
Python爬虫实战之叩富网
声明:以下内容均为我个人的理解,如果发现错误或者疑问可以联系我共同探讨
爬虫介绍
爬虫是一种按照一定规则自动抓取网络上的信息数据的程序。我们身处一个大数据的时代,可以通过爬虫获取到我们所需要的数据(遵从robots协议中的规则)。
网站介绍
叩富网是江西博辰网络科技公司旗下的一个专业网站。模拟炒股网站初建于2000年,2006年被博辰网络收购,并开始规范系统的运作。目前用户100多万,日均IP数10万左右。是国内唯一一家专业致力于模拟炒股开发和运营的网站。公司旗下有有奖大赛站、免费大赛站以及和其他证券公司合作的网站。
编写爬虫的原因和用途
本人闲暇时间会学习投资理财相关内容,并通过叩富网进行模拟炒股,本次想通过编写爬虫来程序化自己的模拟交易
robots协议
什么是robots协议
robots协议以robots.txt文件形式呈现,是网站中给各类爬虫规定爬取范围的文件,robots.txt存放在网站的根目录下。我们准备爬取某个网站时,首先应该查看我们需要的数据该网站是否允许我们爬取,当我们爬取规则之外的数据时,该网站有权利起诉我们非法获取数据。
robots协议的构成
由User-agent、Allow、Disallow构成。User-agent后面的内容是具体的爬虫名,如百度爬虫为Baiduspider,则代表所有爬虫。Allow后面的内容是允许爬取的URL路径,如/.jpg$表示可以爬取该网站下的所有.jpg图片,/表示所有路径均允许爬取。Disallow后面的内容是不允许爬取的URL路径,同Allow相反。
常见的规则有哪些
允许爬虫获取所有内容:
User-agent:*Disallow:
# 或者
User-agent:*
Allow:/
禁止爬取所有内容:
User-agent:*Disallow:/
禁止访问网站中所有动态页面
User-agent:*Disallow:/*?*
禁止搜索引擎抓取网站上所有图片
User-agent:*Disallow:/*.jpg$
Disallow: /*.jpeg$
Disallow: /*.gif$
Disallow: /*.png$
Disallow: /*.bmp$
Feeling
爬虫可以使我们更加高效的获取到互联网中的各类数据,但网络不是法外之地我们也要在合规合法的基础上进行爬取,尊重每一个网站开发者,敬畏法律。
requests
requests库是学习爬虫入门最适合的一个第三方库,它是将Python内置的urllib进行深度封装的库。是一个非常成熟的HTTP客户端库,当然他也并非完美,我们后期也可以在其基础上进行补充形成适合自己的一个库。
快速上手
中文文档:docs.python-requests.org/zh_CN/lat...
官方示例:docs.python-requests.org/zh_CN/lat...
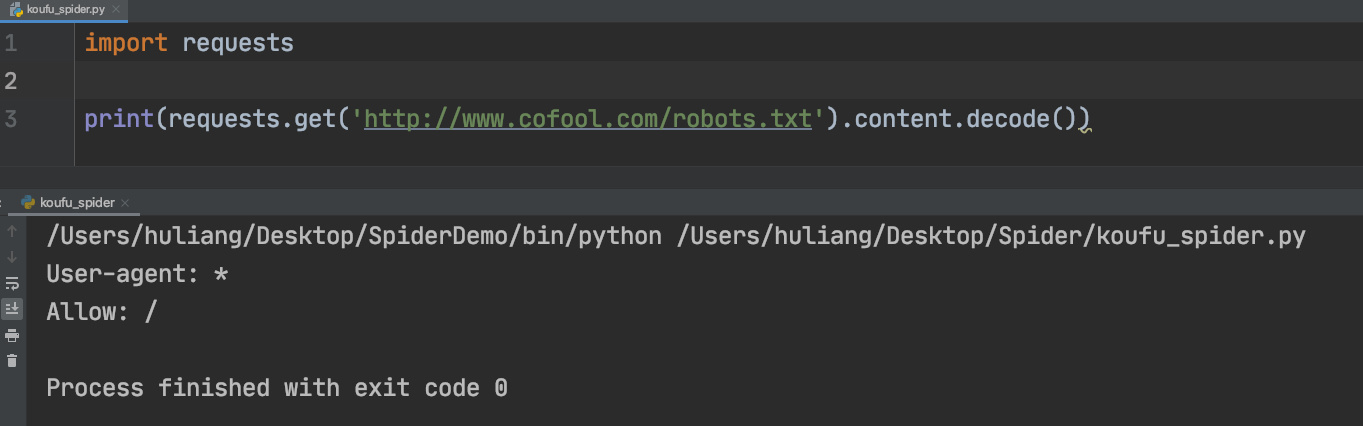
获取robots协议,查看可爬取范围
使用get请求获取协议内容,并将其输出控制台查看发现规则允许我们爬取整站内容
登陆叩富网
在Chrome浏览器中通过开发者选项中的Network选项卡中发现,登陆的时候有一个login.html
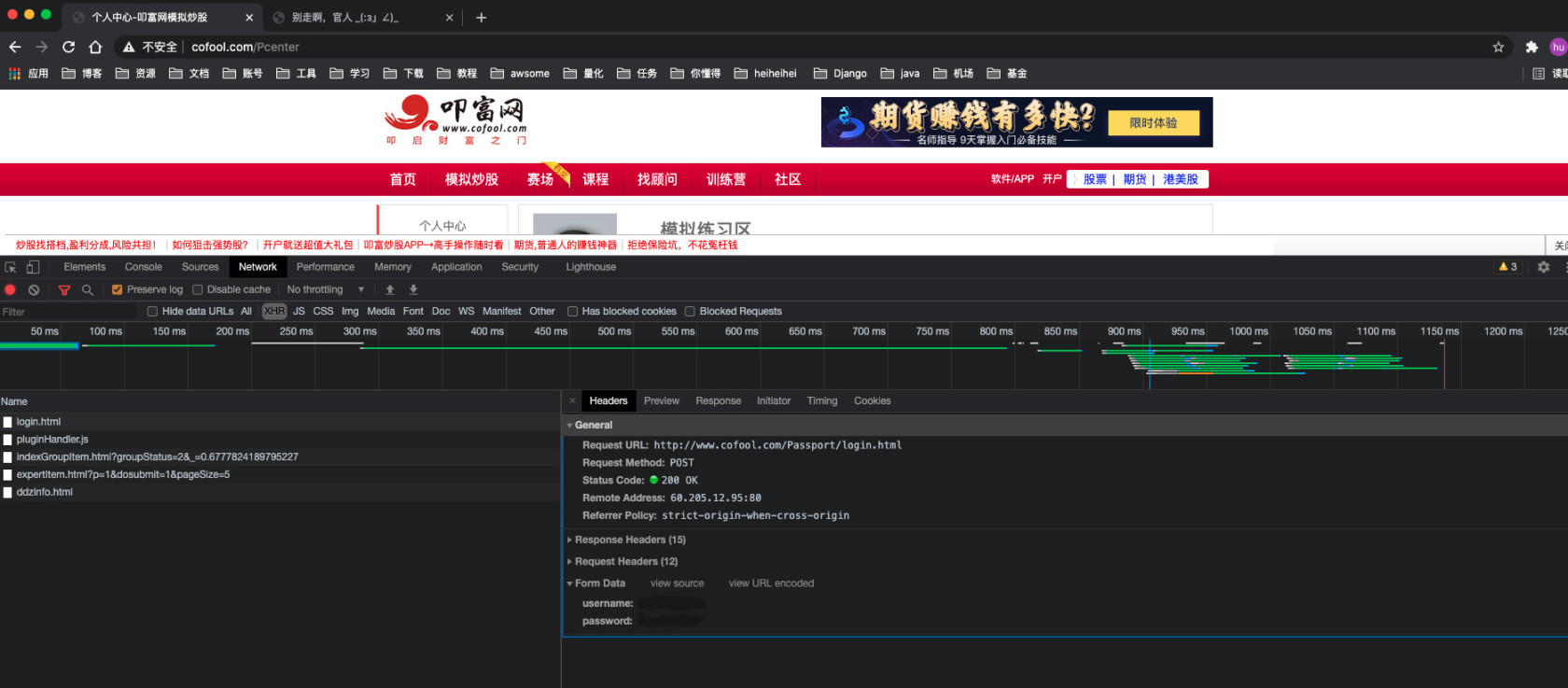
我们可以在里面看到请求URL、请求方式和Form Data所需要的内容,根据这个编写一个请求查看一下获取到的数据

由于是字符串格式,所以出现了我们看不懂的字符,通过json转成Python中的字典格式再查看
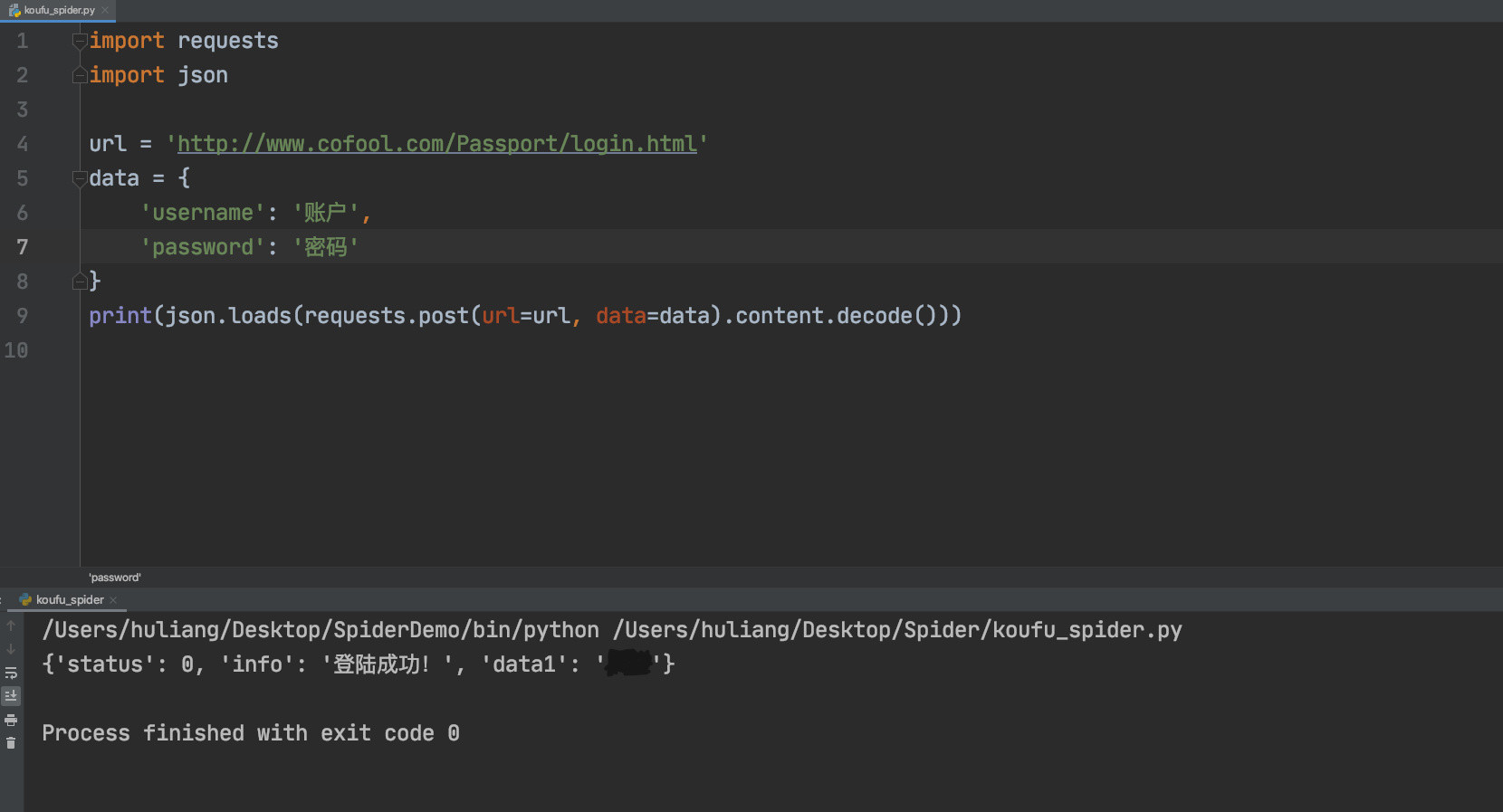
可以看到显示登陆成功了,接下来通过获取到的cookie就可以获取到我们需要的各种信息了

接下来我们将代码优化一下变成一个方法,让登陆后的cookie可以在以后任意需要的地方使用
import requestsimport json
from lxml import etree
deflogin(username, password):
"""
登陆叩富网
:param username: 用户名
:param password: 密码
:return: 登陆成功返回cookie,失败抛出对应异常
"""
login_url ='http://www.cofool.com/Passport/login.html'
data ={
'username': username,
'password': password
}
try:
response = requests.post(url=login_url, data=data)
except Exception as e:
raise Exception("登陆失败,原因为:{}".format(e))
content = json.loads(response.content.decode())
if content['status']==0:
cookie = response.cookies.get_dict()
return cookie
else:
raise Exception("登陆失败,原因为:{}".format(content['info']))
在出现登录失败的时候抛出异常,并显示错误信息
Feeling
爬虫是我们与开发者的博弈,我们需要站在他们的角度去分析他们开发的过程,从而更好的理解并去设计我们的相关爬虫程序。通常爬虫程序都不是一次就完成的,需要通过我们不断根据请求的反馈去修改程序,最终通过多层解析得到结果。
获取账户信息
练习区信息
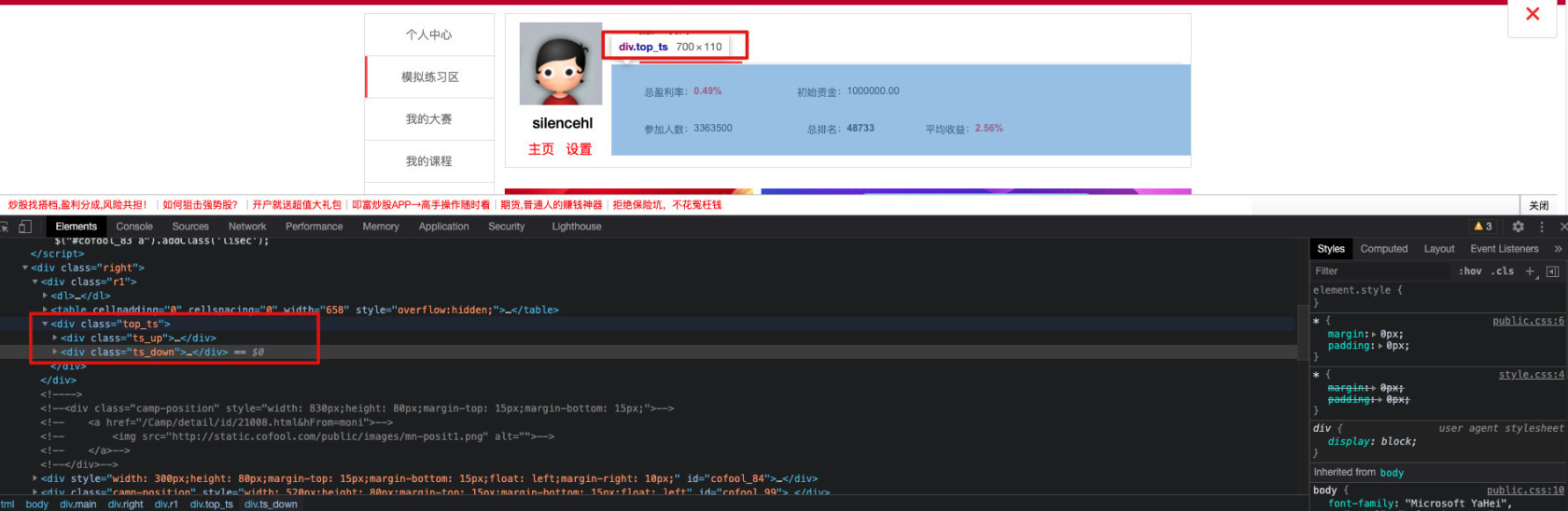
通过对相关请求的分析,练习区信息在http://www.cofool.com/Trade/Stock/index/gid/2.html这个URL下
对页面分析我们所需要的数据在class为top_ts的div下
XPath
XPath是一门在XML文档中查找信息的语言,可以帮助我们在爬虫中对获取数据进行查找得到我们需要的内容。
推荐从大佬崔庆才的个人博客学习XPath及爬虫的相关内容
开始通过XPath获取对应数据,考虑到多个数据在相同的font标签下,可以一次性获取所有标签然后进行处理
defget_account_info(query_category):"""
根据query_category获取账户相关信息
:param query_category: 查询类别信息,账户信息:ai 持仓状态:ap 当日委托:ac 当日成交:ad 历史成交:hd 股票收益明细:sd 日资产增长明细:da
月资产增长明细:ma 荣耀榜 ho
:return:
"""
cookie = login('用户名','密码')
if query_category notin['ai','ap','ac','ad','hd','sd','da','ma','ho']:
raise Exception('查询类别不存在')
if query_category =='ai':
url ='http://www.cofool.com/Trade/Stock/index/gid/2.html'
# 抓取账户相关数据
try:
response = requests.get(url=url, cookies=cookie).content.decode()
except Exception as e:
raise Exception("获取账户数据失败,原因为:{}".format(e))
if'总盈利率'notin response:
raise Exception("获取账户数据失败,未获取到正确信息")
# 使用xpath对抓取到的数据进行清洗得到我们需要的数据
html = etree.HTML(response)
account_info = html.xpath('//div [@class="top_ts"]/div//font/text()')
iflen(account_info)!=4:
raise Exception("获取账户数据失败,未获取足够的账户数据")
gross_profit_rate = account_info[0]# 总收益率
initial_funding = account_info[1]# 初始资金
number_of_participants = account_info[2]# 参赛人数
average_income = account_info[3]# 平均收益率
overall_ranking = html.xpath('//div [@class="top_ts"]/div//p[2]/b/text()')[0]# 总排名
try:
total_assets =float(''.join(re.search('\d,\d*,\d*.\d*', html.xpath(
'//*[@id="left2"]/table/tbody/tr[1]/td[@class="btom zjsr"]/text()')[0])[0].split(',')))
available_funds =float(''.join(re.search('\d,\d*,\d*.\d*', html.xpath(
'//*[@id="left2"]/table/tbody/tr[1]/td[@class="btom zjl"]/text()')[0])[0].split(',')))
except Exception as e:
raise Exception("获取账户数据失败,{}".format(e))
return{'总收益率': gross_profit_rate,'初始资金': initial_funding,'参赛人数': number_of_participants,
'平均收益率': average_income,'总排名': overall_ranking,'总资产': total_assets,'可用资金': available_funds}
持仓、交易、业绩信息
通过对相关请求的分析,当前持仓、当日委托、当日成交、历史成交与业绩报告都用同一个URL进行请求,只是请求中FormData部分数据不同,分析各页面数据发现当前持仓、当日委托、当日成交、历史成交数据类似,将其作为同一个类型进行爬取做简单修改即可。分页相关信息需要根据页码数据进行追加处理
...url ='http://www.cofool.com/Trade/Stock/tradeItem.html'
data ={'gid':'gid','uid':'uid','web_id': 'web_id}
# 根据查询条件设置对应的type值
if query_category =='ap':
data['type']='position'
elif query_category =='ac':
data['type']='entrust'
elif query_category =='ad':
data['type']='turnover'
elif query_category =='hd':
data['type']='history'
elif query_category =='sd':
data['type']='earnings'
elif query_category =='da':
data['type']='dayasset'
elif query_category =='ma':
data['type']='monthasset'
elif query_category =='ho':
data['type']='honor'
# 第一次获取对应信息,当信息不存在时返回'暂无交易的数据!'
try:
response = requests.post(url=url, data=data).content.decode()
except Exception as e:
raise Exception('获取账户数据失败,原因为:{}'.format(e))
if' 暂无交易的数据!'in response:
return'暂无交易的数据!'
html = etree.HTML(response)
# 当有信息时获取页码数值,
number_of_pages =len(html.xpath('//div [@class = "clearfix fr"]/a/text()'))+1
# 获取对应表头名
col_name = html.xpath('//tr/th/text()')
# 设置临时存储字典
temp_dict ={}
# 根据页码信息进行第二次访问获取信息
for i inrange(1, number_of_pages +1):
# 添加页码数据
data['p']= i
try:
response = requests.post(url=url, data=data).content.decode()
except Exception as e:
raise Exception('获取账户数据失败,原因为:{}'.format(e))
# 由于爬取的数据存在大量\n和空格,先进行一次简单的清洗
response = re.sub('\n\s|\s','', response)
html = etree.HTML(response)
# 分别获取各列信息
for j inrange(len(col_name)):
xpath_index = j +1
xpath_values = html.xpath('//tr/td[{}]//text()|//tr/td[{}]/font/text()|//tr/td[{}]/text()'.format(xpath_index, xpath_index,xpath_index))
if i ==1:
temp_dict[col_name[j]]= xpath_values
# 当出现第二页及其以上时,进行数据追加处理
else:
temp_dict[col_name[j]].extend(xpath_values)
return pd.DataFrame(temp_dict)
Feeling
爬虫中数据清洗的过程通常也非常熬人,网站开发者的水平高低与反爬的难度,会导致许多数据清洗起来非常复杂,可能会花费大量的时间还得不到你想要的结果,这时候我们需要保持一颗平常心,针对出现的问题一个一个去解决,只要坚持下去一定能解决的!
账户操作
股票信息
接下来编写账户操作方面的爬虫,要交易首先要拿到进行交易股票的相关信息,通过分析相关请求后发现其URL为http://www.cofool.com/Trade/Stock/stockQuote.html,这个比较简单很快就可以完成对应代码
defget_stock_info(stock_code):"""
根据股票代码获取相关价格
:param code:股票代码
:return: 相关价格
"""
url ="http://www.cofool.com/Trade/Stock/stockQuote.html"
data ={
"code": stock_code,
"uid":'uid',
}
cookie = login('账户名','密码')
try:
response = json.loads(requests.post(url=url, data=data, cookies=cookie).content.decode("utf-8-sig"))
except Exception as e:
raise Exception('获取账户数据失败,原因为:{}'.format(e))
stock_info = response["info"]
info_dict ={
"high_limit": stock_info["surgedLimit"],# 涨停价
"low_limit": stock_info["declineLimit"],# 跌停价
"stock_name": stock_info['stockName'],# 股票名称
'currentPrice': stock_info["currentPrice"],# 当前价
}
return info_dict
股票交易
通过观察发现买入与卖出操作的URL差距非常小,并且请求参数也高度相似,可以将其放在同一个方法中
deftradeing(stock_code, tradeing_type, amount=0):"""
股票交易,并返回交易状态
:param stock_code:股票代码
:param tradeing_type:交易类型
:param amount:交易数量,默认为0防止出现没有填写的情况
:return:交易状态
"""
cookie = login('账户名','密码')
# 获取股票相关信息
info_dict = get_stock_info(stock_code)
price = info_dict["high_limit"]
# 配置相关数据
data ={
"stockName": info_dict['stock_name'],
"code": stock_code,
"uid":'uid',
"gid":2,
"orderPrice": price,
"orderAmount": amount,
"declineLimit": info_dict['low_limit'],
"surgedLimit": info_dict['high_limit']
}
if tradeing_type =='buy':
url ="http://www.cofool.com/Trade/Stock/buy.html"
# 买入操作,检测买入数量防止超过最大买入数量
available_funds = get_account_info('ai')['可用资金']
if amount < available_funds /float(price):
data["orderAmount"]= amount
else:
raise Exception('购买数量超过最大可购买数量')
elif tradeing_type =='sell':
url ="http://www.cofool.com/Trade/Stock/sell.html"
# 卖出操作,从持仓信息中获取可卖出数量
data["orderAmount"]= get_amount(stock_code)
try:
content = \
requests.post(url=url, data=data, cookies=cookie).content.decode("utf-8-sig")
status = json.loads(content, encoding="unicode_escape")["status"]
except Exception as e:
raise Exception('获取账户数据失败,原因为:{}'.format(e))
if status ==1:
print("买入股票:{},股数:{}".format(stock_code, amount))
return0
else:
raise Exception("买入失败,失败原因为:{}".format(json.loads(content, encoding="unicode_escape")["info"]))
持仓数量
在卖出交易的时候需要获取账户中持仓的数量
defget_amount(code):"""根据股票代码获取可交易数量
:param code:股票代码
:return:对应股票可用数量
"""
url ="http://www.cofool.com/Trade/Stock/sellAmount"
data ={
"code": code,
"uid":'uid',
"web_id":'web_id'
}
cookie = login('账户名','密码')
try:
content = json.loads(requests.post(url=url, data=data, cookies=cookie).content.decode('unicode_escape'))
except Exception as e:
raise Exception("获取股数数据失败,{}".format(e))
status = content['status']
if status ==1:
amount = content['info']['frozen_amount']
return amount
else:
raise Exception(content['info'])
到这里叩富网的爬虫基本完成了,最后将转化为类就可以了,完整代码可以在我的GitHub仓库查看最新的代码
以上是 Python爬虫实战之叩富网 的全部内容, 来源链接: utcz.com/p/217227.html





