Solr 的高亮详解(Highlighting)
一、简介
Highlighting(高亮)是 solr 的另一个核心功能,即在查询返回的结果中高亮显示命中的查询关键字。solr 高亮能够帮助用户快速地从查询结果集中扫 描出哪些结果值得进一步的查阅浏览,或者决定是否应该单击进入下一页,甚至在发现匹配不到期望的结果信息时重新发起另一个查询请求。
高亮效果的展现形式取决于你,可以加粗、改变字体颜色、更换其他字体等。
高亮摘要并不是索引文档中的description描述域,他只是根据用户输入的搜索关键字以及描述域在查询时动态计算出来的一段文本摘要,正是因为高亮摘 要是动态计算的,所以他并不是一开始就存在的,而且他对于每个索引文档来说也不是固定不变的,会跟随用户输入的搜索关键字的不同发生动态变化。
大部分的搜索应用程序中,由于显示屏幕空间有限,你不可能完全显示某一条结果。当然如果你的索引文档都是很短的文档,完全显示自然没有太大的问 题。但是大多情况下,你只能显示每个索引文档的一小部分。那这就会有个问题了,你会选择索引文档中的哪部分内容用于显示呢?理论上来讲,你期望 显示每个索引文档的一小片短,而该一小片段是基于与用户查询的相关度来动态生成与用户给定查询匹配度最高的最佳片段。而该片段也被称为 “高亮摘要”,将动态生成最佳的摘要返回给用户也是 solr 中的 Highlighting(高亮)提供的核心功能。
二、solr 高亮的工作原理
在 solr 中使用高亮不需要做太多预先的配置工作,他是开箱即用的。高亮是solr中的一个核心功能,通常也是大部分搜索程序中的一个重要功能。
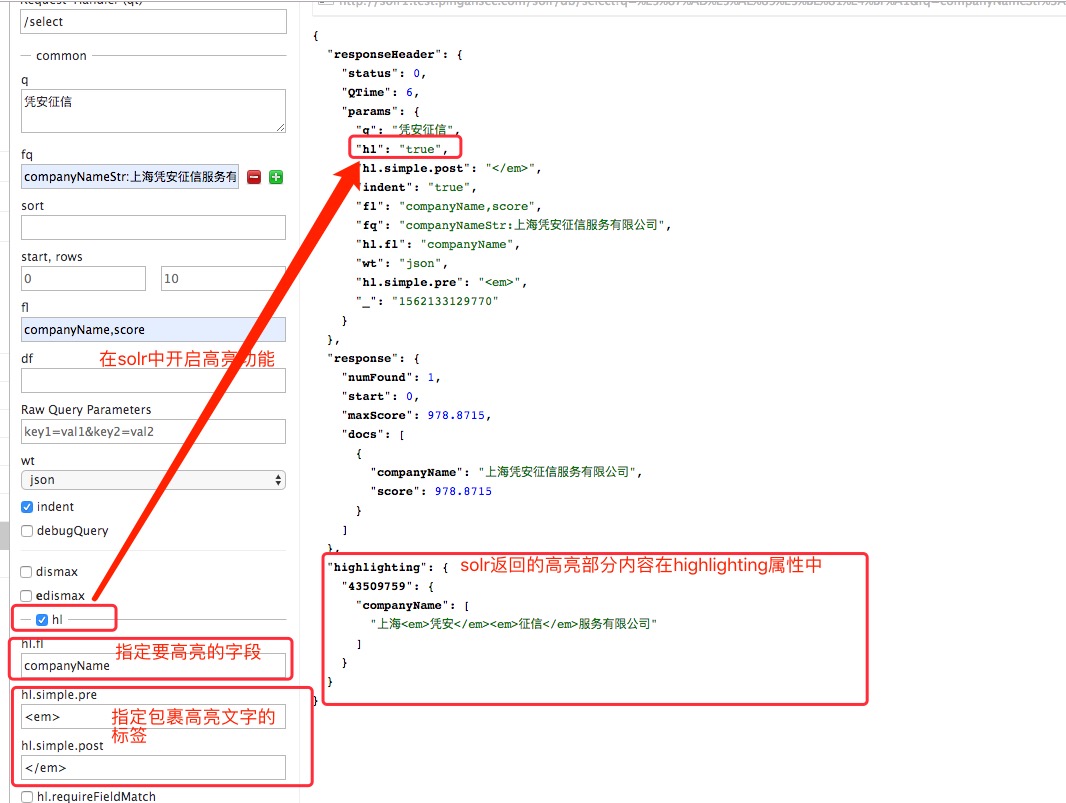
在solr中开启高亮功能,你只需要添加一个hl=true参数即可。同solr中的其他搜索组建类似,solr中的高亮器也支持一些可选的请求参数,用于 调整高亮器的行为。
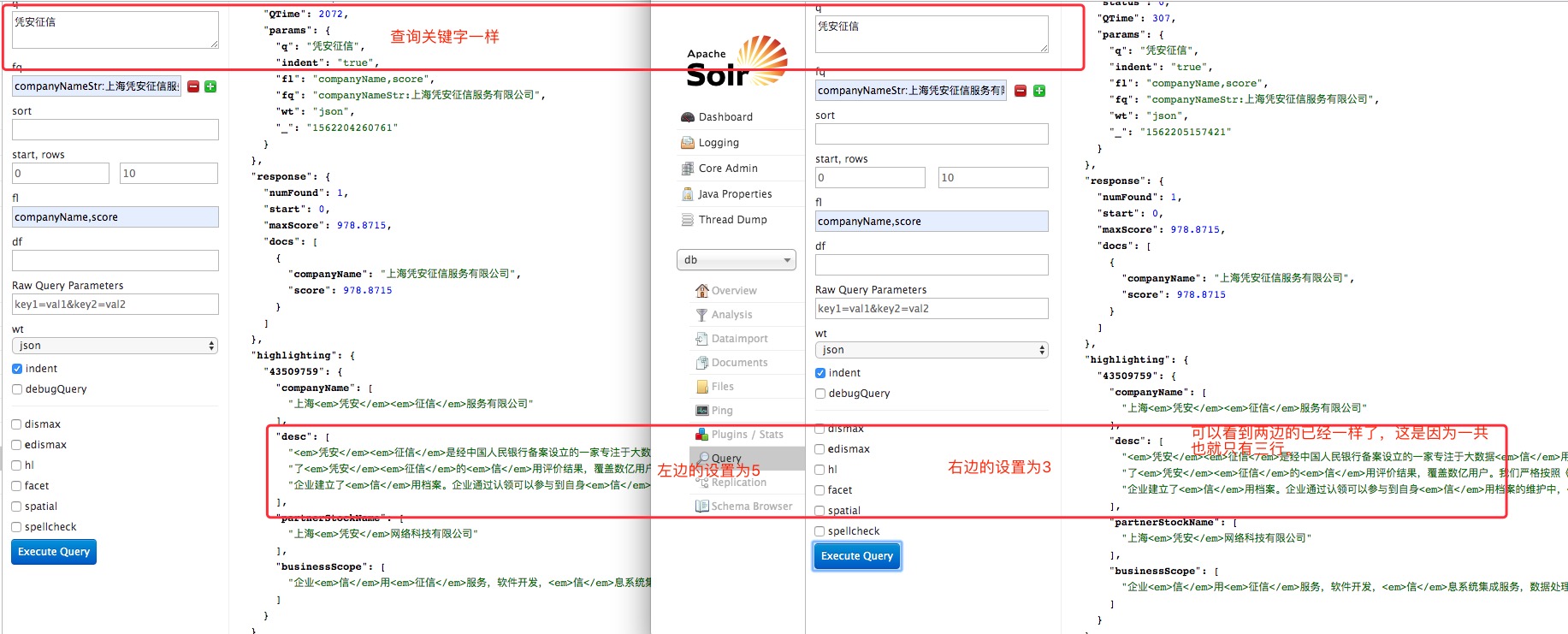
大部分情况下,每个结果对应一个高亮片段,对于用户来说通过高亮片段的个数来判断索引文档是否值得浏览可能还不够。我们可以添加一个 hl.snippets参数,让搜索结果中的每个索引文档都返回多个高亮片段。默认最多返回一个高亮片段。
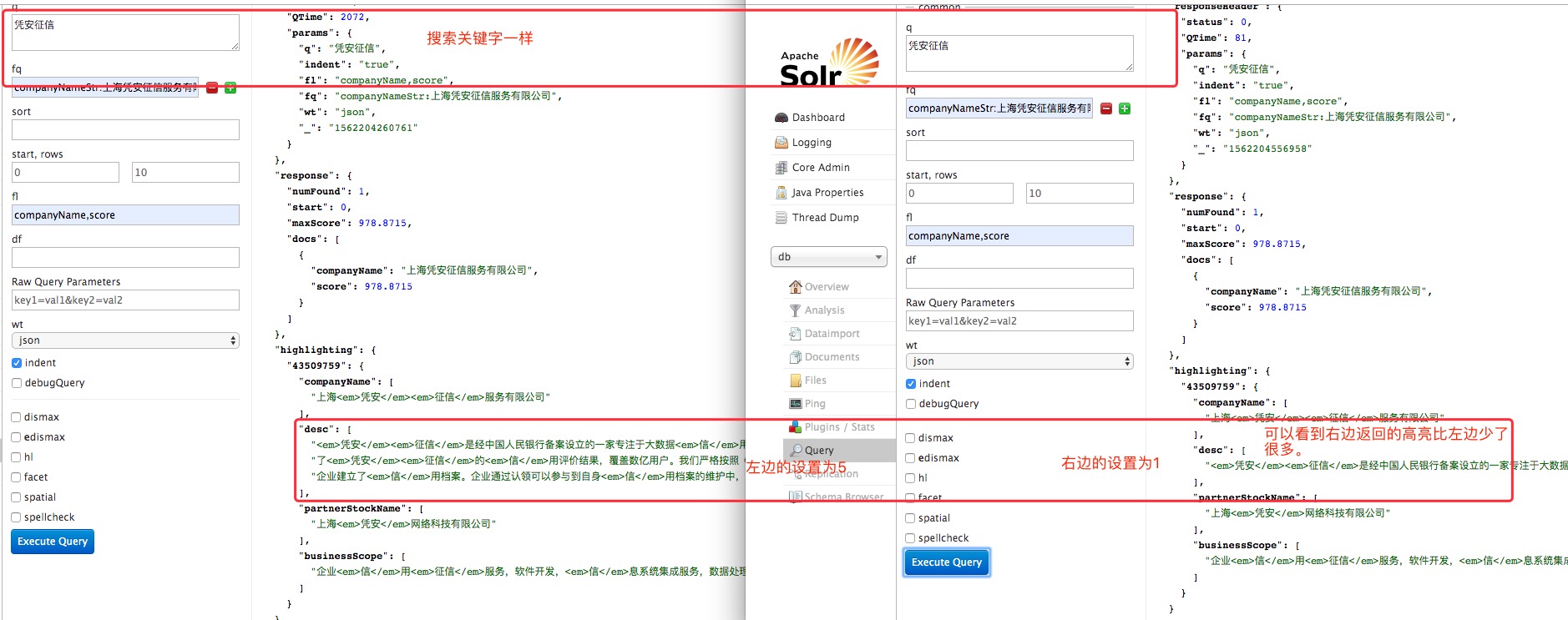
但是将hl.snippet设置为2并不能保证每个索引文档最终一定会生成2个高亮片段。hl.snippet参数只是限制每个索引文档最终返回的高亮片段最多有几个,但此参数还受其他参数的影响,所以此参数并不是强制要求的。 hl.snippet=1的示例:
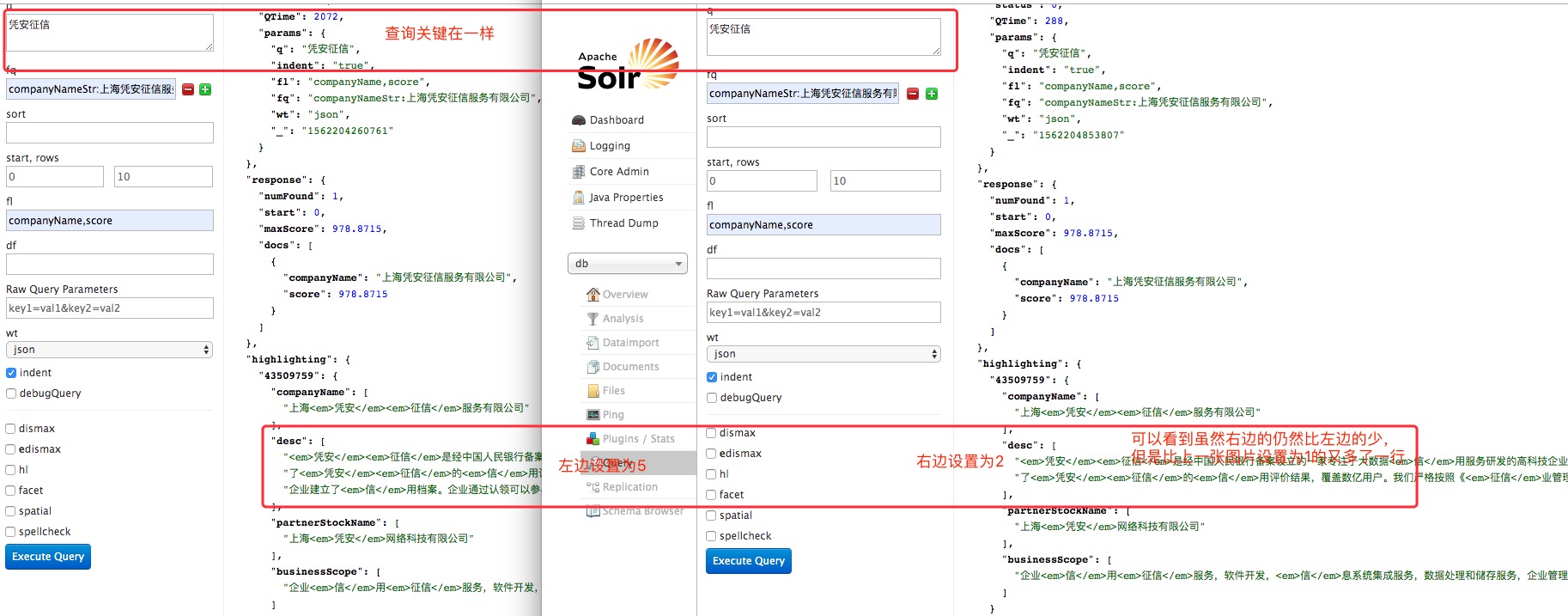
hl.snippet=2 的示例:
hl.snippet=3 的示例:
如果你想要在多个域上执行高亮,那么你可以通过指定hl.fl参数来实现,假如你的索引文档中有title和body这两个域,那么这时你可以指定 hl.fl=title,body。
以上配置如下:
<str name="hl">true</str><str name="hl.snippets">5</str>
<str name="hl.fl">
companyName legalPerson partnerStockName employeeName trademark companyAddress businessScope
</str>
在solr高亮器执行高亮之前,它需要首先访问域的原始文本即域值,要想访问域的原始文本,那么该域必须stored=true。获取到高亮域的域值后,高亮器需要根据域类型中配置的索引时使用的分词器对域值进行分词。高亮器为什么要对其分词呢?主要是出于两方面原因考虑。首先高亮片段中的trem需要与用户输入的搜索关键字进行比较,分词后才能与用户输入的关键字相匹配。第二点,当用户输入查询关键字中包含的trem与高亮域分词后得到的trem相匹配了,要想实现高亮,那么对于solr中的FastVectorHighlighter高亮器需要知道这些trem在域的域值原始文本中的起始位置,这样才能够在他们两头添加高亮标签。
示例:
Highlighter包括了三个主要部分:段划分器(Fragmenter)、 计分器 ( Scorer )和格式器(Formatter)
三、Fragmenter(片段划分器)
Fragmenter会根据高亮域的原始文本与用户输入关键字生成Fragment(片段),然后交由Scorer(计分器)对每个Fragment(片段)进行相关性打分。最后评分前N个Fragment会被构造成Snippet,这里的N由参数hl.snippets决定。在solr中生成Fragment有两种方式,使用GapFragmenter和RegexFragmenter。默认是使用GapFragmenter。
GapFragmenter是基于一个目标长度来生成Fragmenter,默认fragment的长度是100,但是他可以通过hl.fragsize参数进行修改。但是hl.fragsize参数并不表示Fragment的固定长度。
GapFragmenter之所以叫做GapFragmenter,是因为它在为多值域创建Fragment时能够避免生成的Fragment跨越了很大一个位置间隙,而多值域的两个值之间的间隙可以通过positionIncrementGap属性来控制,你可以在schema.xml中定义field时为其添加positionIncrementGap属性。
<fieldType name="text_mmseg4j_maxword" class="solr.TextField" autoGeneratePhraseQueries="false" positionIncrementGap="100"> <analyzer type="index">
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" dicPath="dic"/>
</analyzer>
<analyzer type="query">
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="custom-max-word" dicPath="dic"/>
</analyzer>
</fieldType>
同时solr还支持RegexFragmenter实现,它使用正则表达式的方式来生成Fragment。比如你可以使用正则表达式[-\w,/\n\”‘]{20,200}来匹配Fragment。由于RegexFragmenter并不是默认实现,所以如果你想要默认使用RegexFragmenter,那么需要你在solrconfig.xml中提前配置RegexFragmenter,当然你也可以在查询的时候再临时指定这些高亮参数。
<highlighting> <!-- Configure the standard fragmenter -->
<!-- This could most likely be commented out in the "default" case -->
<fragmenter name="gap" class="org.apache.solr.highlight.GapFragmenter" default="true">
<lst name="defaults">
<int name="hl.fragsize">100</int>
</lst>
</fragmenter>
<!-- A regular-expression-based fragmenter (f.i., for sentence extraction) -->
<fragmenter name="regex" class="org.apache.solr.highlight.RegexFragmenter">
<lst name="defaults">
<!-- slightly smaller fragsizes work better because of slop -->
<int name="hl.fragsize">70</int>
<!-- allow 50% slop on fragment sizes -->
<float name="hl.regex.slop">0.5</float>
<!-- a basic sentence pattern -->
<str name="hl.regex.pattern">[-\w ,/\n\"']{20,200}</str>
</lst>
</fragmenter>
<!-- Configure the standard formatter -->
<formatter name="html" class="org.apache.solr.highlight.HtmlFormatter" default="true">
<lst name="defaults">
<str name="hl.simple.pre"><![CDATA[<em>]]></str>
<str name="hl.simple.post"><![CDATA[</em>]]></str>
</lst>
</formatter>
</highlighting>
四、Scorer(计分器)
Scorer用于对Fragmenter生成的每个Fragment进行相关性评分,默认Scorer的实现是QueryScorer。它会统计每个Fragment中出现用户输入的查询关键字的次数,出现次数越频繁说明相关性越高,那么Fragment的得分就越高,自然就优先返回。
高亮器PostingHighlighter中使用的是另一种Scorer,它采用的是一种更高级的打分算法来实现对每个Fragment的相关性打分,具体稍后再做讲解。
五、Encoder & Formatter(格式器)
hl.formatter参数用来指定采用什么formatter来指定对高亮的Term进行格式化,默认实现的是hl.formatter=simple,这种方式对于使用HTML标签来包裹高亮的Term比较合适,设置两头的包裹HTML标签,你可以使用hl.simple.pre和hl.simple.post这两个参数,比如你想要使用css没话高亮Term,那么你再查询参数请求中如下所示添加2个请求参数: hl.simple.pre=&hl.simple.post= 这样高亮Term就被格式化成Term,之后就可以在你的css样式文件中任意定义foo类样式。
Encoder组建负责在每个Fragment传递给Formatter组建之前对特殊字符进行编码,当你想要生成HTML标签格式的高亮Fragment时,HTML Encoder会转义HTML字符实体,比如双引号(“)会转义成"。
六、Facet & Highlighting
七、高亮多值域
solr 同时支持对多值域进行高亮,下面的示例演示如何对多值域进行高亮
http://localhost:8080/solr/ufo/select?q=fire cluster clouds thunder&df=nearby_objects_en&wt=json&hl=true&hl.snippets=2上面的示例与对单值域进行高亮没什么区别,因为尽管我们在多值域的值的时候,多个值是分开多次add的,比如像下面这样
doc.addField("nearby_objects_en","arc of red fire");doc.addField("nearby_objects_en","cluster of dark clouds");
doc.addField("nearby_objects_en","thunder and lighting");
然而多个值之间是存在间隙的,即positionIncrementGap的属性值,但positionIncrementGap默认值是0,也就是实际存储的时候你可以认为他们是紧挨在一起的,比如我们的示例中,你可以认为索引文档是存在”clouds thunder“这个Trem的,所以当你查询fire cluster clouds thunder时,包含这四个Term的高亮结果都返回了。但是默认情况下,solr只会返回包含搜索关键字的高亮结果,不包含的不返回。如果你希望返回的高亮结果直接就是该多值域的每个值,只是命中了搜索关键字的会进行高亮,没有命中的就直接显示原始值域,那么,此时你需要添加一个hl.preserveMulti参数,并将其设置为true,此参数默认值为false,它表示在高亮结果中保留多值域的每个值,直接在原始值域的基础上进行高亮,这样便于用户确认是多值域中的哪几个值被高亮了。
http://localhost:8080/solr/ufo/select?q=fire cluster clouds thunder&df=nearby_objects_en&wt=json&hl=true&hl.snippets=10$hl.preserveMulti=true八、高亮参数
| 参数名称 | 描述 | 默认值 |
|---|---|---|
| hl | 表示是否为你的查询开启高亮功能 | false |
| hl.snippets | 为每个域生成高亮片段的最大个数 | 1 |
| hl.fl | 为哪些域生成高亮片段,多个域名称之间采用逗号分隔 | 如果未设置会以df参数为准 |
| hl.fragmenter | 指定使用什么Fragmenter组件来生成Fragment,Fragmenter组件需要在solrconfig.xml中注册 | gap |
| hl.fragsize | 设置每个fragment的目标长度,并不是一个严格的字符最大限制 | 100 |
| hl.q | 用于高亮的查询,你可以添加与q参数的主查询不同的额外的Term | 没有默认值 |
| hl.alternateField | 当没有生成任何高亮片段时,指定一个存储域(即stored=true的域)用于显示 | 没有默认值 |
| hl.formatter | 指定使用哪种Formatter组件,Formatter组件需要在solrconfig.xml中注册 | simple |
| hl.simple.pre | 为每个高亮Trem的开头添加的高亮标签,一般是HTML中的标签 | \ |
| hl.simple.post | 为每个高亮Trem的末尾添加的高亮标签,一般是HTML中的标签,与hl.simple.pre搭配使用 | \</em> |
| hl.requireFieldMatch | 当对多个域进行高亮,如果此参数设置为true,则表示查询结果不为空才会执行高亮,如果此参数设置为false,则表示它可能匹配某个域,但是却对另一个域进行高亮。如果hl.fl使用了通配符,那就表示自动设置此参数为true,如果你查询的是所有域,那么还是将此参数设置为false吧,这样便于你清楚到底是哪些域匹配了搜索关键字。 | false |
| hl.maxAnalyzedChars | 当Formatter对一个大文本域进行分词时需要设置最大支持对多长的字符进行分词处理。如果不想做任何限制,那么请设为-1 | 51200 |
| hl.usePhraseHighlighlingter | 如果设置为true,则表示高亮器只对匹配的短语进行高亮,匹配的单个Term不进行高亮,且solr会使用Lucene中的SpanScorer去对Phrase打分 | false |
| hl.mergeContiguous | 若此参数设置为true,那么solr会将临近的Formatt合并为一个Formatt | false(为了向后兼容) |
| hl.highlightMultiTerm | 若此参数设置为true,即表示启用高亮器对range/wildcard/fuzzy/prefix这些查询的支持 | false |
| hl.preserveMulti | 多值域高亮使用。若此参数设置为true,则表示对多值域的每个值执行高亮处理,不管该值是否与搜索关键字匹配。并且返回的高亮结果会保留多值域的原始值域的添加顺序 | false |
| hl.maxMultiValuedToExamine | 限制最多对多少个多值域的域值进行检查 | Integer.MAX_VALUE |
| hl.maxMultiValuedToMatch | 限制最后有多少个多值域的域值匹配,当hl.maxMultiValuedToExamine参数也设置了那么哪个参数先达到限制就先终止 | Integer.MAX_VALUE |
| hl.maxAlternateFieldLength | 设置hl.alternateField参数指定的域的字符最大长度,设置为小于等于0的数值表示不做限制 | 无限制 |
| hl.highlightAlternate | 如果此参数设置为true,且设置了hl.alternateField,solr会显示整个alternate field并显示高亮,如果hl.maxAlternateFieldLength=N参数设置了,那么solr会返回最多N个字符作为高亮摘要。如果此参数设置为false,或者hl.alternateField参数指定的可选域没有匹配搜索关键字,那么会直接显示可选域的域值文本但不包含高亮片段 | true |
| hl.tag.pre/hl.tag.post | 与hl.simple.pre、hl.simple.post参数类似,用于PostingsHighlighter高亮组建 | \ |
| hl.phraseLimit | 用于提升FastVcctorHighlighter高亮器的执行性能,表示最多对多少短语进行匹配 | Integer.MAX_VALUE |
| hl.fragListBuilder | 用于指定什么类型SolrFragListBuilder。其他可选值有single、simple,single他会将整个值域当作一个高亮片段 | weighted |
| hl.fragmentsBuilder | fragments builder主要负责格式化Fragmenter,它默认\装饰高亮Trem,用于指定什么类型SolrFragmentsBuilder。SolrFragmentsBuilder配置示例请接着往下看 | default |
| hl.regex.slop | 表示hl.gragsize会发生变化以适应正则表达式的因子,默认是0.6,意思是如果hl.gragsize=100那么gragsize的大小会从40~160。当你使用RegexFragmenter时,此参数会有用 | 0.6 |
| hl.regex.pattern | 当你使用RegexFragmenter时需要用的正则表达式,根据指定的正则表达式来匹配 | 无默认值 |
| hl.regex.maxAnalyzedChars | 当你使用RegexFragmenter时需要用到此参数,用于限制RegexFragmenter只处理限定字符长度范围内的域值进行处理 | 10000 |
| hl.boundaryScanner | 用于匹配如何确定Fragment的边界,默认是以字符级别来划分边界,可选值有breakIterator、simple。SimpleBoundaryScanner会根据hl.fragsize参数决定的关键字的起始偏移量和结束偏移量,重新计算摘要的起始偏移量。关于如何在solrconfig.xml中配置boundaryScanner请继续往下看 | simple |
| hl.bs.maxScan | 用于指定SimpleBoundaryScanner边界扫描器扫描字符的长度 | 10 |
| hl.bs.chars | 用于指定能够确定Fragment边界的字符 | .,!\t\n以及空格 |
| hl.bs.type | 决定BreakIterator怎么划分界定符,可选值有:CHARACTER、WORD、SENTENCE、LINE、WHOLE。SENTENCE是按照句子来划分 | WORD |
| hl.bs.language | 当你使用BreakIteratorBoundaryScanner时会需要此参数,用于指定Local使用什么本地语言 | 空字符串 |
| hl.bs.country | 当你使用BreakIteratorBoundaryScanner时会需要此参数,用于为Local类指定国家信息 | 空字符串 |
上面表格中的参数你都可以单独每个域进行设置,举个例子,假如你有title和body这两个域,title通常是一些比较短的域,所以一般一个高亮片段就都了,但是你可能希望为body域生成3个高亮片段,那么你可以这样处理:
f.body.hl.snippets=3九、FastVectorHighlighter
使用默认的高亮器最大的问题就是对于大文本域执行高亮查询会非常慢。导致查询速度慢的主要原因就是他需要在查询时对域值文本进行重新分词。为解决这个问题,sole提供了FastVectorHighlighter快速高亮器,它的执行速度比默认高亮器要快,因为它跳过了在生成Fragment阶段需要重新分词的步骤。
注意:默认高亮器性能问题并不是很突出,在我们的UFO示例中甚至很难重现这种问题,默认高亮器通常运行速度很快,甚至当你将每页返回的索引文档大小设置为50,性能问题依然不是很突出。但是如果你每页返回的索引文档成千上万了,又或者同时需要对多个域进行高亮,那么此默认高亮器的性能就显现出来了,变得越来越慢,尽管当默认高亮器运行速度很慢时我们可以使用FastVectorHighlighter高亮器来救急,但是并不意味着默认高亮器就100%不适合于你的应用,也并不意味着FastVectorHighlighter高亮器在任何时候都比默认高亮器优秀。
FastVectorHighlighter高亮器在高亮时需要访问每个Trem的位置信息以及偏移量信息,所以它依赖于你在索引创建时就提前计算好并存储到索引结构中。因此用FastVectorHighlighter高亮器时,任何高亮的域都必须在索引创建时启用termVectors、termPositions、termOffsets。在我们的示例中,如果我们想要为sighting_en域启用FastVectorHighlighter高亮器,那么需要如下进行定义:
<field name="sighting_en" type="text_en" indexed="true" stored="true" termVectors="true" termPositions="true" termOffsets="true">这看起来似乎很简单,但是修改完域的定义之后,别忘了,你需要对所有索引文档重新建立索引,这样才能使你的设置生效。但是带来更大的问题是这些属性会使你的索引体积变得臃肿,对于UFO示例来说,开启了3个属性重建索引之后,索引体积由原来的69MB增加到109MB,这种索引体积的增长对于小数据集来说可能微不足道,但是对于大规模的索引文档来说,那简直就是灾难。存储vectors、positions、offsets这些信息同时还会稍微减缓你索引创建的速度,在高吞吐环境下要求能够近实时搜索时这可能会是一个问题。
要想使用FastVectorHighlighter高亮器,你需要首先在schema.xml中修改域的定义启用那3个属性,然后重新启动Solr Server服务,紧接着你需要对所有索引文档重新创建索引。想要激活FastVectorHighlighter高亮器,你需要传递hl.useFastVectorHighlighter参数并将其设为true,使用示例如下
http://localhost:8080/solr/ufo/select?q="blue fireball"&df=sighting_en&wt=json&hl=true&hl.snippets=10&hl.useFastVectorHighlighter=true在上面的查询示例中,我们的高亮返回结果会将整个查询短语进行高亮,而不仅仅是对单个高亮Term进行高亮,这也是FastVectorHighlighter高亮器与默认高亮器相比,他的另一个优势。
十、PostingsHighlighter
Solr中还提供一种新的高亮器:PostingsHighlighter,他的执行速度比FastVectorHighlighter还快。PostingsHighlighter需要在倒排索引表中存储Term的偏移量,与FastVectorHighlighter相比,FastVectorHighlighter需要在索引中创建一个独立的数据结构用于检索Term的位置信息和偏移量。回顾下Lucene的倒排索引表,我们知道在Lucene的倒排索引表中的倒排索引信息是存储在posting list中的,其中包含term、term出现的document列表、termfrequency。如果想要使用PostingsHighlighter你还需要在创建索引是在倒排索引表的posting list中再额外存储Trem的位置信息和偏移量信息,在Solr中,你需要做的就是必须在schema.xml中为高亮域添加storeOffsetsWithPositions属性,并将其设置为true,配置示例如下所示
<field name="sighting_en" type="text_en" indexed="true" stored="true" storeOffsetsWithPositions="true">同理,当你修改schema.xml中域的定义信息,那么需要重新建立你的索引,然后重启你的Solr Server服务或者重新加载Core。启用storeOffsetsWithPositions之后索引体积只是从69MB增大到85MB,相比FastVectorHighlighter而言,索引体积增长的不是那么迅猛了,这对于大规模的索引文档来说具有重大意义。
要想使用 PostingsHighlighter 高亮组件,还需要在 solrconfig.xml 中显式的注册它。
由于PostingsHighlighter高亮器在Solr5.3.1版本中还只是实验性功能,并没有提供类似FastVectorHighlighter高亮器的请求参数hl。useFastVectorHighlighter。具体Solr支持哪些高亮请求参数,请查阅org.apache.solr.common.params.HighlightParams类,因为每个版本经过迭代后支持的功能特性会有所不同。
PostingsHighlighter高亮器与其他高亮器不同的是,多个高亮片段是采用“…”省略号的形式拼接在一起形成一个高亮片段返回,你可以通过hl.tag.ellipsis参数来修改默认的拼接符。
除了高亮执行的速度快以及索引创建开销减少之外,PostingsHighlighter 高亮器还使用了以各种更高级的相似度计算,被称作 BM25,用于对Fragment进行相关性打分,默认的 Scorer 打分器是统计查询Term在每个Fragment中出现的频率,而BM25是一种先进的 tf-idf 打分函数,用于计算索引文档或Fragment与Query之间的相似性。BM25Scorer默认会提高包含在搜素中出现不那么频繁的Trem的Fragment的权重。
PostingsHighlighter 高亮器的主要缺点就是他需要Trem精确的位置偏移量信息,这些信息需要在索引创建时提前设置。因此在使用 PostingsHighlighter 高亮器之前,你需要对高亮域所应用的域类型配置的分词器进行测试,确保分词器正确处理了每个Token的位置偏移量信息,即 token 的 start、end、position 数据。
以上是 Solr 的高亮详解(Highlighting) 的全部内容, 来源链接: utcz.com/p/233763.html