前面一致
}
测试结果:

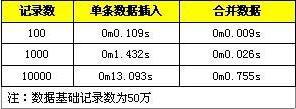
通过对比两个retiring 就知道,这种场景下没有做cache 对齐缓存利用率高,因为在单线程中采用了缓存行导致cpu cache 利用率低,在上面的例子中缓存行利用率才3*4/64 = 18%。缓存行对齐使用原则:
- 多个线程存在同时写一个对象、结构体的场景(即存在伪共享的场景)
- 对象、结构体过大的时候
- 将高频访问的对象属性尽可能的放在对象、结构体首部
(2)伪共享
前面主要是缓存行误用的场景,这里介绍下如何利用缓存行解决SMP 体系下的伪共享(false shared)。多个CPU同时对同一个缓存行的数据进行修改,导致CPU cache的数据不一致也就是缓存失效问题。为什么伪共享只发生在多线程的场景,而多进程的场景不会有问题?这是因为linux 虚拟内存的特性,各个进程的虚拟地址空间是相互隔离的,也就是说在数据不进行缓存行对齐的情况下,CPU执行进程1时加载的一个缓存行的数据,只会属于进程1,而不会存在一部分是进程1、另外一部分是进程2。
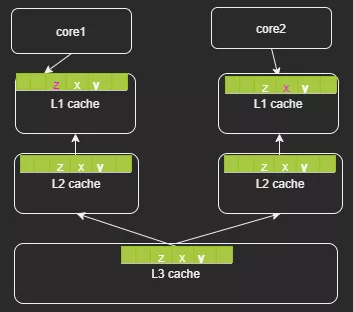
(上图中不同型号的L2 cache 组织形式可能不同,有的可能是每个core 独占例如skylake)
伪共享之所以对性能影响很大,是因为他会导致原本可以并行执行的操作,变成了并发执行。这是高性能服务不能接受的,所以我们需要对齐进行优化,方法就是CPU缓存行对齐(cache line align)解决伪共享,本来就是一个以空间换取时间的方案。比如上面的代码片段:
#define CACHE_LINE __attribute__((aligned(64)))
struct S1 {
int r1;
int r2;
int r3;
S1(): r1(1),r2(2),r3(3){}
} CACHE_LINE;
所以对于缓存行的使用需要根据自己的实际代码区别对待,而不是人云亦云。
3.3.3、Bad Speculation分支预测
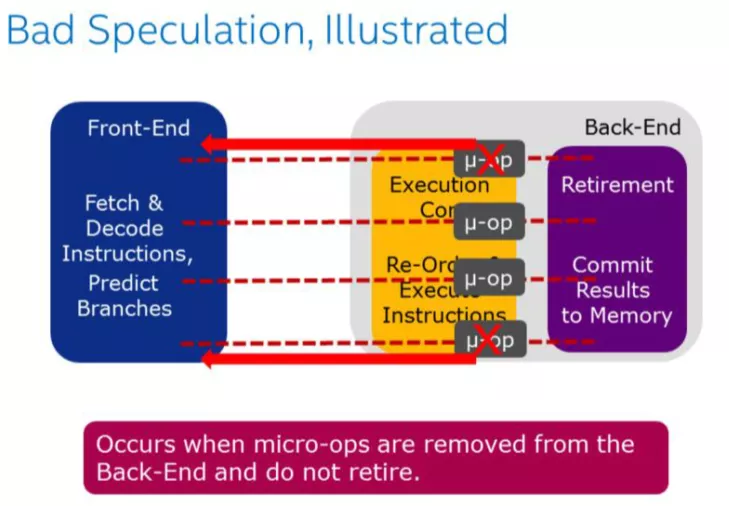
当Back-End 删除了微指令,就出现Bad Speculation,这意味着Front-End 对这些指令所作的取指令、解码都是无用功,所以为什么说开发过程中应该尽可能的避免出现分支或者应该提升分支预测准确度能够提升服务的性能。虽然CPU 有BTB记录历史预测情况,但是这部分cache 是非常稀缺,它能缓存的数据非常有限。
分支预测在Font-End中用于加速CPU获取指定的过程,而不是等到需要读取指令的时候才从主存中读取指令。Front-End可以利用分支预测提前将需要预测指令加载到L2 Cache中,这样CPU 取指令的时候延迟就极大减小了,所以这种提前加载指令时存在误判的情况的,所以我们应该避免这种情况的发生,c++常用的方法就是:
在使用if的地方尽可能使用gcc的内置分支预测特性(其他情况可以参考Front-End章节)
#define likely(x) __builtin_expect(!!(x), 1) //gcc内置函数, 帮助编译器分支优化
#define unlikely(x) __builtin_expect(!!(x), 0)
if(likely(condition)) {
// 这里的代码执行的概率比较高
}
if(unlikely(condition)) {
// 这里的代码执行的概率比较高
}
// 尽量避免远调用
避免间接跳转或者调用
在c++中比如switch、函数指针或者虚函数在生成汇编语言的时候都可能存在多个跳转目标,这个也是会影响分支预测的结果,虽然BTB可改善这些但是毕竟BTB的资源是很有限的。(intel P3的BTB 512 entry ,一些较新的CPU没法找到相关的数据)
四、写在最后
这里我们再看下最开始的例子,采用上面提到的优化方法优化完之后的评测效果如下:
g++ cache_line.cpp -o cache_line -fomit-frame-pointer; task_set -c 1 ./cache_line
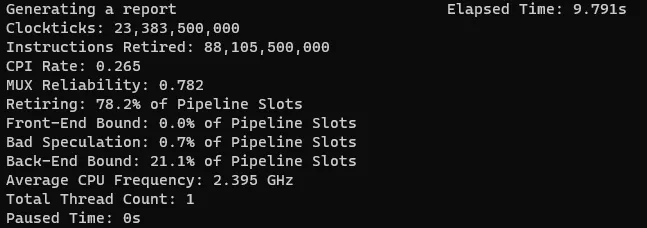
耗时从原来的15s 降低到现在9.8s,性能提升34%:retiring 从66.9% 提升到78.2% ;Back-End bound 从31.4%降低到21.1%
五、CPU知识充电站
[1] CPI(cycle per instruction) 平均每条指令的平均时钟周期个数
[2] IPC (instruction per cycle) 每个CPU周期的指令吞吐数
[3] uOps 现代处理器每个时钟周期至少可以译码 4 条指令。译码过程产生很多小片的操作,被称作微指令(micro-ops, uOps)
[4] pipeline slot pipeline slot 表示用于处理uOps 所需要的硬件资源,TMAM中假定每个 CPU core在每个时钟周期中都有多个可用的流水线插槽。流水线的数量称为流水线宽度。
[5] MIPS(MillionInstructions Per Second) 即每秒执行百万条指令数 MIPS= 1/(CPI×时钟周期)= 主频/CPI
[6]cycle 时钟周期:cycle=1/主频
[7] memory footprint 程序运行过程中所需要的内存大小.包括代码段、数据段、堆、调用栈还包括用于存储一些隐藏的数据比如符号表、调试的数据结构、打开的文件、映射到进程空间的共享库等。
[8] MITEMicro-instruction Translation Engine
[9]DSBDecode stream Buffer 即decoded uop cache
[10]LSDLoop Stream Detector
[11]TMAM理论介绍
[12]CPU Cache
[13]微架构
以上就是详解C/C++ 性能优化背后的方法论TMAM的详细内容,更多关于C/C++ 性能优化TMAM的资料请关注其它相关文章!
以上是 详解C/C++性能优化背后的方法论TMAM 的全部内容, 来源链接: utcz.com/p/246276.html