机器学习之梯度下降法
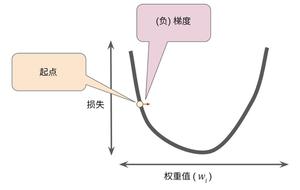
假设我们有时间和计算资源来计算 w1 的所有可能值的损失.对于我们一直研究的回归问题, 所产生的损失与 w1 的图形始终是凸形.换而言之,图形始终是碗状图,如下图所示:
回归问题产生的损失与权重图为凸形
凸形问题只有一个最低点;即只存在一个斜率正好为 0 的位置.这个最小值就是损失函数收敛之处.
通过计算整个数据集中 w1 每个可能值的损失函数来找到收敛点这种方法效率太低.我们来研究一种更好的机制,这种机制在机器学习领域非常热门, 称为梯度下降法.
梯度下降法的第一个阶段是为 w1 选择一个起始值(起点).起点并不重要;因此很多算法就直接将 w1 设为 0 或随机选一个值.下图显示的是我们选择了一个稍大于 0 的起点:
梯度下降法" title="梯度下降法">梯度下降法的起点" class="reference-link">梯度下降法的起点
然后, 梯度下降法算法会计算损失曲线在起点处的梯度.简而言之, 梯度是偏导数的矢量;它可以让您了解哪个方向距离目标“更近”或“更远”.请注意, 损失相对于单个权重的梯度就等于导数.
偏导数和梯度
请注意, 梯度是一个矢量, 因此具有以下两个特征:
方向
大小
梯度始终指向损失函数中增长最为迅猛的方向.梯度下降算法会沿着负梯度的方向走一步,以便尽快降低损失.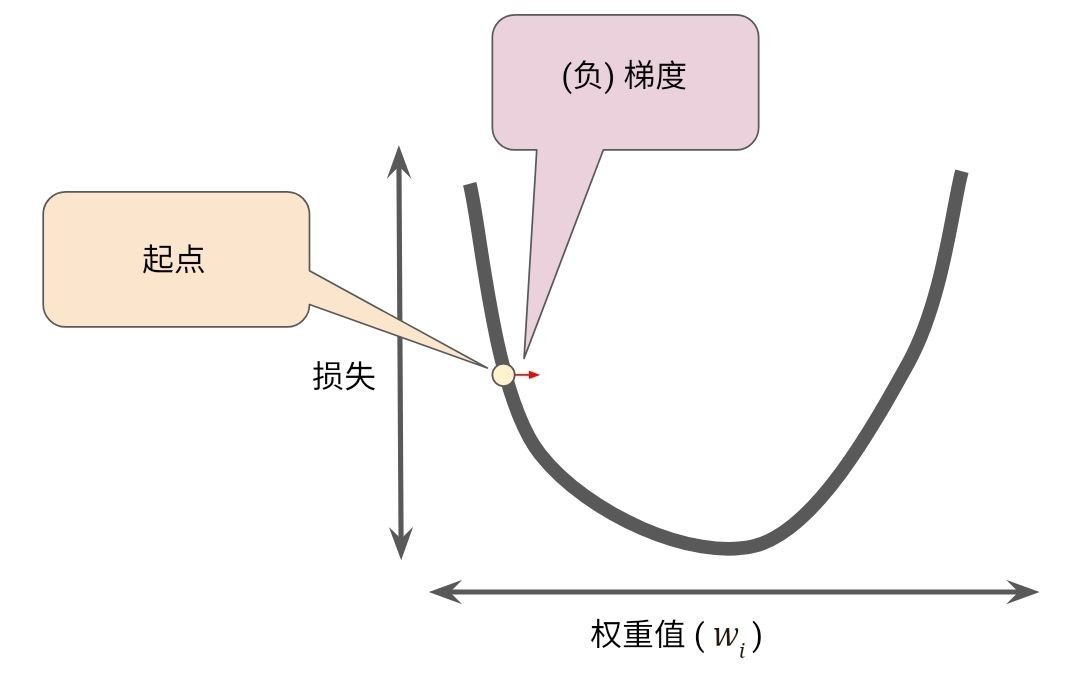
梯度下降法依赖于负梯度
为了确定损失函数曲线上的下一个点, 梯度下降算法会将梯度大小的一部分与起点相加, 如下图所示: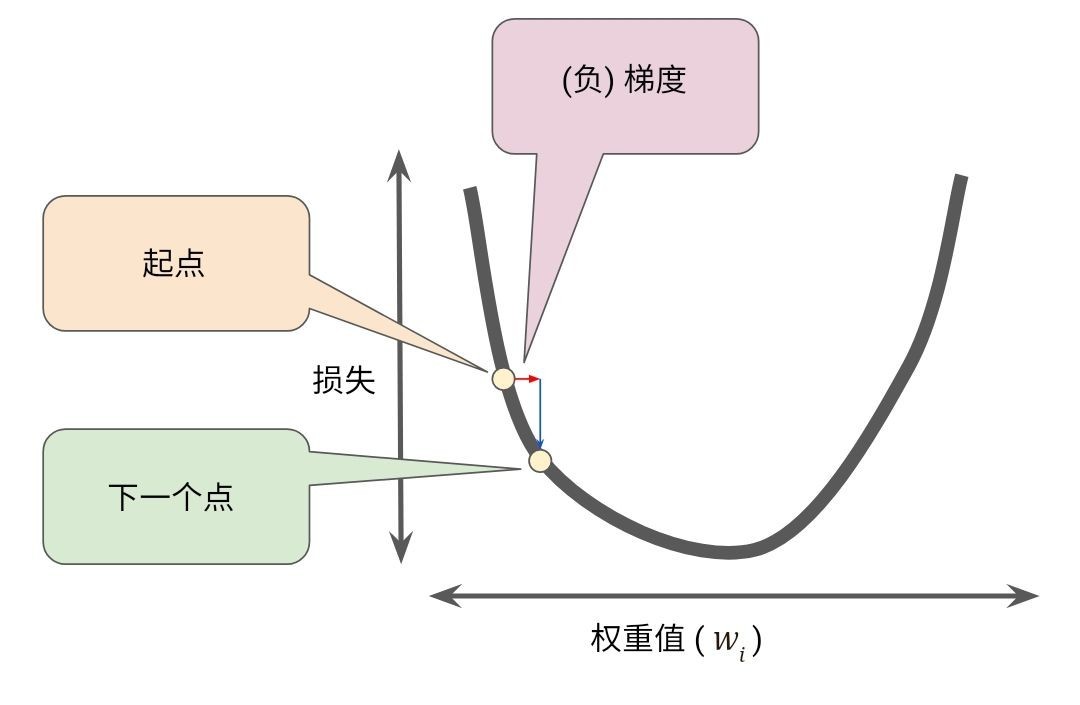
一个梯度步长将我们移动到损失曲线的下一个点
然后,梯度下降法会重复此过程,逐渐接近最低点
以上是 机器学习之梯度下降法 的全部内容, 来源链接: utcz.com/p/216958.html