Spark MLlib随机梯度下降法概述与实例
机器学习算法中回归算法有很多,例如神经网络回归算法、蚁群回归算法,支持向量机回归算法等,其中也包括本篇文章要讲述的梯度下降算法,本篇文章将主要讲解其基本原理以及基于Spark MLlib进行实例示范,不足之处请多多指教。
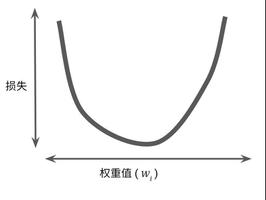
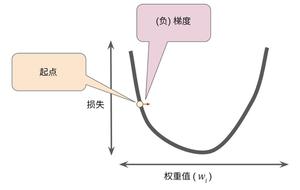
梯度下降算法包含多种不同的算法,有批量梯度算法,随机梯度算法,折中梯度算法等等。对于随机梯度下降算法而言,它通过不停的判断和选择当前目标下最优的路径,从而能够在最短路径下达到最优的结果。我们可以在一个人下山坡为例,想要更快的到达山低,最简单的办法就是在当前位置沿着最陡峭的方向下山,到另一个位置后接着上面的方式依旧寻找最陡峭的方向走,这样每走一步就停下来观察最下路线的方法就是随机梯度下降算法的本质。
随机梯度下降算法理论基础
在线性回归中,我们给出回归方程,如下所示:
我们知道,对于最小二乘法要想求得最优变量就要使得计算值与实际值的偏差的平方最小。而随机梯度下降算法对于系数需要通过不断的求偏导求解出当前位置下最优化的数据,那么梯度方向公式推导如下公式,公式中的θ会向着梯度下降最快的方向减少,从而推断出θ的最优解。
因此随机梯度下降法的公式归结为通过迭代计算特征值从而求出最合适的值。θ的求解公式如下。
α是下降系数,即步长,学习率,通俗的说就是计算每次下降的幅度的大小,系数越大每次计算的差值越大,系数越小则差值越小,但是迭代计算的时间也会相对延长。θ的初值可以随机赋值,比如下面的例子中初值赋值为0。
Spark MLlib随机梯度下降算法实例
下面使用Spark MLlib来迭代计算回归方程y=2x的θ最优解,代码如下:
package cn.just.shinelon.MLlib.Algorithm
import java.util
import scala.collection.immutable.HashMap
/**
* 随机梯度下降算法实战
* 随机梯度下降算法:最短路径下达到最优结果
* 数学表达公式如下:
* f(θ)=θ0x0+θ1x1+θ2x2+...+θnxn
* 对于系数要通过不停地求解出当前位置下最优化的数据,即不停对系数θ求偏导数
* 则θ求解的公式如下:
* θ=θ-α(f(θ)-yi)xi
* 公式中α是下降系数,即每次下降的幅度大小,系数越大则差值越小,系数越小则差值越小,但是计算时间也相对延长
*/
object SGD {
var data=HashMap[Int,Int]() //创建数据集
def getdata():HashMap[Int,Int]={
for(i <- 1 to 50){ //创建50个数据集
data += (i->(2*i)) //写入公式y=2x
}
data //返回数据集
}
var θ:Double=0 //第一步 假设θ为0
var α:Double=0.1 //设置步进系数
def sgd(x:Double,y:Double)={ //随机梯度下降迭代公式
θ=θ-α*((θ*x)-y) //迭代公式
}
def main(args: Array[String]): Unit = {
val dataSource=getdata() //获取数据集
dataSource.foreach(myMap=>{ //开始迭代
sgd(myMap._1,myMap._2) //输入数据
})
println("最终结果值θ为:"+θ)
}
}
需要注意的是随着步长系数增大以及数据量的增大,θ值偏差越来越大。同时这里也遗留下一个问题,当数据量大到一定程度,为什么θ值会为NaN,笔者心中有所疑惑,如果哪位大佬有想法可以留言探讨,谢谢!
以上是 Spark MLlib随机梯度下降法概述与实例 的全部内容, 来源链接: utcz.com/z/342226.html