solr 的 edismax 详解
一、简介
对于 solr 的 edismax 影响打分的策略一直都很模糊,因此也给工作带来了极大的不便。苦于国内相关 solr 介绍的博客等极少,且大都介绍的不是很深入,更没有详细的示例,因此买了两本书自己慢慢吭。现将自己的一些总结(心得)记录在此,以便自己以后翻阅,同时也可给有需要的开发人员参考,算是抛砖引玉吧。
二、先前准备 phraseQuery(短语查询)
查询关键字q的介绍相信大部分都知道,这里大致介绍一下,q的查询常见的分为boolQuery和phraseQuery。
对于boolQuery查询我们很常见,就是将多个搜索的关键字用布尔连接符(AND OR)连接作为查询条件
那么,什么叫做 phraseQuery(短词)查询呢?
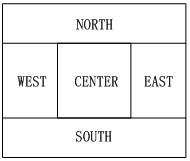
其实这个名称很早之前就已经听过,但是一直也没有弄明白到底是什么意思。于是到百度上查询solr短词也是没有很好的答案,最后参考的是 elasticsearch 的短语查询才了解相关含义。这里就先介绍 phraseQuery 与普通的 boolQuery 查询不同之处,详细的会在下文举出示例。 在solr中被双引号包裹的关键字会被认为是 phraseQuery(短语查询)。
先看一个示例:
上面只是了解了 phraseQuery 的查询语法(什么样的查询才会被解析为 phraseQuery),但是 phraseQuery 有什么作用?
普通的boolQuery找出一个文档中的独立单词是没有问题的,但有时候想要精确匹配一系列单词或者短语 。比如,我们想执行这样一个查询,仅匹配同时包含 “上海” 和 “凭安” ,并且 二者以短语 “上海凭安” 的形式紧挨着的公司记录。 如果你使用短语匹配的话查询关键字如果为”凭安上海”是匹配不到记录的。
当一个字符串被分词后,这个分析器不但会 返回一个词项列表,而且还会返回各词项在原始字符串中的 位置 或者顺序关系
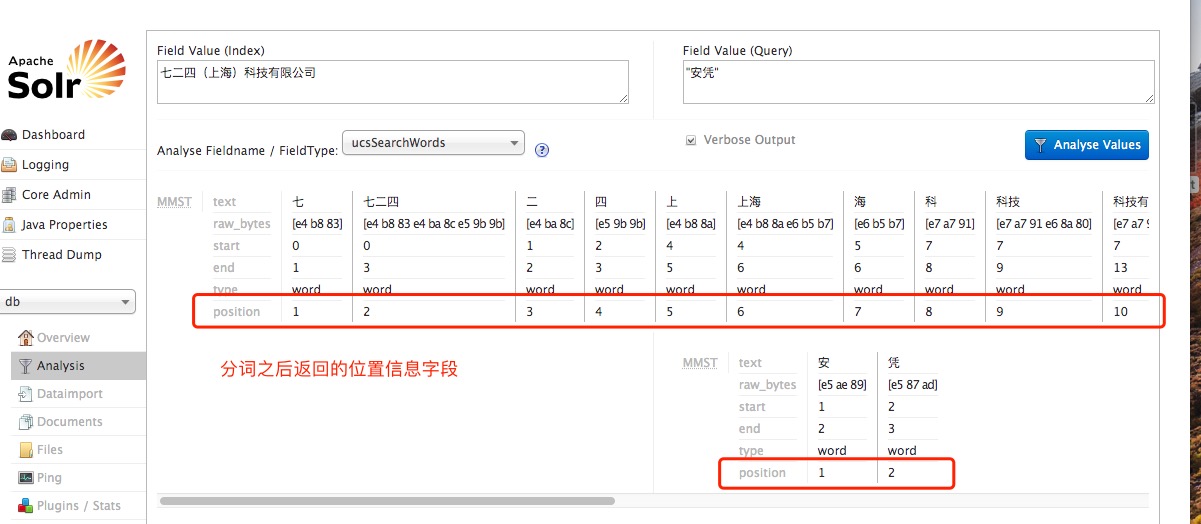
位置信息可以被存储在倒排索引中,因此 phraseQuery 查询这类对词语位置敏感的查询, 就可以利用位置信息去匹配包含所有查询词项,且各词项顺序也与我们搜索指定一致的文档,中间不夹杂其他词项。
phraseQuery(短语查询)其实更注重的是“位置”。
一个被认定为和短语 quick brown fox 匹配的文档,必须满足以下这些要求:
quick 、 brown 和 fox 需要全部出现在域中。 brown 的位置应该比 quick 的位置大 1 。 fox 的位置应该比 quick 的位置大 2 。
短语的搜索示例如下:
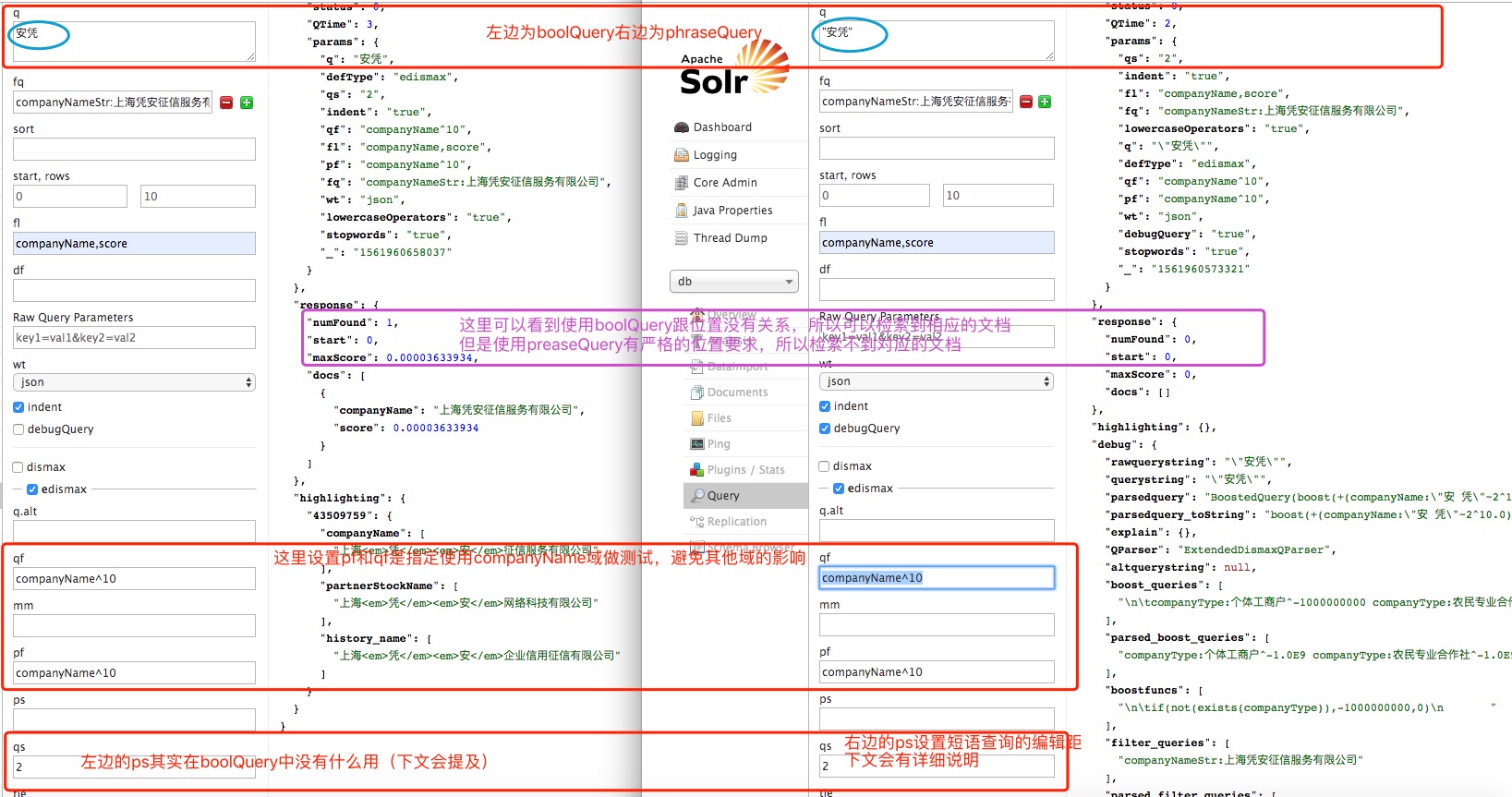
三、edismax各选项详细介绍
来咯来咯他们真的来咯……^-^
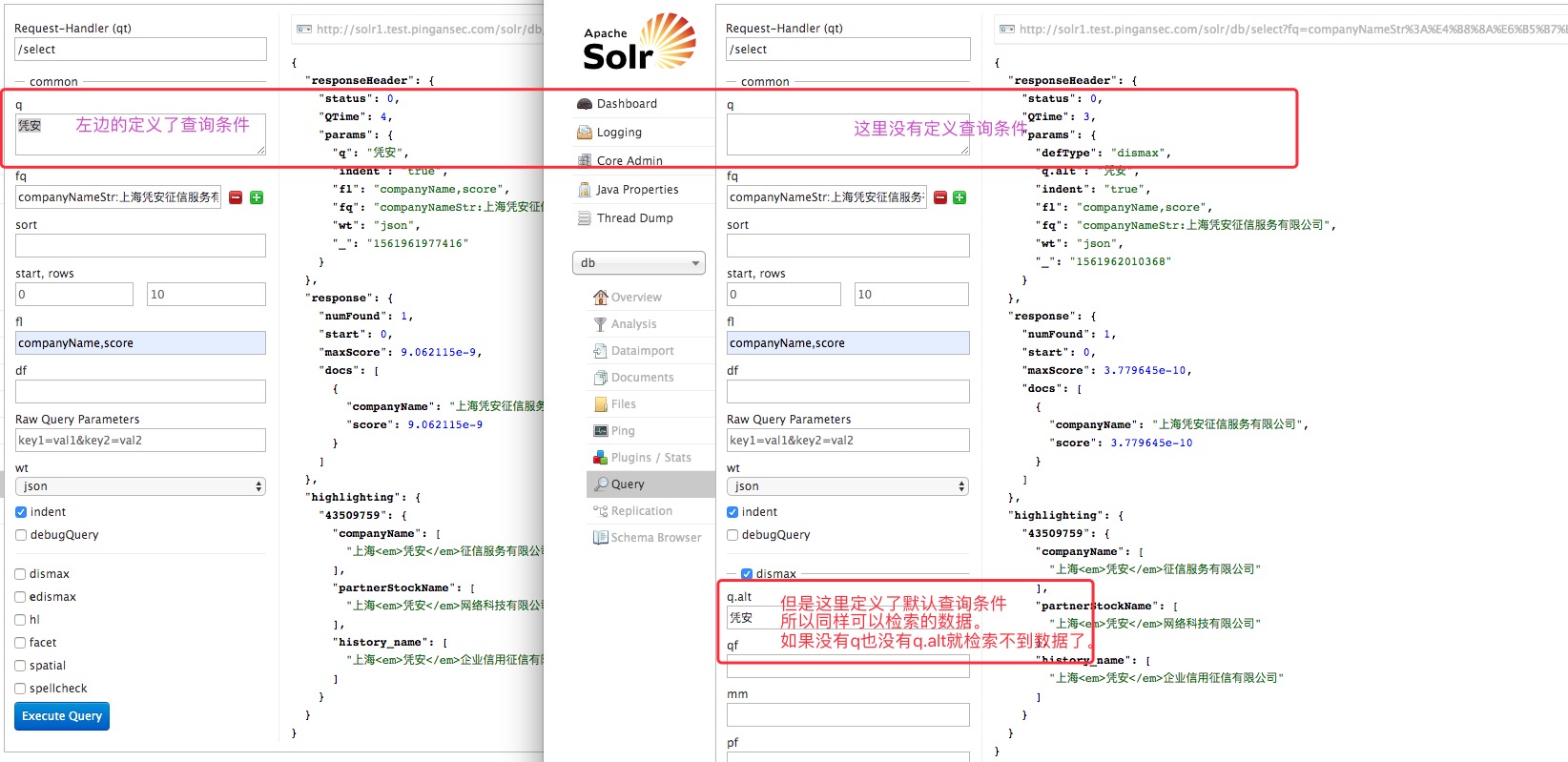
1、q.alt
定义q参数为空时候的输入字符串,也就是说当q查询的字符串不存在时会使用该参数定义的值去查询。
2、qf
query field。q中的词项要在哪些字段上执行查询。可以设置多列以及每一列的权重(查询重要性)。 如果没有设置,那么将会使用df默认字段(一般在配置文件中配置好)。

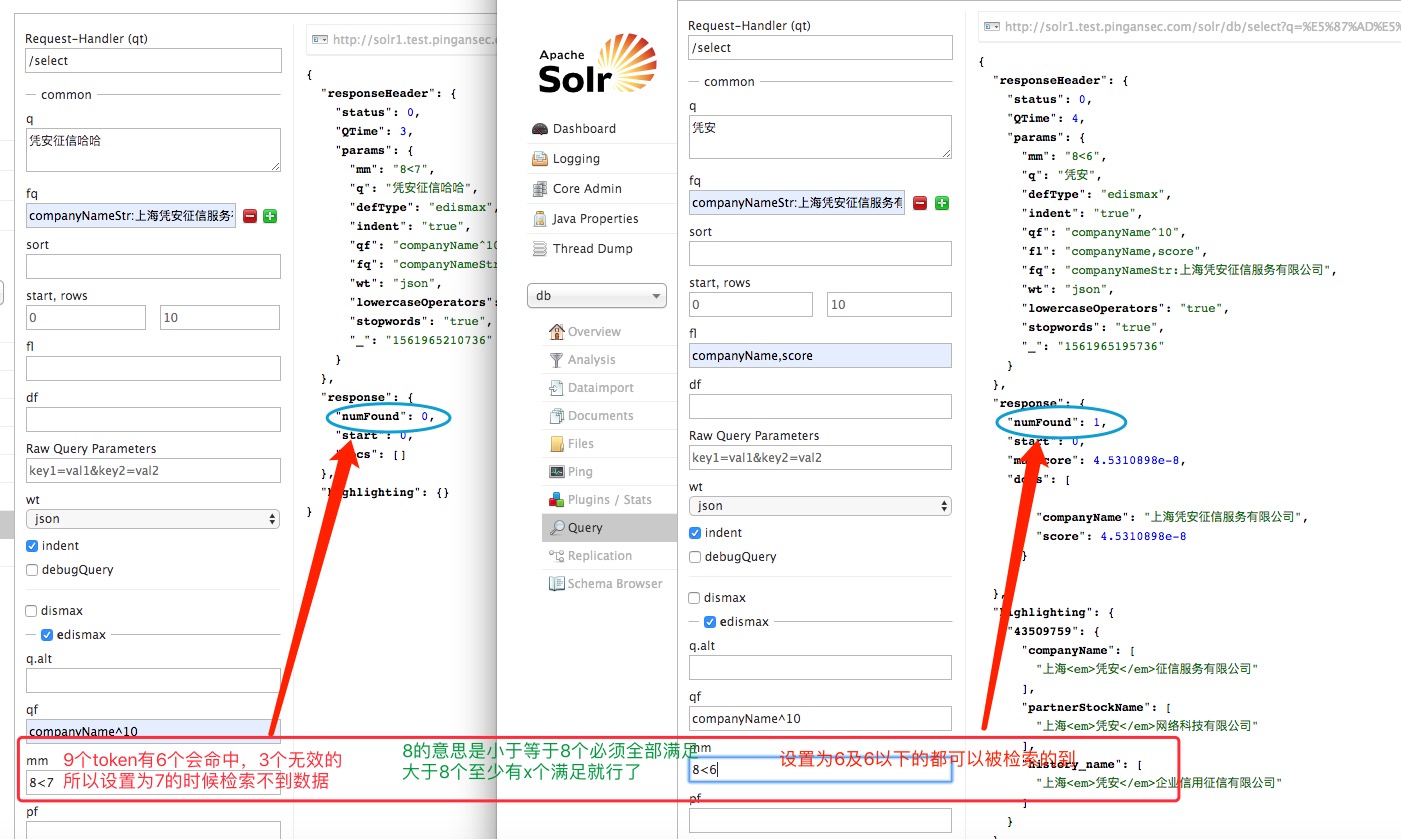
3、mm
查询最小应该匹配:mm没有定义则在solrconfig.xml中默认指定,默认为100%表示全匹配;
- mm为正整数指定最小匹配数量;
- mm为负整数指定匹配最小值减去该值;
- mm为百分比指定返回该相似性的所有结果;
- mm为负数百分比,则指定这部分可以忽略;
Notice:注意使用百分比会向下取整,比如计算值=3.75,那么这个mm就等于3,如果等于0.6这个等于0。
比如 75% 和 -25% 只有在 4 个查询条件时,75%表示至少有三个查询条件必须满足,而-25%则表示至多有一个查询条件不满足,即至少有4个查询条件必须满足
- mm 为表达式如:3<90% 表示:1-3 是都需要的,4- 是 90% 需要的
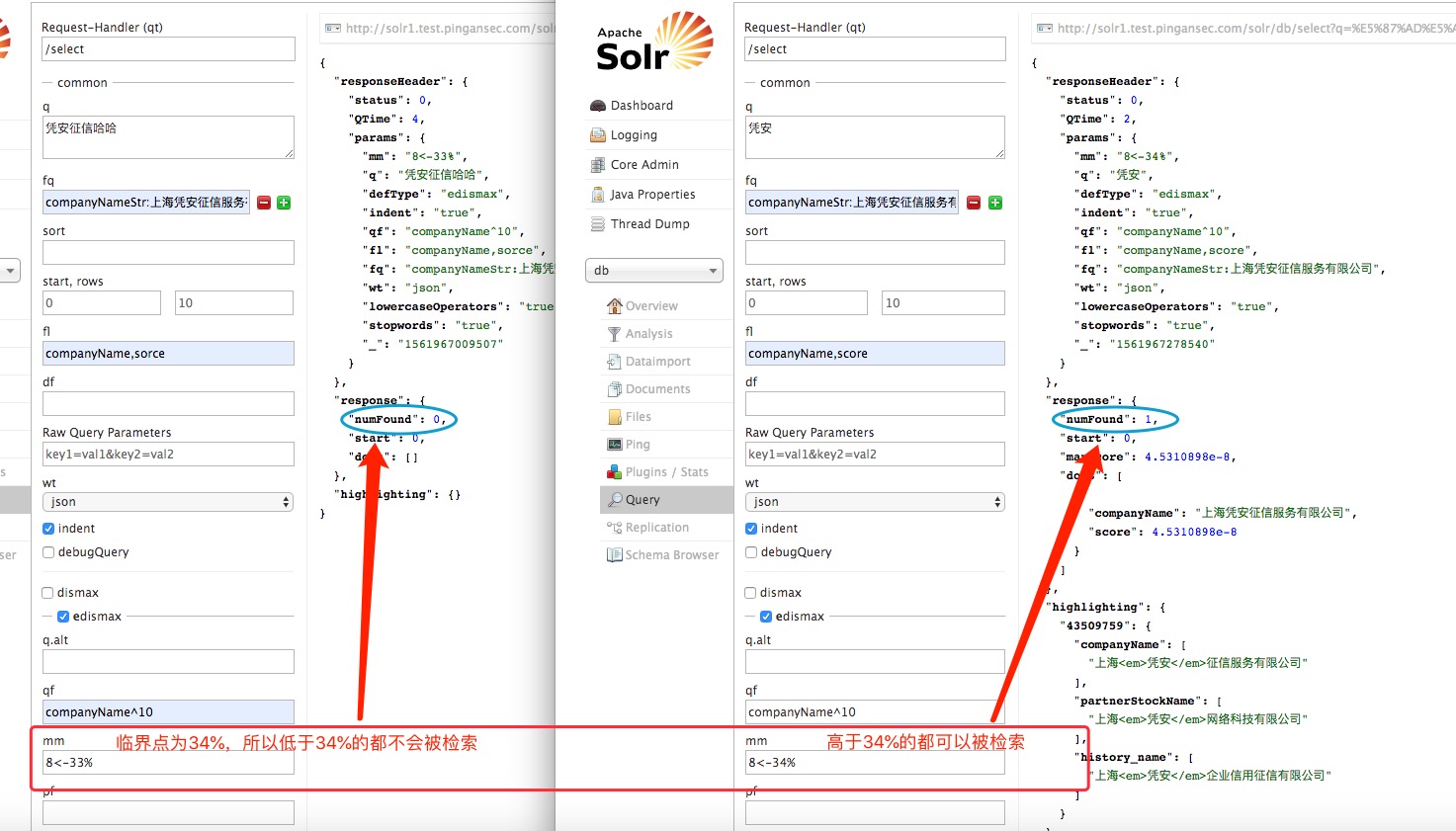
比如我的文档索引与查询查询索引如下:
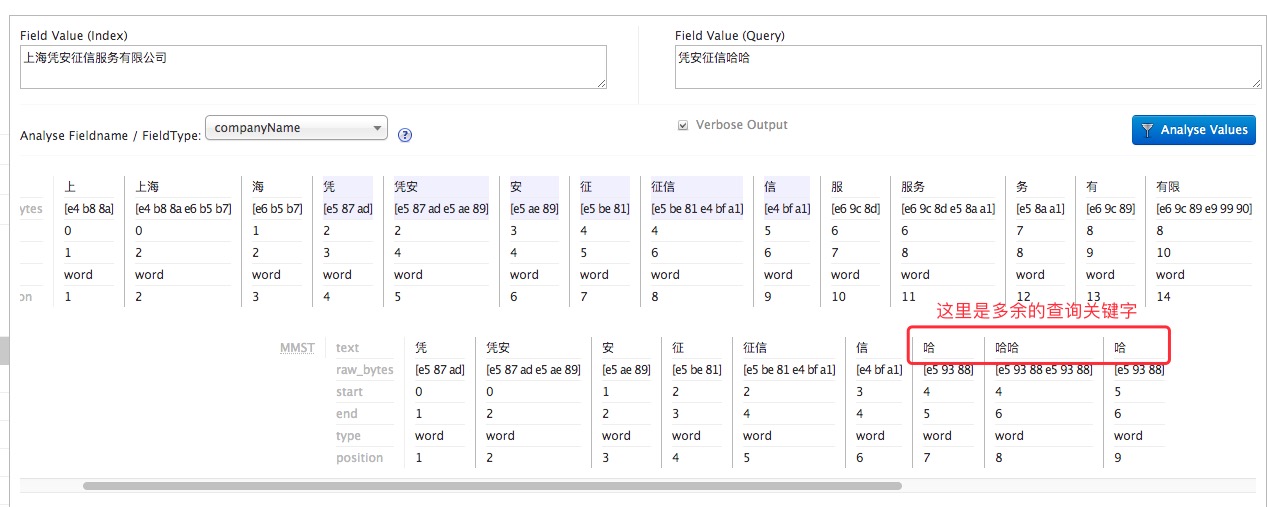
当我使用“上海凭安哈哈”去检索“上海凭安征信服务有限公司”的时候,由于查询索引被分为了9个token,而且有3个是不满足的
使用正数demo:
使用负数demo:

使用百分数demo:
9个token6个有效,3个无效,所以有效率为6/9=0.66666666,无效率3/9=0.33333333
如果设置有效率为 60% 的话,那么 60%*9=5.4,那么取整之后就是 5,肯定不行,所以有效率至少为 67%,因为 67%*9=6.03,那么取整之后就是 6,正好满足 如果设置为 78%,那么取整之后就是 7,所以正百分数时 78% 是一个分界点
同理可的负百分数时的分界点为:-34%,因为 -34%*9=-3.06,取整之后就是 -3

4、pf
主要用于增加匹配文档得分,用于区分相近的查询结果。
注意:当搜索索引全部出现在文档中时会对该参数设定的域进行打分。
查询关键字为“凭安征信”,验证全词匹配且顺序符合 phraseQuery(pf 有效):
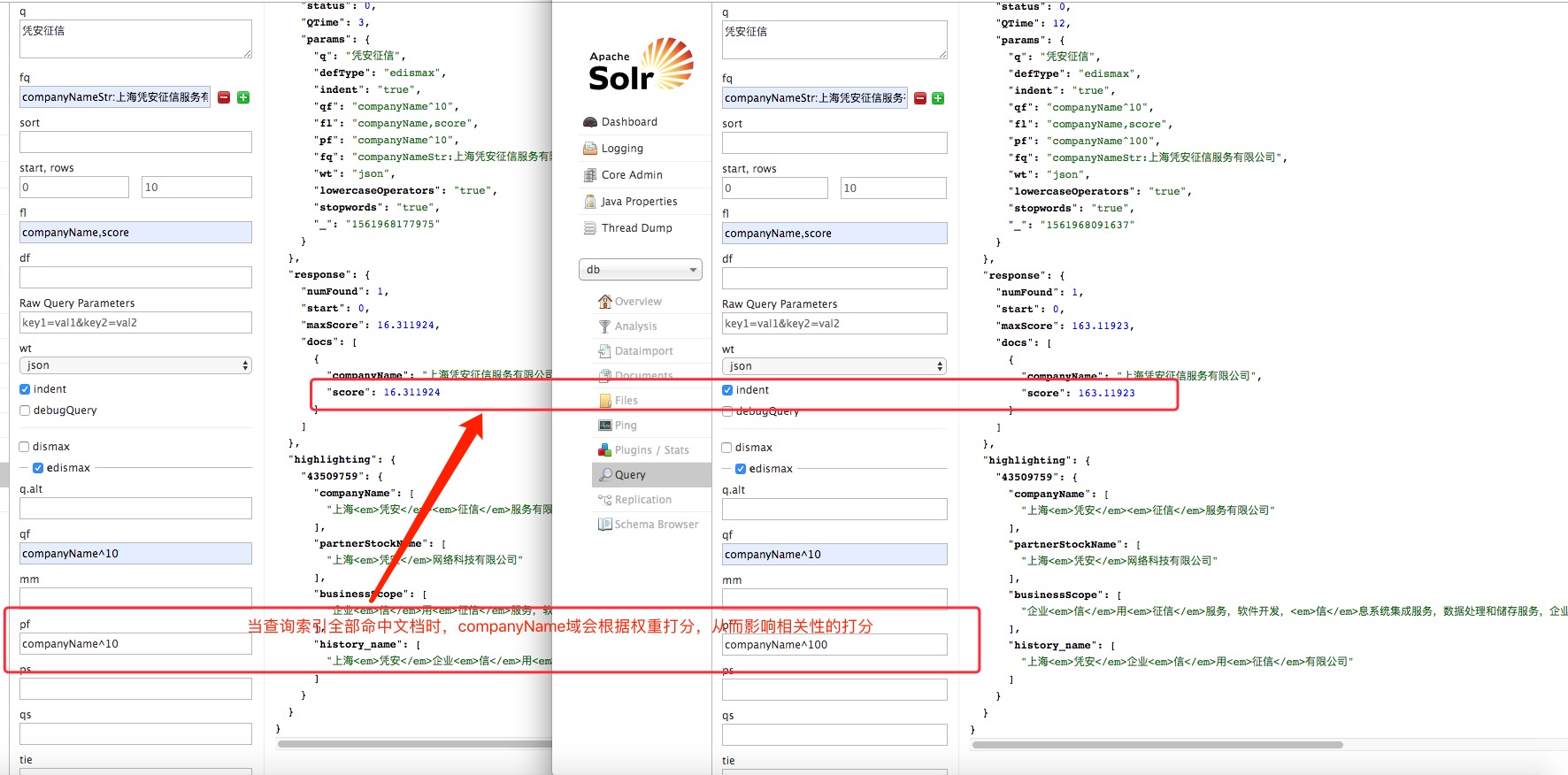
修改查询关键字为“征信凭安”,验证全词匹配但顺序不符合phraseQuery(pf有效):

修改查询关键字啊为“征信凭安坤”验证非全词匹配但顺序符合 phraseQuery(pf 无效):
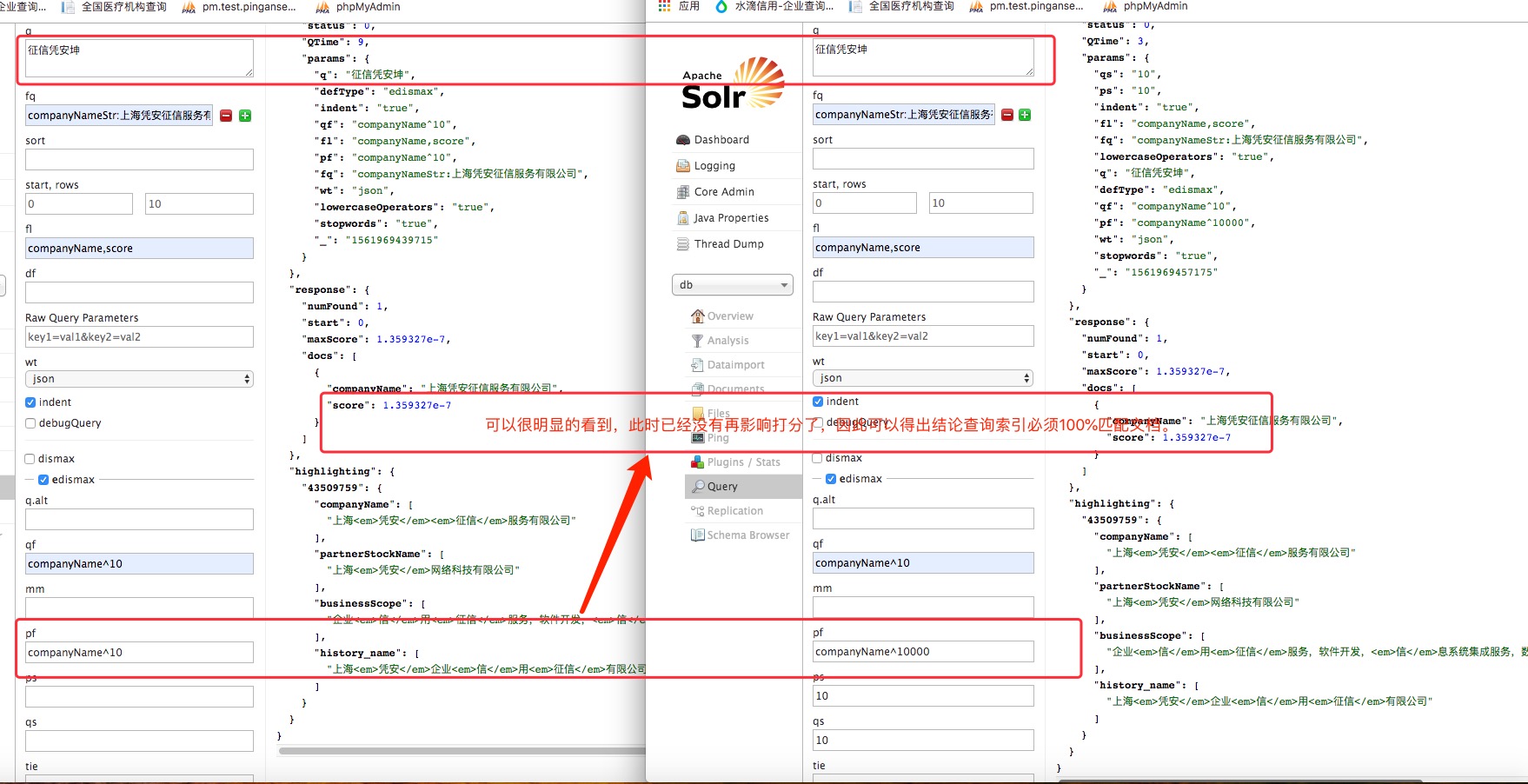
因此,pf 字段的打分前提是,搜索索引必须100%匹配文档,虽然文档token与搜索的token的顺序可以不同(这点跟phraseQuery不同),但是文档的token与搜索token中间不能出现其他词项(可以通过下文的ps参数来调整)。
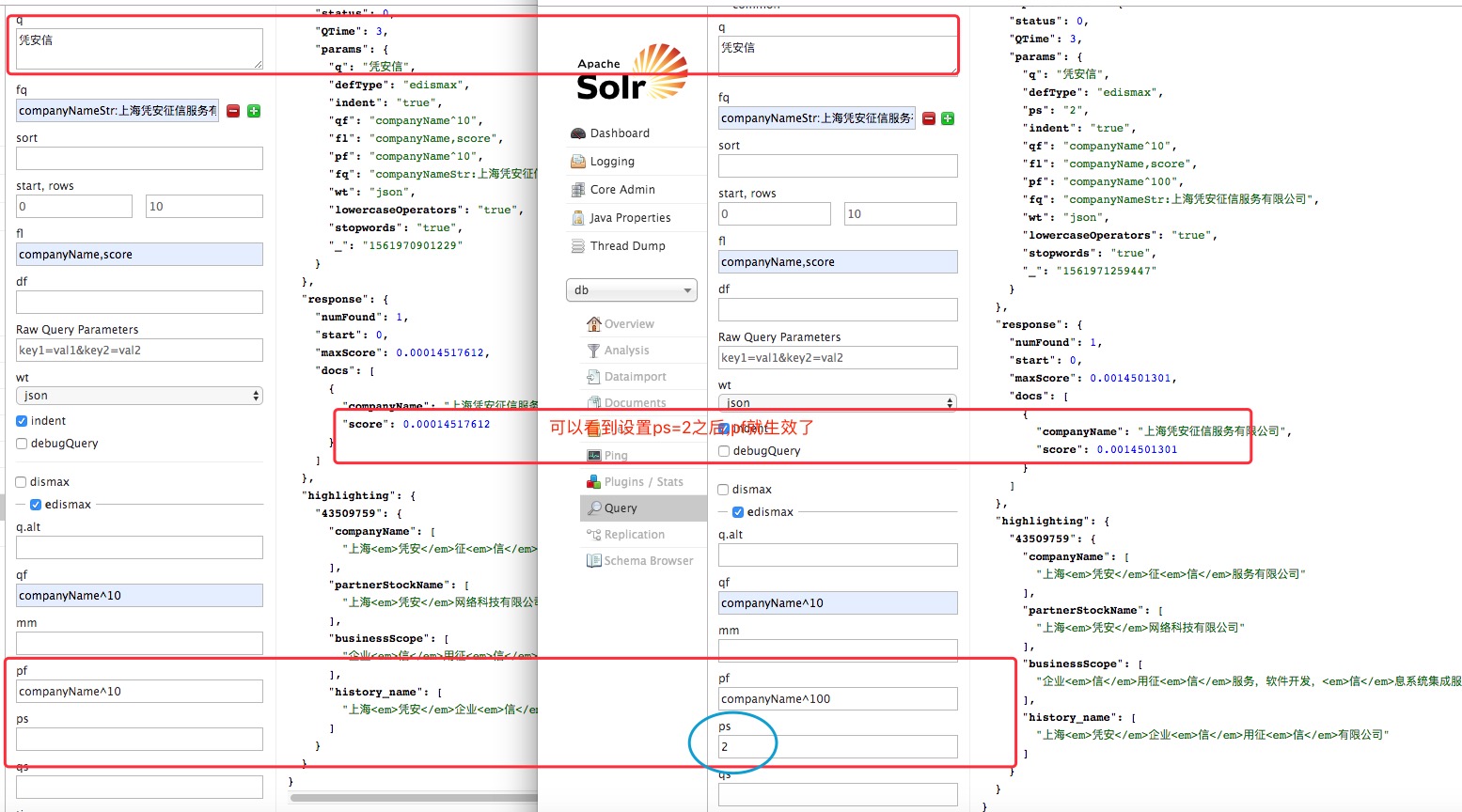
5、ps
用于配置pf中的词项的短语间隔(默认为0)。
用“凭安信”匹配“上海凭安征信服务有限公司”
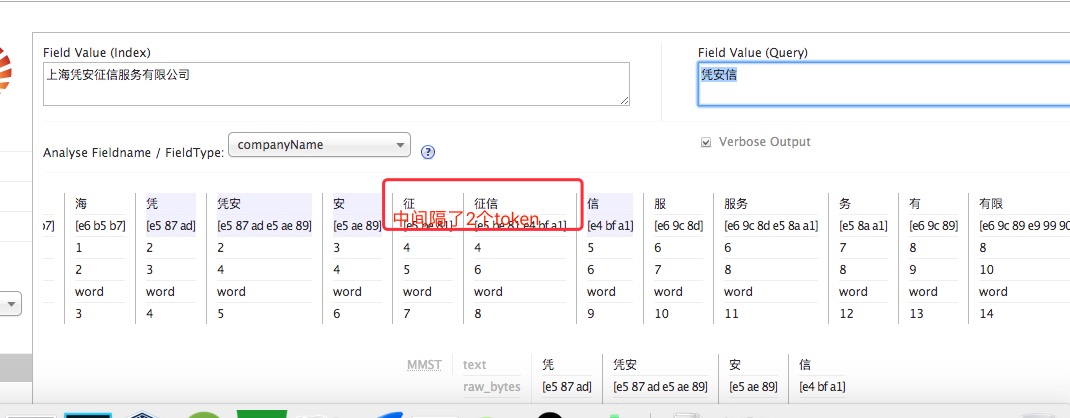
由上图可以看到,文档的 token 中间隔了2个,所以要设置ps大于2才可以影响pf的打分
不设置 ps(pf无效):
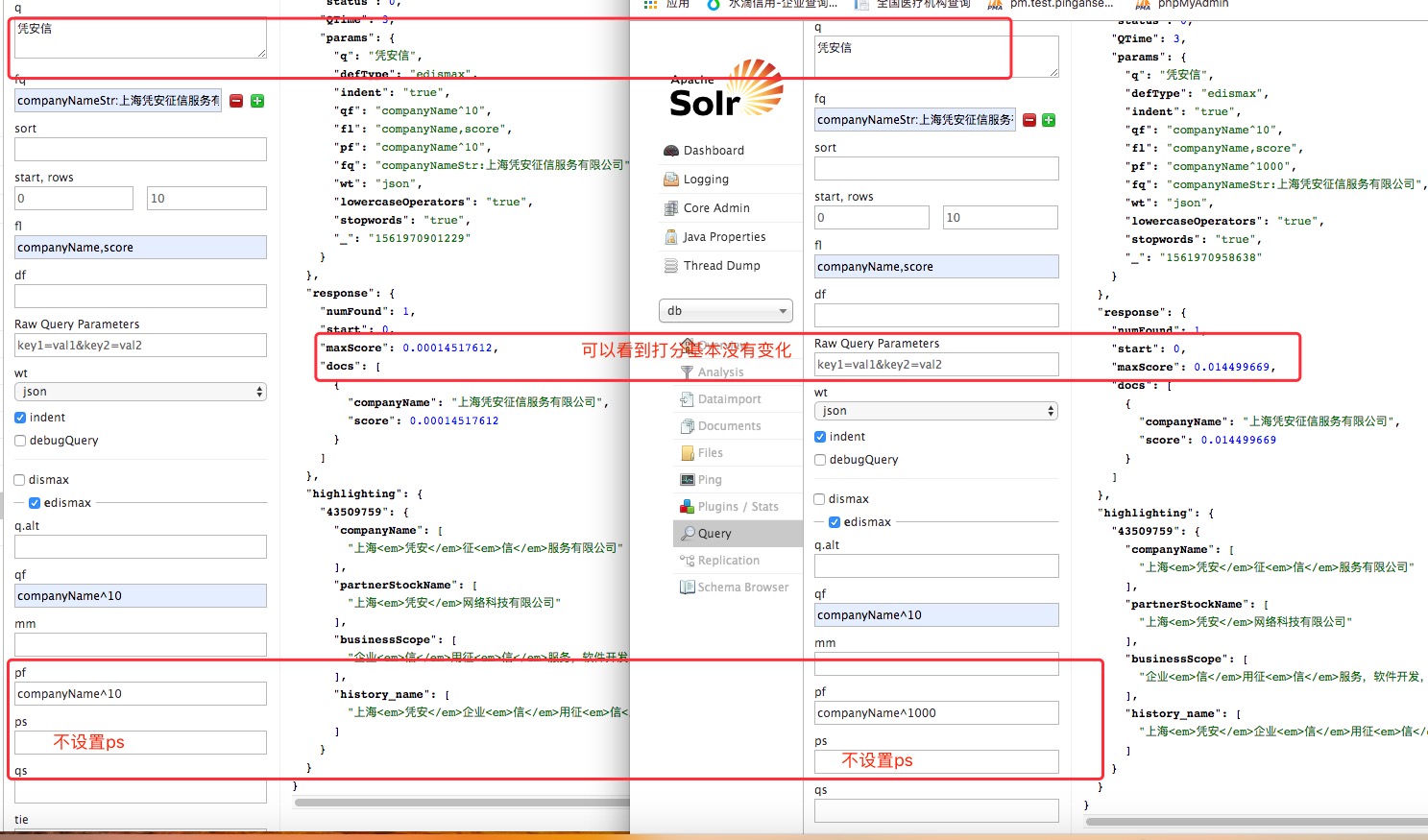
设置ps(pf有效)
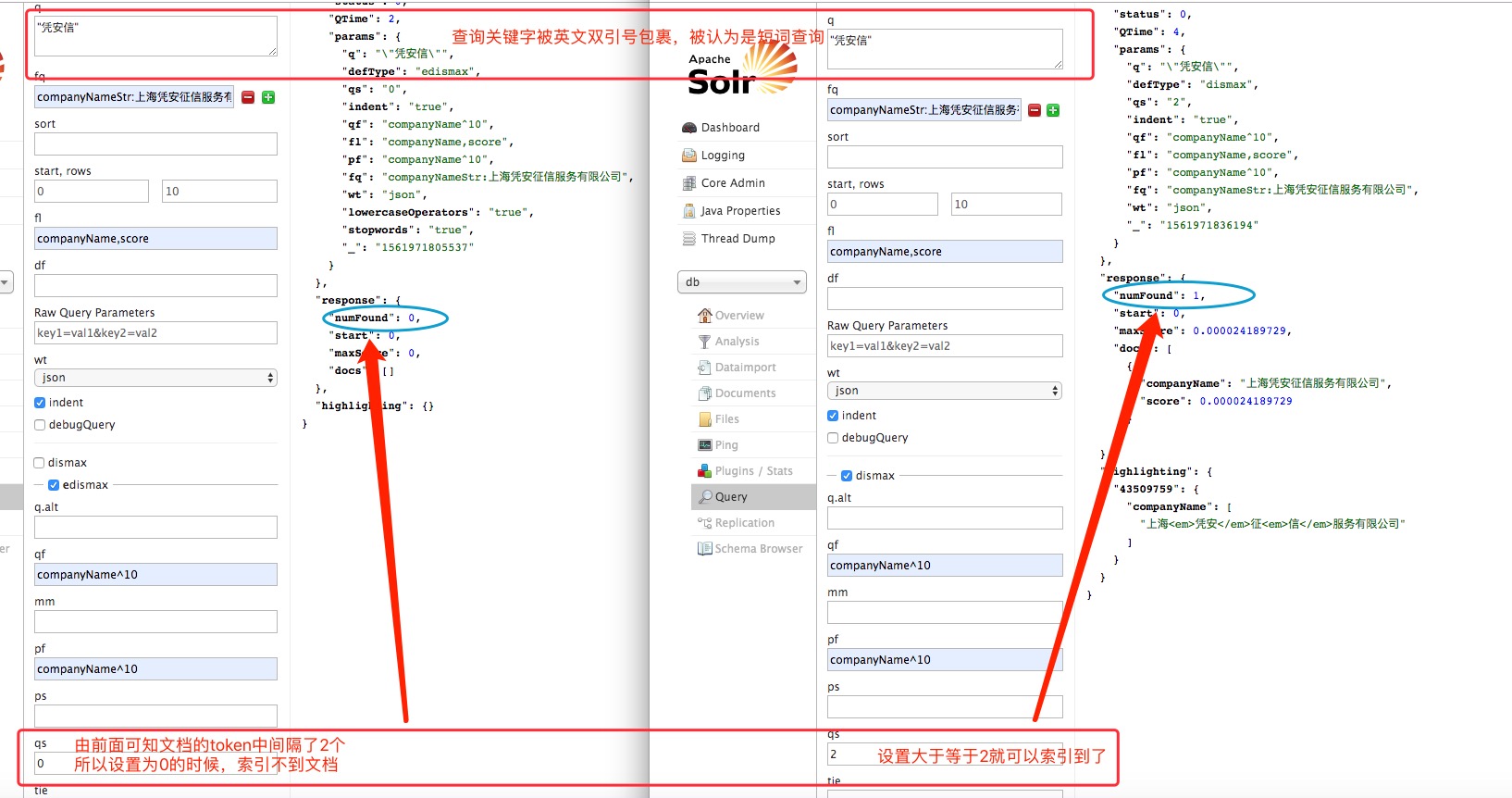
6、qs
当 q 被解析为 phraseQuery 短语时,设置 qs有效。
ps设置短语之间的编辑距编辑距。之间讲过phraseQuery与boolQuery的主要区别是,phraseQuery更注重位置。但是如果位置的前后顺序对了,但是中间隔了几个单词,此时也不能索引到相应的文档。如果你任然想索引到相应的文档,那么可以通过设置ps短语查询编辑距。
注意:qs 参数仅对 phraseQuery 查询有效
7、tie
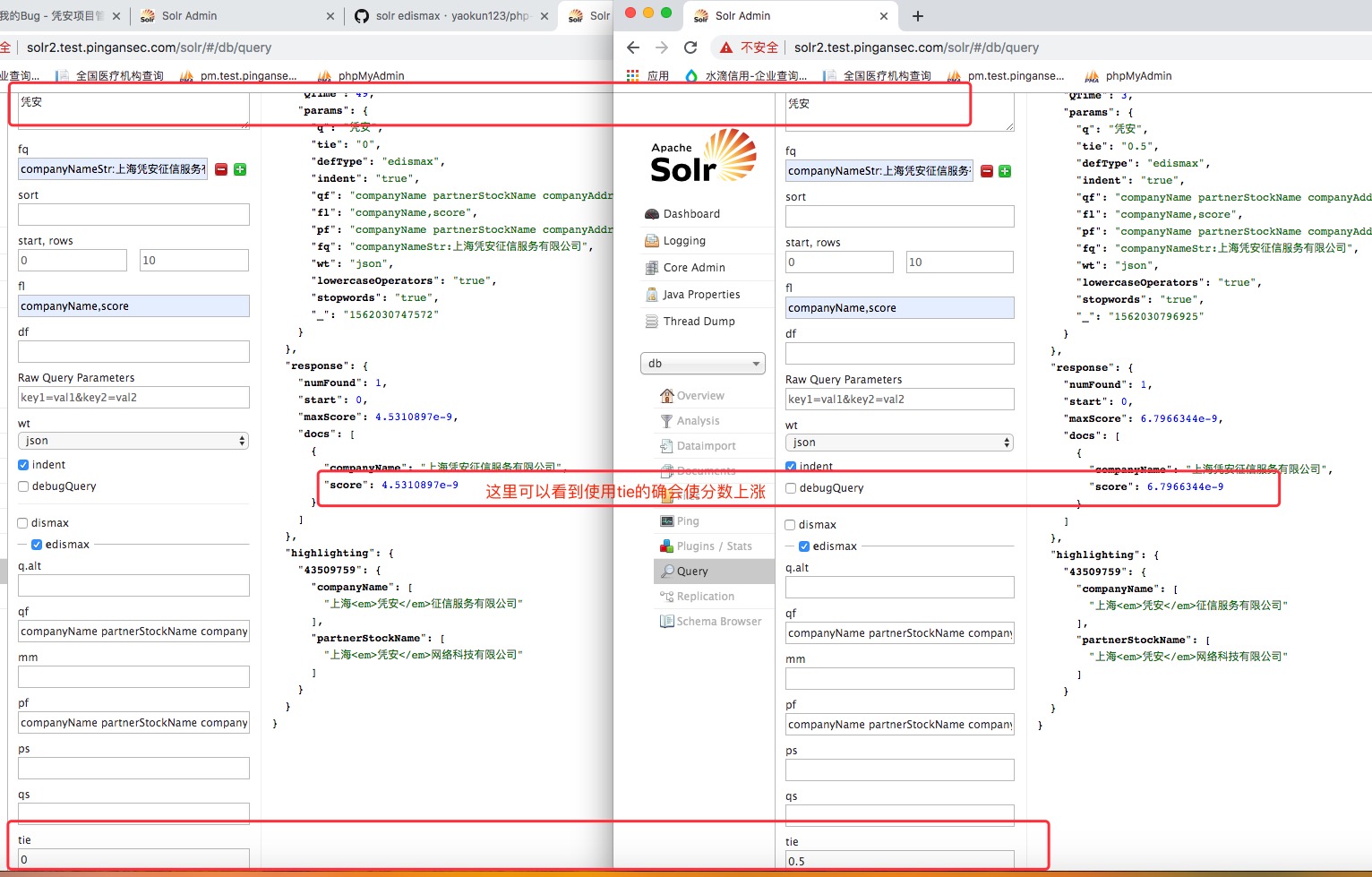
假如你输入的关键字是solr,那么edismax会将其解析为fieldA:solr^2,fieldB:solr^1.2,这样相当于此时有2个子查询,如果是简单的 boolQuery 那么此时会求2个子查询的总和作为最终的得分,而DisjunctionMaxQuery中,则是取2个子查询得分的最高得分作为最终的得分,而有可能两个文档的最终得分相同,这时候为了加大某个文档的权重而引入了tie breaking参数(tie参数不指定,默认是0.0。),计算公式也变为:
最高得分+(tie参数*其他匹配条件的得分)。假如查询在A、B两个域上都有 term 命中,他们的得分可能如下表:
| A | B | 最高分 | |
|---|---|---|---|
| 文档1 | 0.5 | 0.8 | 0.8 |
| 文档2 | 0.8 | 0.1 | 0.8 |
此时两个文档的得分是相同的,但显然这不合理,因为文档1中A、B两个域的得分明显要高些,所以文档1的得分应该高些,所以引入tie参数,再根据上面计算公式重新计算:
文档1的得分=0.8+0.1*0.5=0.85文档2的得分=0.8+0.1*0.1=0.81
从而使得文档1的得分高于文档2,达到预想的结果。
- tie=0.0 表示除了最高分所在域贡献得分之外,其他域不贡献任何相关性得分,即完全按照所有域上得分的最高分作为文档的最后得分,
- tie=1.0 则表示所有域都贡献相关性得分,即相当于求所有域上的相关性总和了,这也是lucene中的查询解析器的处理方式。
8、bq
bq(boost query)指定一个附加的可选查询子句,将添加到用户的主要查询中以影响 score。接受一个和q一样的查询,它和q的区别是不影响返回的结果集,只会影响排名。您可以指定多个 bq 参数。如果您希望将查询作为单独的子句进行分析,请使用多个 bq 参数。
例如,如果您想为最近的文档添加相关性 boost:
q=cheesebq=date:[NOW/DAY-1YEAR TO NOW/DAY]
<str name="bq">
companyType:个体工商户^-1000000000 companyType:农民专业合作社^-1000000000 companyType:农民专业合作经济组织^-1000000000
companyType:个人独资企业^-1000000000 companyType:村经济合作社^-1000000000 companyType:合作社^-1000000000
companyType:个体^-1000000000
</str>
9、bf
bf(Boost Functions)参数指定将用于构造 FunctionQueries 的函数(具有可选的 boosts),该函数将作为将影响 score 的可选子句添加到用户的主查询中。可以使用由 Solr 本地支持的任何函数,以及 boost 值。
提升函数,通过数学公式来影响评分,而且不局限在qf中的字段。
使用 bf 参数指定函数本质上只是使用 bqparam 与 {!func} 解析器结合的简写。 例如:
<str name="bf"> if(not(exists(companyType)),-1000000000,0)
</str>
10、pf/pf2/pf3
pf参数可以用于对邻近Term的索引文档的评分进行加权。pf参数与qf参数使用相同的格式,你可以指定多个域,同时可以为每个域单独指定权重,多个域之间使用逗号分割,eDisMax会尝试对q参数中指定的查询文本中包含的所有term构造一个phrase query(待定),如果在pf参数指定的域上能够精确匹配到索引文档,那么就会将指定的权重应用到匹配到的索引文档上。
除了pf参数之外,eDisMax查询解析器还支持pf2、pf3参数,这些参数的功能与pf参数类似,但是pf2、pf3参数并不需要匹配q参数中包含的所有trem,pf2参数只需要匹配两个词组成的trem,而pf3参数只需要匹配三个词组成的trem即可。
11、ps/ps2/ps3
当你使用pf参数时,你可能不希望查询中所有trem都精确匹配,你可以使用ps(phrase slop)参数,这样只要两个trem之间间隔的其他trem的个数在phrase slop限定的范围内,那么就认为该索引文档匹配查询条件应该被返回。eDismax 查询解析器还支持 ps2、ps3 参数,它允许覆盖默认的ps参数值,当ps2和ps3参数未指定时,默认会使用ps参数值。ps2与pf2参数相对应,ps3与pf3参数相对应。也就是说ps参数需要跟pf参数搭配使用才有意 义。
使用搜索关键字“迪卡侬哈哈”检索文档“迪卡侬(上海)体育用品有限公司”分词如下:
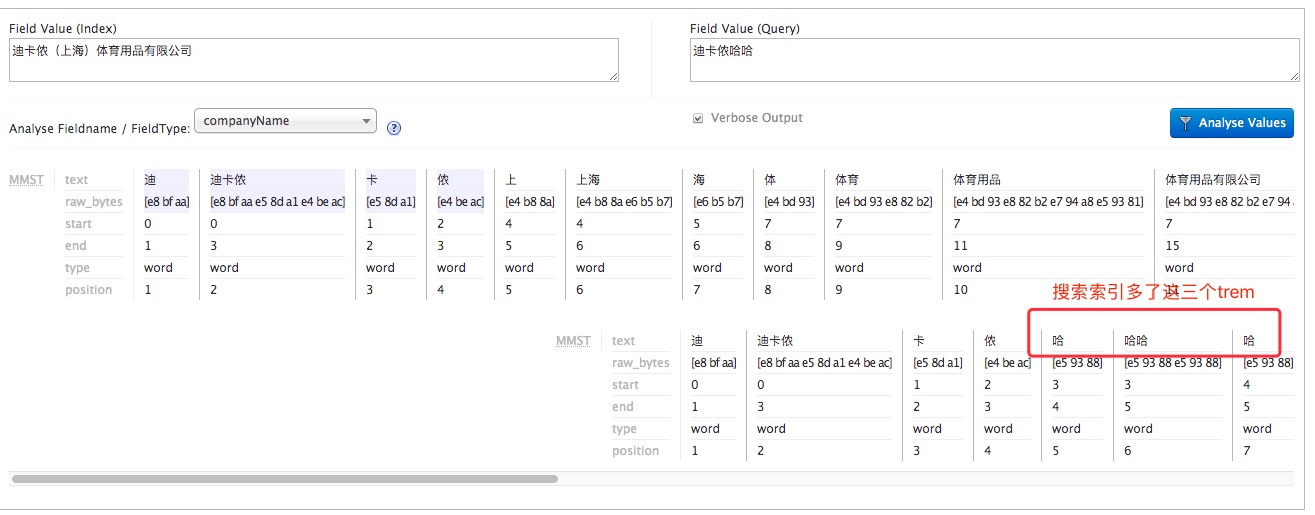
我们看到,多了哈哈、哈、哈这三个 trem 所以没有全部命中文档,因此pf设置的域不会影响到打分,如下:
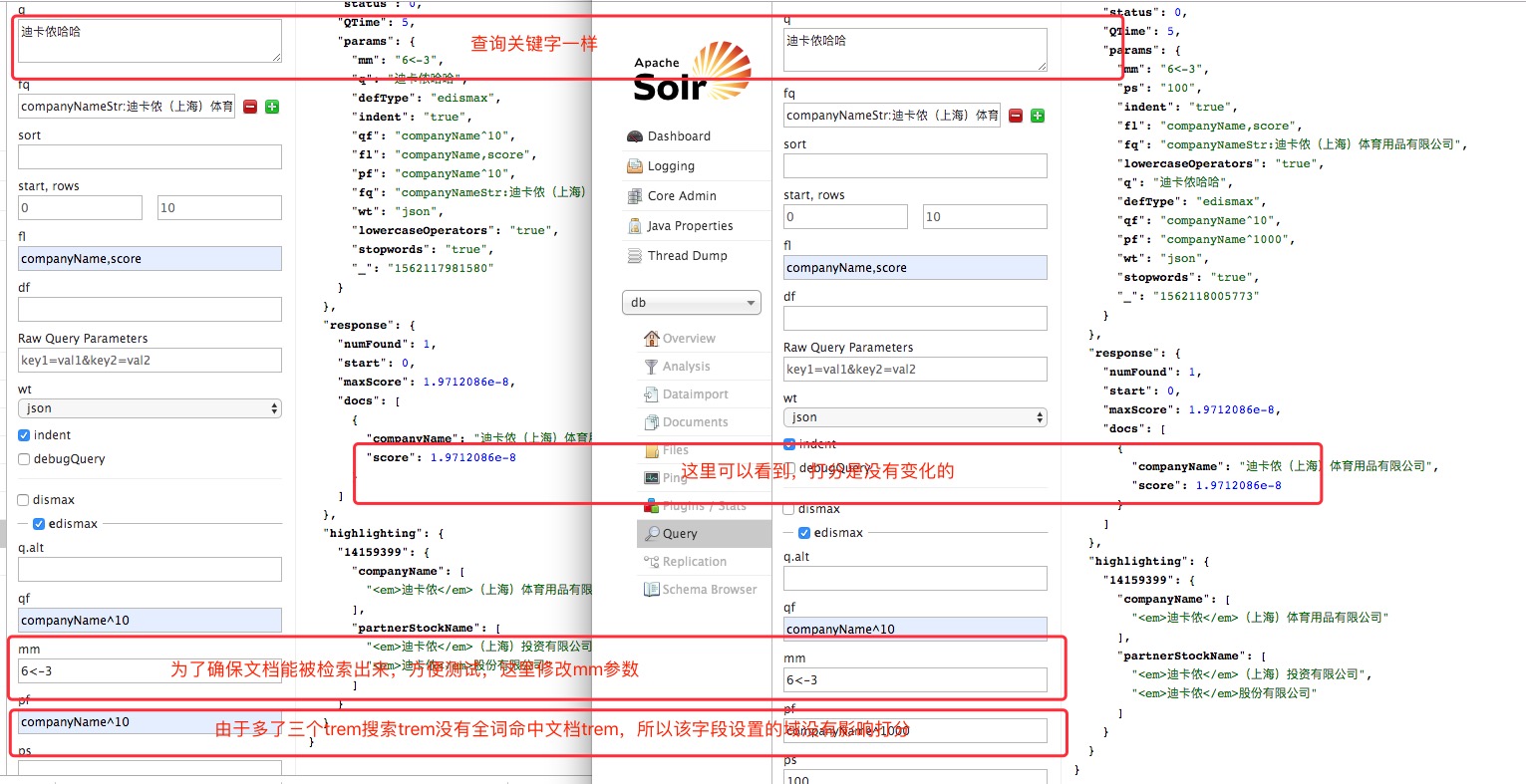
那么此时如果我们想设置影响打分就可以使用 pf2、pf3 参数了,在这里的 demo 选取了 ps3,因为上面知道“迪卡侬”会被分成一个 trem 的。
12、boost
分析为查询的字符串的多值列表,并将其分数乘以所有匹配文档的主查询的分数。
<str name="boost"> if(sum(scoreSort,queryTimes),
if(product(queryTimes,scoreSort),
sum(log(sum(1,product(queryTimes,10))),
log(sum(0.1,product(scoreSort,10)))),
if(queryTimes,product(log(sum(1,product(queryTimes,1))),0.00001),
product(log(sum(1,product(scoreSort,1))),0.01))),
product(max(establishDuration,1),0.00000000001))
</str>
以上是 solr 的 edismax 详解 的全部内容, 来源链接: utcz.com/p/233754.html