Python爬虫实战之bilibili
声明:以下内容均为我个人的理解,如果发现错误或者疑问可以联系我共同探讨
爬虫介绍
网站介绍
本次要爬取的网站为bilibili,它是国内知名的视频弹幕网站,这里有及时的动漫新番,活跃的ACG氛围,有创意的Up主。可以在这里找到许多欢乐。
编写爬虫的原因和用途
bilibili已经从原来的小破站变成了现在现象级的多元化的社区网站,本次爬取它的目的是以它作为一个典型,告诉大家遇到各类型验证码的一种思路。
其实这类网站有个最简单的办法,就是提前登陆手动获取到cookie,然后根据cookie去请求我们需要爬取的网站。个人目的的爬虫可以用这类方法,比较省编写代码的时间。但是公司中可能会遇到众多账户的爬虫需求,一个一个手动登录去获取cookie就比较麻烦了,这时候使用Selenium自动化去获取效率就高很多了。
Selenium
简介
正如他们官方的介绍Selenium automates browsers. That's it!,他是一个自动化的浏览器,可以模拟人的操作。
使用教程
推荐通过Selenium中文网学习,非常全面!
验证码分析
滑动验证码
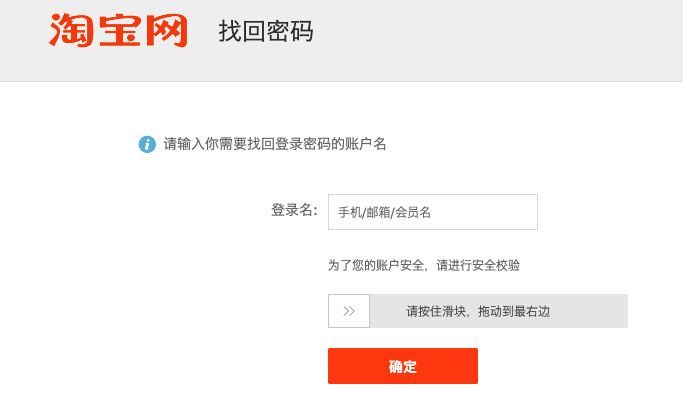
哔哩哔哩从之前的验证码是滑动验证码,主要思路就是找到缺口确定缺口的坐标,然后通过Selenium操作滑动到指定位置就行。类似的还有阿里系的大部分网页,比如飞猪、淘宝、天猫等,不过阿里系的不是每次都需要验证,得根据实际情况操作。
这种就是找到最右边的位置信息,然后滑动即可
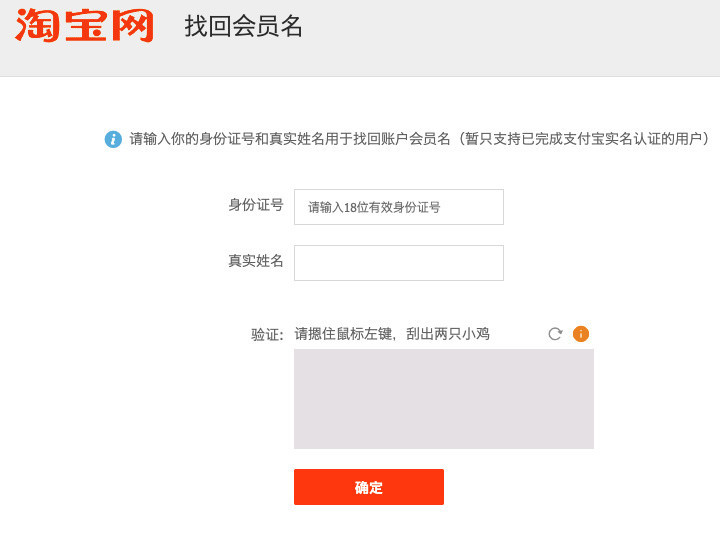
这种需要先找到整个图片的位置,然后滑动先找到内容的轮廓在进行滑动,都是同一个思路演变的
看图填答案系列
包括东方财富网上交易、bigquant等等,这类比较简单。将其下载下来根据验证码的情况进行处理然后交给各大云服务商的ORC服务识别就可以,都有免费试用的额度,根据自己的需求和喜好选择,也可以多试几家进行对比。
根据图片进行操作点击系列
目前多了很多这种验证码,这种的难度在于情况变化比较多,不仅限于汉字和数字,还有可能是图片等等,这时候自己想办法也能解决,但是策略一改变就比较麻烦,可以借助各类打码的平台,对内容进行识别,然后再根据内容去进行操作
bilibili登陆分析
bilibili的最新的验证码属于第三种,在点击登陆按钮就会出现一个验证码的框,我们需要将这个图片下载下来给打码平台去识别,获得坐标信息然后再用Selenium进行点击操作

bilibili验证码
编写代码
Selenium模拟登陆
import reimport time
import base64
import json
import requests
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.chrome.options import Options
classBilibili(object):
def__init__(self):
chrome_options = Options()
# 设置无窗口模式
# chrome_options.add_argument('--headless')
self.driver = webdriver.Chrome('./chromedriver', options=chrome_options)
deflogin(self, username, password):
# 开登陆页面
self.driver.get("https://passport.bilibili.com/login")
# 输入用户名和密码
self.driver.find_element_by_id('login-username').send_keys(username)
self.driver.find_element_by_id('login-passwd').send_keys(password)
# 点击登陆按钮
self.driver.find_element_by_class_name('btn-login').click()
# 等待验证码出现
# self.driver.implicitly_wait(10)
time.sleep(5)
# 获取图片所在属性
img_style = self.driver.find_element_by_class_name('geetest_tip_img').get_attribute('style')
# 通过正则表达式获得图片url
url = re.findall('url\("(.*?)"\)', img_style)[0]
# 通过requests发送请求得到图片
response = requests.get(url).content
# 将图片保存在本地
withopen('./captcha.png','wb')as f:
f.write(response)
# 通过打码平台进行打码识别
result = self.captcha_recognition()
# 识别成功
if result !="":
# 对识别到的坐标进行分组处理
result_list = result.split('|')
for result in result_list:
x = result.split(',')[0]
y = result.split(',')[1]
# 根据坐标执行整个动作链
ActionChains(self.driver).move_to_element_with_offset(img_style,int(x),int(y)).click().perform()
# 点击确定按钮
self.driver.find_element_by_class_name('geetest_commit').click()
# 获得登陆后的cookie
cookie =[item["name"]+"="+ item["value"]for item in self.driver.get_cookies()]
self.driver.close()
return cookie
defcaptcha_recognition(self):
"""验证码识别"""
username ='username'
password ='password'
withopen('./captcha.png','rb')as f:
base64_data = base64.b64encode(f.read())
b64 = base64_data.decode()
data ={"username": username,"password": password,"typeid":27,"image": b64}
result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text)
if result['success']:
return result["data"]["result"]
else:
print(result["message"])
return""
以上是 Python爬虫实战之bilibili 的全部内容, 来源链接: utcz.com/p/217229.html