教你用c++从头开始实现决策树
Python已经成为数据科学的语言之王。大多数新的数据科学家和程序员继续学习Python作为他们的第一门语言。这是有充分理由的;Python具有较浅的学习曲线、强大的社区和丰富的数据科学库生态系统。
我用Python开始了我的数据科学之旅,它仍然是我解决数据科学问题最常用的工具。我很想更好地理解Python从您那里抽象出了什么,以及用性能更高的语言编写更快代码的成本与好处。
为了有代表性地介绍c++,我需要一个代表性的应用程序,c++将是一个合适的选择。从头实现一个分类决策树分类器似乎是一个适当的挑战。这已经被证明是一个测试但有益的学习旅程,我想分享一些我在这个过程中的主要经验。
关键经验:
- c++很少提供代码提示或保护
- 尽早做出好的架构决策
- 从长远来看,编写测试将为您节省时间
- 语言的在线社区非常有价值
- 可移植性是一个重要的考虑因素
在Python中,你可以做很多事情。您可以创建一个变量,随心所欲地改变它的类型,然后不必担心如何处理它。这能让你在执行过程中改变想法。非常适合动态迭代原型设计。
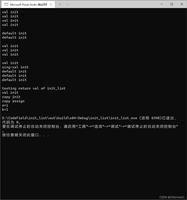
在c++中,您必须预先决定您希望您的变量是什么类型。您还必须预先决定希望函数返回的类型。如果您声明错误,例如试图从一个已经声明为返回整数的函数返回一个字符串,那么您的进程将会停止。在这种情况下,编译器将阻止您编译程序,通常带有一个令人费解的错误消息。令人沮丧的是,编译器是您的朋友,它会在这个问题导致后续问题之前预先提醒您。在Python中,只有在太晚的时候才发现问题是很常见的,比如在代码投入生产之后。
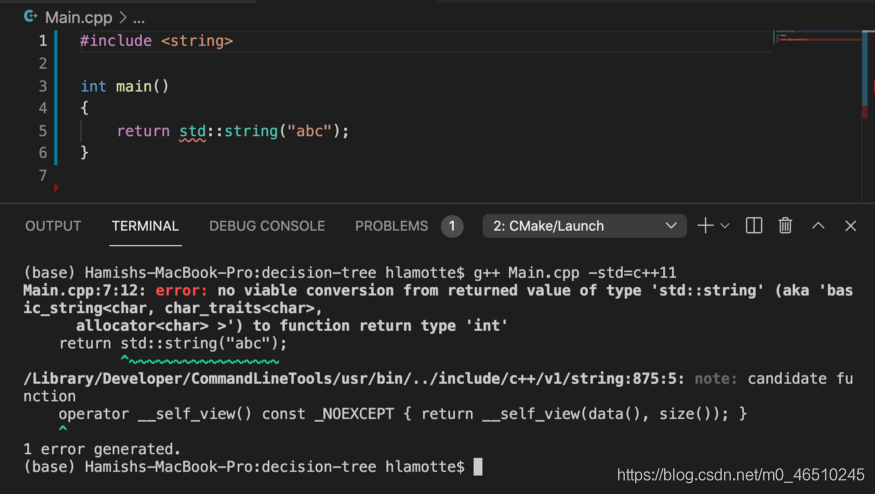
在上面的示例中,编译器捕获定义为返回试图返回字符串的整数的函数。
也有编译器不支持您的情况。访问一个被认为存储在特定内存地址的变量时,可能只收到一个垃圾值,因为该变量已经被删除了。在这里,您通常不会在编译时收到错误,而且很容易在代码中留下错误,而您对此却浑然不觉。
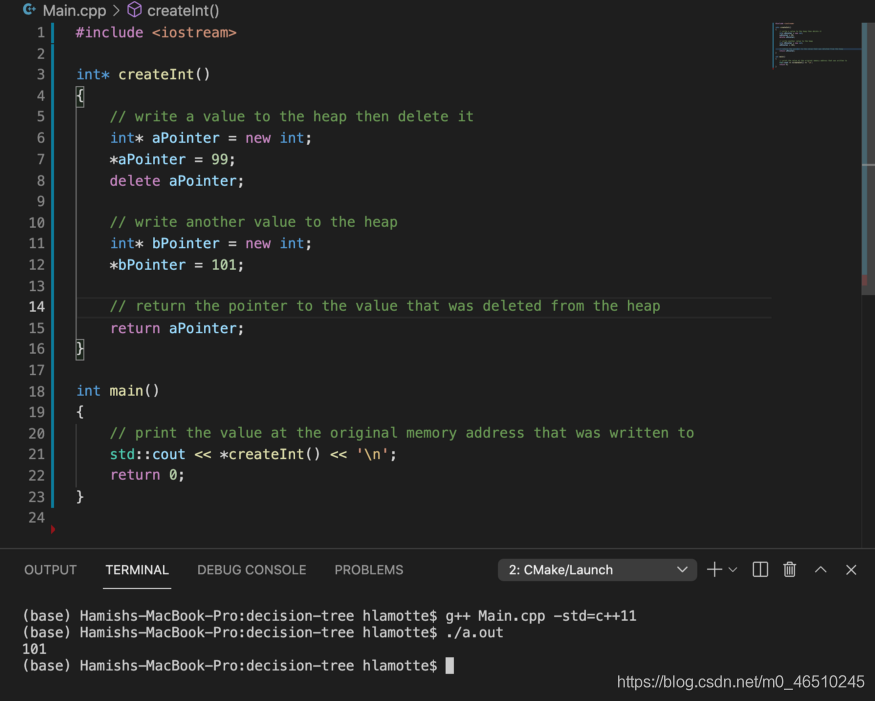
在上面的示例中,即使我们试图访问已被删除的变量的内存地址的值,编译也不会给出错误。
尽早做出好的架构决策
在Python中,很容易在尝试解决问题的早期阶段就开始编写解决方案。由于c++的灵活性和较慢的开发速度,这种方法在使用c++时不能很好地工作。
在这个项目中,我最初使用的是我的python方法,即只编写代码,而不绘制端到端解决方案。最后,我坐下来,想出了一个解决这个问题的总体架构。
下面列出了在实现决策树分类器中开发的关键对象。它们包括一个Node类和一个Tree类,以及它们相关的属性和方法,并且大部分可以在编写任何代码之前定义:
Node
- Node constructor
- Node destuctor
- Attributes
- children nodes
- data
- best split feature chosen
- best split category chosen
- Methods
- giniImpurity() - metric for scoring quality of split
- bestSplit() - best split feature and category
Tree
- Tree constructor
- Tree destructor
- Attributes
- root node of tree
- Methods
- traverse() - traverse nodes of tree
- fit() - fit tree to dataset
- predict() - make predictions classes with unseen data
- CSVReader() - read a csv
决策树项目的核心文件(不包括测试文件)如下所示,以供参考。
.
├── CMakeLists.txt
├── CSVReader.cpp
├── CSVReader.hpp
├── DecisionTree.cpp
├── DecisionTree.hpp
├── Main.cpp
├── Node.cpp
├── Node.hpp
└── README.md
一旦该体系结构就位,解决方案自然就会遵循。对类及其成员函数(类和函数参数以及返回的对象)的接口进行前瞻性设计也可以使事情变得更加容易。
从长远来看,编写测试将为您节省时间
由于c++缺乏安全性,所以测试代码的每个部分是否都成功地完成了预期的功能是至关重要的。用于c++的谷歌Test测试框架很适合这个项目,它使用CMake构建。
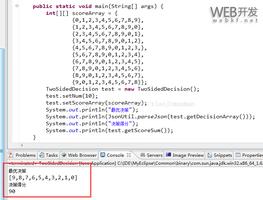
以可测试的方式编写代码可以更容易地识别和隔离bug。方法是为实现的类编写静态定义的成员函数。静态定义的成员函数可以在没有父类实例化的情况下独立执行。这使得为完成决策树业务逻辑的一个方面的每一个功能编写特定的、独立的测试用例成为可能。
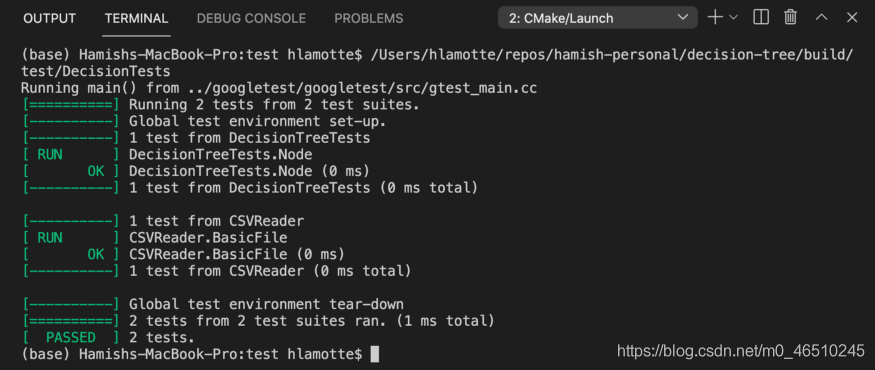
上面显示了在终端中通过测试的谷歌Test的输出。
语言的在线社区非常有价值
Python开发人员有一个开发人员社区,使用像Stack Overflow和博客这样的工具为集体知识做出贡献。此资源是Python数据科学的命脉。c++没有等价的社区。在谷歌上搜索开发c++代码时遇到的许多问题和错误消息,往往会得到没有帮助的结果。一种语言的社区价值很大。
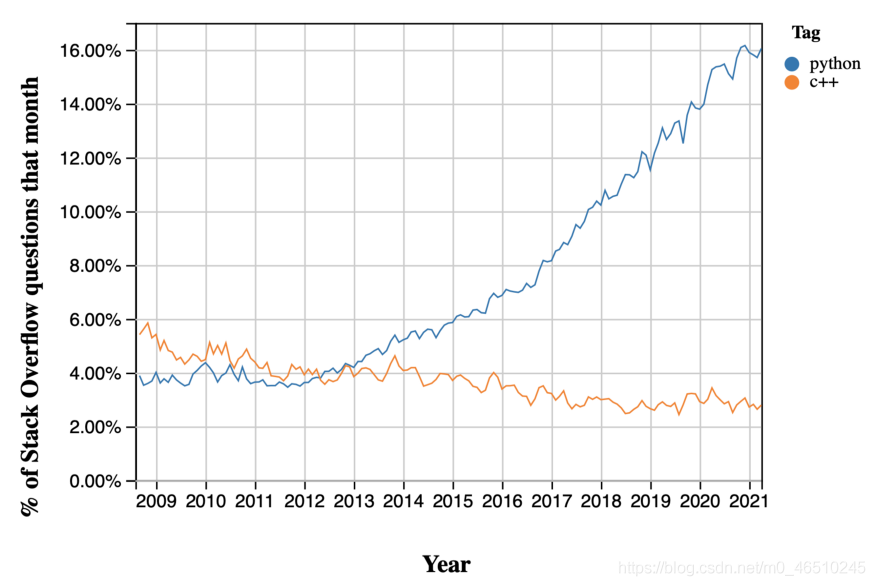
从上面我们可以看到,现在每个月被回答的与Python相关的问题比c++多4倍。在这里查看这些统计数据的当前状态。
可移植性是一个重要的考虑因素
在Python中,你可以确信任何安装了Python解释器的系统都能够执行你的Python程序。而在c++中,你就没有这种特权了。由于c++是一种编译语言,在运行程序之前必须先编译程序,而且必须针对要运行程序的宿主的体系结构来编译它。
当尝试使用Github Actions远程测试代码时,这成为一个重要的问题。由于主机是不同的操作系统和架构,因此需要在虚拟机上测试代码之前编译代码。这是部署代码时需要管理的额外开销。
总结
学习像c++这样的低级语言可以让你接触到许多快速程序所需的核心概念,如内存管理、数据结构和编译语言。它让人们意识到Python中预先实现的数据结构,比如Pandas DataFrames,将拥有处理内存管理的系统,这些系统必须做出一系列假设,因此有局限性。
在实践中,不太可能有很多数据科学家会使用c++来解决实验性的数据科学问题,但是Python不再是最好的工具,例如编写快速的数据解析器或实现昂贵的算法。即使在这种情况下,我也将探索现代低级语言,如Go-lang和Rust,而不是c++。c++的语法让人感觉很冗长,而且它缺乏许多可以从这些现代语言中获得的安全特性。
您可以在这里从头看到c++决策树分类器的完整源代码。您还可以在这里找到一个示例jupiter notebook,它直接从Python调用已实现的决策树分类器,并在Titanic数据集上训练决策树。https://github.com/hlamotte/decision-tree
到此这篇关于教你用c++从头开始实现决策树的文章就介绍到这了,更多相关c++实现决策树内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
以上是 教你用c++从头开始实现决策树 的全部内容, 来源链接: utcz.com/p/246170.html