
Python爬虫实战之萝卜投研
声明:以下内容均为我个人的理解,如果发现错误或者疑问可以联系我共同探讨
爬虫介绍
网站介绍
本次要爬取的网站为萝卜投研,是利用人工智能、大数据、移动应用技术,建立的股票基本面分析智能投研平台,在进行投资交易的时候可以使用期研报与各类数据进行分析。
编写爬虫的原因和用途
本人闲暇时间会学习投资理财相关内容,萝卜投研可以获取许多财经类的信息与很多研报,本次想通过编写爬虫完成对目标数据完成持久化存储与相关舆情完成程序提醒的目标,由于网站内容十分丰富,一次很难将其全部爬取完毕,本次想通过Scrapy获取首页的投研信息,并完成翻页的目标,后期还会持续更新,尝试将整个网站都爬下来。(仅供个人研究使用)
Scrapy
简介
Scrapy是一个为了爬取网站数据,提取结构性数据编写的爬虫框架,只需要很少的代码就可以完成相关数据的抓取。
Scrapy是一个使用了Twisted的异步网络框架,可以大大提高我们的下载速度。
使用教程
Scrapy的相关使用教程可以通过官方文档来进行初步入门,了解各模块在框架中的作用,官方文档非常强大,建议先进行系统性的学习之后再开始使用。
学习Scrapy最重要的就是理解Scrapy的工作流程,跟着官方文档的例子去详细分析每一步的操作,与之前编写爬虫的流程相关性与区别。
抓包工具
什么是抓包工具
抓包工具是拦截查看网络数据包内容的软件。通过对抓获的数据包进行分析,可以得到有用的信息。
为什么要用
较为复杂的网站在进行爬取数据分析的时候使用浏览器中的调试工具会比较麻烦,这时候就可以用抓包工具去分析对应的请求,从而更快发现我们需要的数据所在的URL和整个请求的过程
使用与抓包工具的推荐
抓包工具的使用推荐学习朱安邦的博客中的教程,他讲了三个:Charles、Fiddler、wireshark,这些抓包工具功能各异,但基本原理相同,找一个顺手的学习基本上已经足够了。
业务逻辑分析
寻找加载数据的URL
通过对整个首页加载的流程进行抓包与分析,发现首页数据的URL为https://gw.datayes.com/rrp_mammon/web/feed/list,下一页的URL为:https://gw.datayes.com/rrp_mammon/web/feed/list?timeStamp=20210401170127&feedIds=66233,66148,
翻页参数解析
通过观察URL发现timeStamp和feedIds是两个控制翻页的参数,进一步多页进行请求发现20210401170127可以理解为一个时间节点,看到20200228猜测是本次刷新的时间,猜测后6位是当前时间的秒的时间戳,组织一下可以写成''.join(str(datetime.now())[:10].split('-'))+str(time.clock( )).split('.')[1]
再进行多页的数据获取后发现feedIds参数中的前四个是第一个响应中前四个数据的id,最后一个数为响应中最后一个数据的id,并且会随着访问变多而增加,每次新增的都是最后一个数据的id,将下一页的URL拼接起来,进行访问发现请求不到下一页的数据。通过复制原来的timeStamp发现可以访问,问题就出现在前面timeStamp的参数,刚刚再进行feedIds字段拼接的时候发现有三个字段是日期形式的,分别为:"insertTime"、updateTime、publishTime,进一步分析发现将其后面三个0去掉就是一个时间戳,对其转换发现就是我们需要的结果
模拟请求测试
scrapy shell
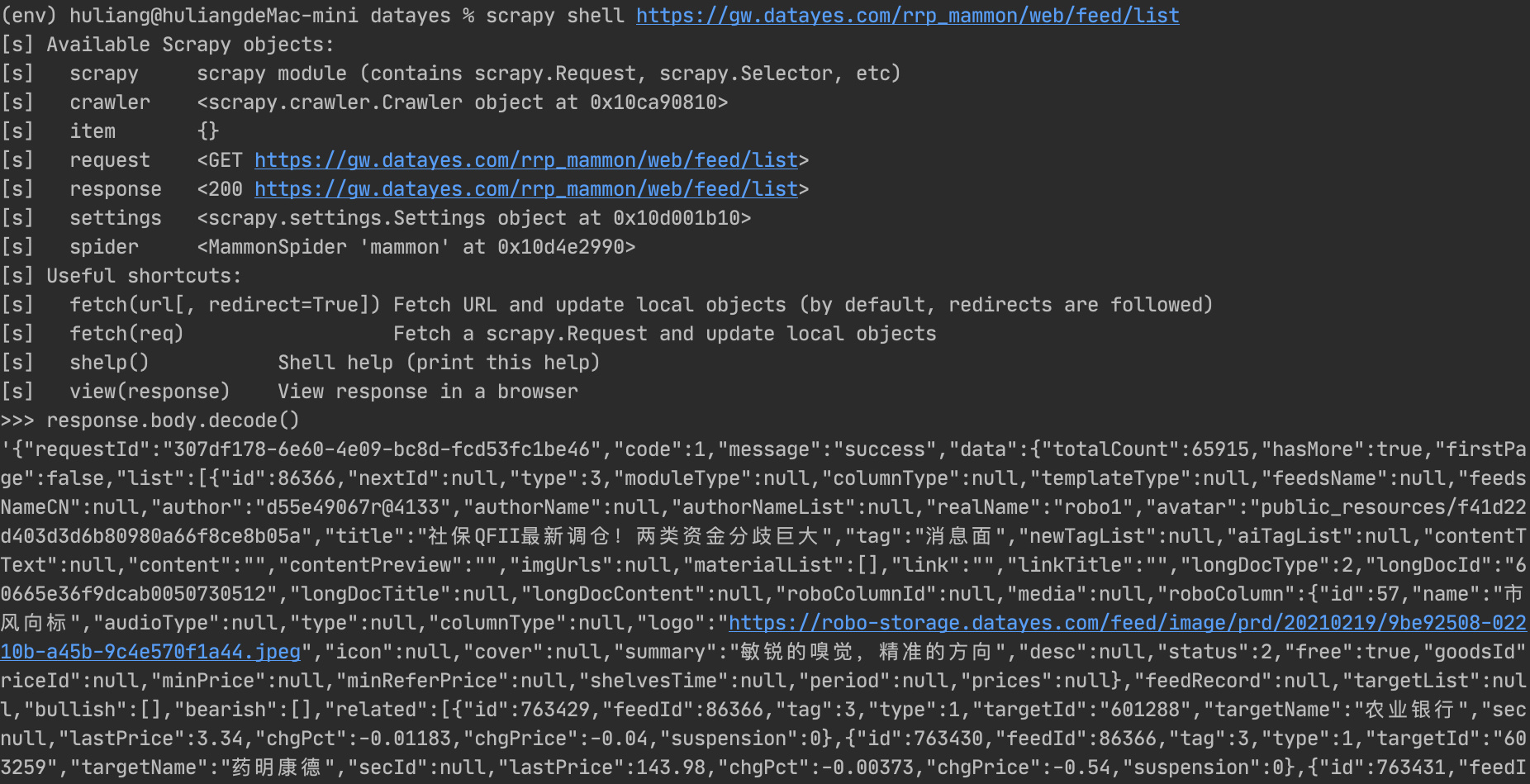
scrapy shell可以帮助我们模拟请求地址,并进入一个交互式终端,在交互式终端中我们可以查看请求的各类信息,并进行调试。但scrapy shell也有缺陷,不能解析response的格式,看起来比较乱等,这时候可以通过结合Postman来协同调试。
Postman
简介
Postman是一种网页调试与发送网页http请求的chrome插件。我们可以用来很方便的模拟各种类型的请求来调试 接口。在爬虫中可以用于验证我们的思路。
使用与汉化
Postman官方的使用教程非常详细,可以跟着官方的使用教程中学习,如果想使用中文的版本可以在Postman汉化中下载。
实际使用
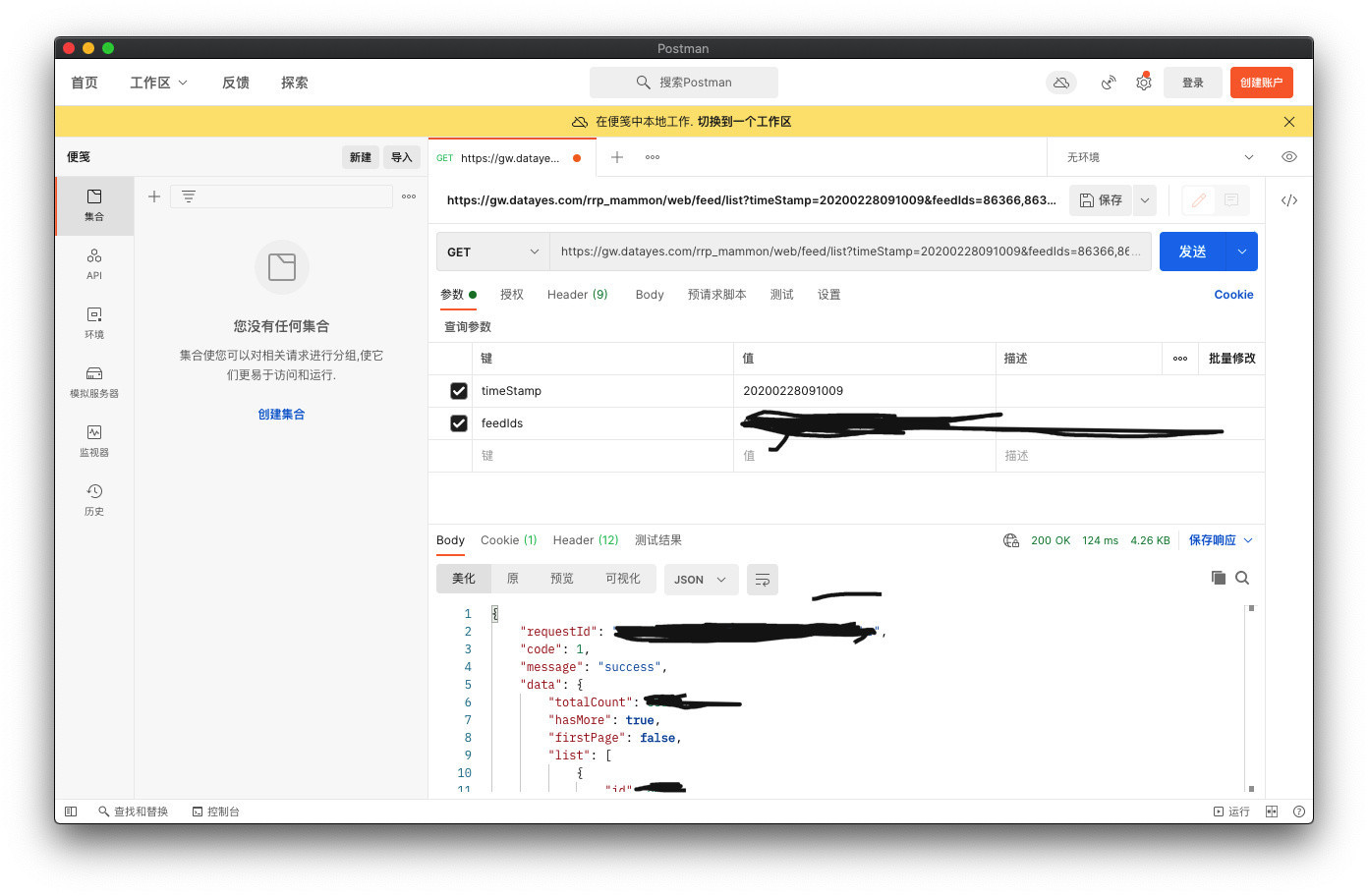
通过Postman发送请求,可以得到我们想要的数据,并且可以得到格式化后的数据,看起来条理更加清晰,再配合scrapy shell调试可以很容易就获得我们需要的数据
编写爬虫
创建爬虫项目
scrapy startproject datayesrobots协议
在settings.py中可以通过设置ROBOTSTXT_OBEY = True遵守robots.txt 的规则。
创建爬虫
scrapy genspider mammon gw.datayes.com修改start_urls
默认的start_urls不是我们要爬取的链接,修改为我们需求的链接
start_urls =['https://gw.datayes.com/rrp_mammon/web/feed/list']完成parse方法
根据之前分析的结果设计方案完成parse,这次难度主要在于如何拼接next_url,由于feedIds参数存在着累加的关系所以将其放在了parse函数外让其可以再访问的时候累加处理。
classMammonSpider(scrapy.Spider): name ='mammon'
allowed_domains =['gw.datayes.com']
start_urls =['https://gw.datayes.com/rrp_mammon/web/feed/list']
# 构建一个基础next_url
next_url ='https://gw.datayes.com/rrp_mammon/web/feed/list?timeStamp='
# 构建一个基础feedIds
feedIds ='&feedIds='
defparse(self, response):
# 将获取到的数据通过json转成字典的形式
result = json.loads(response.text)
# 当访问成功时进行数据获取
if result['message']=='success':
data_list = result['data']['list']
for data in data_list:
item ={}
detail_id = data['id']# id
# 通过详情页id构造详情页url并访问
detail_url ='https://gw.datayes.com/rrp_mammon/web/feed?id='+str(detail_id)
yield scrapy.Request(detail_url, callback=self.detail_parse, meta={'item': item})
item['title']= data['title']# 标题
item['publish_time']=int(data['publishTime']/1000)# 发布时间
item['author']= data['roboColumn']['name']# 作者
item['Avatar']= data['roboColumn']['logo']# 头像
related_list = data['related']
item['related_stocks']=[]# 相关股票列表
for stocks in related_list:
item['related_stocks'].append(stocks['targetName'])
# 寻找出url的第0,1,2,3位置的id,加入feedIds
if response.request.url =='https://gw.datayes.com/rrp_mammon/web/feed/list'and data_list.index(data)in[0,1,2,3]:
self.feedIds = self.feedIds +str(detail_id)+','
# 构建timeStamp参数
timeStamp = time.strftime("%Y%m%d%H%M%S", time.localtime(item['publish_time']))
# 拼接feedIds参数
self.feedIds = self.feedIds +str(detail_id)+','
# 组合next_url
next_url = self.next_url + timeStamp + self.feedIds
# 请求下一页
yield scrapy.Request(next_url, callback=self.parse)
defdetail_parse(self, response):
result = json.loads(response.text)
if result['message']=='success':
item = response.meta['item']
item['content']= result['data']['longDocContent']
yield item
通过爬虫观察到两日的cookie发生了变化,只有登录之后会保持cookie,并对cookie中的参数进行检测,找到cloud-sso-token为必要参数,并将其添加在settings.py中。
完成数据存储
先在settings.py中配置pipeline,和数据库相关参数
# Configure item pipelines# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES ={
'datayes.pipelines.DatayesPipeline':300,
}
# MySQL相关配置
HOST ='HOST',# 数据库地址
PORT =3306,# 数据库端口
DB ='DB',# 数据库名
USER ='USER',# 数据库用户名
PASSWORD ='PASSWORD',# 数据库密码
在我们定义的DatayesPipeline类中添加open_spider和close_spider方法,通过spider.settings来导入数据库相关参数
import pymysqlclassDatayesPipeline:
# 爬虫开始时执行,只执行一次
defopen_spider(self, spider):
# 通过pymysql链接MySQL数据库
self.connect = pymysql.connect(
host=spider.settings.HOST,# 数据库地址
port=spider.settings.PORT,# 数据库端口
db=spider.settings.DB,# 数据库名
user=spider.settings.USER,# 数据库用户名
passwd=spider.settings.PASSWORD,# 数据库密码
charset='utf8',# 编码方式
use_unicode=True)
# 通过cursor执行增删查改
self.cursor = self.connect.cursor()
# 爬虫结束时执行,只执行一次
defclose_spider(self, spider):
self.connect.close()
defprocess_item(self, item, spider):
self.cursor.execute(
"""insert into mammon (title, publish_time,author,avatar,related_stocks,content)value (%s, %s,%s, %s,%s, %s)""",
(item['title'], item['publish_time'], item['author'], item['avatar'], item['related_stocks'],
item['content']))
# 提交sql语句
self.connect.commit()
return item
最后创建数据库,开启爬虫进行数据爬取。
以上是 Python爬虫实战之萝卜投研 的全部内容, 来源链接: utcz.com/p/217228.html




