Python 3中如何实现文本分析?详细指南
书籍/文件的内容分析
书面文本中的样式在所有作者或所有语言中都不相同, 这使语言学家可以研究原籍语言或可能没有直接了解这些特征的文本的潜在作者身份, 例如《Federalist Papers of the American》论文。
目标:在本案例研究中, 我们将检查来自不同作者和不同语言的书籍集中的各个书籍的属性, 更具体地说, 我们将研究书籍的长度, 唯一单词的数量以及这些属性如何根据语言或作者身份进行聚类。
资源: 古腾堡计划是最古老的数字图书图书馆, 旨在对文化作品进行数字化和存档, 目前包含50, 000本书, 这些书籍以前都已出版, 现在可以通过电子方式获得。这里以及葡萄牙和德国的书籍这里将所有这些书籍放在一个名为Books的文件夹中, 该文件夹的子文件夹为英语, 法语, 德语和Potugese。
文字中的词频
因此, 我们将构建一个函数来计算文本中的单词频率。我们将考虑一个示例测试文本, 然后将示例文本替换为我们刚刚下载的书籍的文本文件。计算词的频率, 因此大写和小写字母是相同的。我们将整个文本转换为小写并保存。
text = "This is my test text. We're keeping this text short to keep things manageable."text = text.lower()
单词频率可以通过多种方式进行计数, 我们将使用两种方式(仅出于知识目的)进行编码:一种使用for循环, 另一种使用Collection中的Counter, 事实证明它比前一种更快, 该函数将返回唯一单词字典及其频率作为键值对。因此, 我们编写以下代码:
from collections import Counterdef count_words(text): #counts word frequency
skips = [ "." , ", " , ":" , ";" , "'", '"']
for ch in skips:
text = text.replace(ch, "")
word_counts = {}
for word in text.split(" "):
if word in word_counts:
word_counts[word]+= 1
else:
word_counts[word]= 1
return word_counts
# >>>count_words(text) You can check the function
def count_words_fast(text): #counts word frequency using Counter from collections
text = text.lower()
skips = [".", ", ", ":", ";", "'" , '"']
for ch in skips:
text = text.replace(ch, "")
word_counts = Counter(text.split( " " ))
return word_counts
# >>>count_words_fast(text) You can check the function
输出:输出是一个字典, 其中将示例文本的唯一单词作为键并将每个单词的频率作为值, 比较两个函数的输出, 我们得到:
{‘是’:1, ‘是’:1, ‘可管理’:1, ‘到’:1, ‘事物’:1, ‘保持’:1, ‘我’:1, ‘测试’:1, ‘ text’:2, ‘keep’:1, ‘short’:1, ‘this’:2} Counter({‘text’:2, ‘this’:2, ‘were’:1, ‘is’:1, “可管理”:1, “到”:1, “事物”:1, “保存”:1, “我”:1, “测试”:1, “保留”:1, “简短”:1})
在Python中读取书籍:由于我们已经成功地用示例文本测试了词频函数, 现在我们将这些函数与书籍一起文本化, 并以文本文件的形式下载, 我们将创建一个名为read_book()的函数来读取使用Python将我们的书籍保存为一个长字符串并保存在变量中, 然后将其返回。该函数的参数将是要读取的book.txt的位置, 并将在调用该函数时传递。
def read_book(title_path): #read a book and return it as a string with open (title_path, "r" , encoding = "utf8" ) as current_file:
text = current_file.read()
text = text.replace( "\n" , " ").replace(" \r ", " ")
return text
唯一字总数:我们将设计另一个名为word_stats()的函数, 它将以词频字典(count_words_fast()/ count_words()的输出)作为参数, 该函数将返回唯一字的总数(总和/总键数)单词频率字典)和dict_values, 将它们的总数作为一个元组保存在一起。
def word_stats(word_counts): # word_counts = count_words_fast(text) num_unique = len (word_counts)
counts = word_counts.values()
return (num_unique, counts)
调用函数:因此, 最后我们要读一本书, 例如罗密欧与朱丽叶的英文版, 并从功能中收集有关单词频率, 唯一单词, 唯一单词总数的信息。
text = read_book( "./Books / English / shakespeare / Romeo and Juliet.txt" )word_counts = count_words_fast(text)
(num_unique, counts) = word_stats(word_counts)
print (num_unique, sum (counts))
Output: 5118 40776借助我们创建的功能, 我们发现罗密欧与朱丽叶的英语版本中有5118个唯一词, 并且这些唯一词的频率总和总计为40776。我们可以知道哪个词出现得最多可以通过上述功能与不同版本的书籍, 不同的语言一起玩, 以了解它们及其统计信息。
绘制书籍的特征
我们将绘制以下内容:(i)图书长度Vs使用matplotlib我们将导入熊猫以创建熊猫数据框, 该数据框将把书籍中的信息作为列保存。我们将这些列按不同的类别进行分类, 例如”语言”, “作者”, “标题”, “长度”和”唯一”要绘制沿x轴的书本长度和沿y轴的唯一字数, 请编写以下代码:
import osimport pandas as pd
book_dir = "./Books"
os.listdir(book_dir)
stats = pd.DataFrame(columns = ( "language" , "author" , "title" , "length" , "unique" ))
# check >>>stats
title_num = 1
for language in os.listdir(book_dir):
for author in os.listdir(book_dir + "/" + language):
for title in os.listdir(book_dir + "/" + language + "/" + author):
inputfile = book_dir + "/" + language + "/" + author + "/" + title
print (inputfile)
text = read_book(inputfile)
(num_unique, counts) = word_stats(count_words_fast(text))
stats.loc[title_num] = language, author.capitalize(), title.replace( ".txt" , ""), sum (counts), num_unique
title_num + = 1
import matplotlib.pyplot as plt
plt.plot(stats.length, stats.unique, "bo-" )
plt.loglog(stats.length, stats.unique, "ro" )
stats[stats.language = = "English" ] #to check information on english books
plt.figure(figsize = ( 10 , 10 ))
subset = stats[stats.language = = "English" ]
plt.loglog(subset.length, subset.unique, "o" , label = "English" , color = "crimson" )
subset = stats[stats.language = = "French" ]
plt.loglog(subset.length, subset.unique, "o" , label = "French" , color = "forestgreen" )
subset = stats[stats.language = = "German" ]
plt.loglog(subset.length, subset.unique, "o" , label = "German" , color = "orange" )
subset = stats[stats.language = = "Portuguese" ]
plt.loglog(subset.length, subset.unique, "o" , label = "Portuguese" , color = "blueviolet" )
plt.legend()
plt.xlabel( "Book Length" )
plt.ylabel( "Number of Unique words" )
plt.savefig( "fig.pdf" )
plt.show()
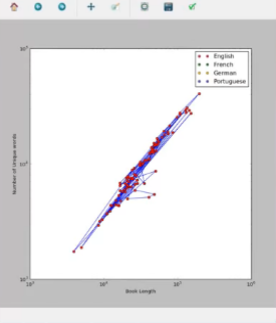
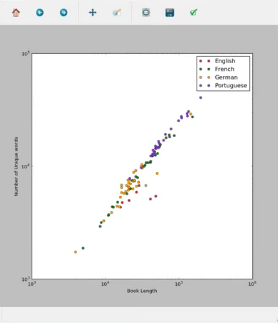
输出如下:
我们绘制了两个图形, 第一个图形表示每一种语言和作者都不同的书, 只是一本书。
第一张图
代表一本书, 它们由蓝线连接。对数图创建离散点(此处为红色), 线性图创建线性曲线(此处为蓝色), 将这些点连接起来。
第二张图
是一个对数图, 其中显示了不同语言的书本, 这些书本具有不同的颜色(英语为红色, 法语为绿色等)作为离散点。
这些图表有助于从视觉上分析有关生动来源的不同书籍的事实, 从该图表我们知道葡萄牙语书籍的长度更长, 并且具有比德语或英语书籍更多的独特单词数量。帮助语言学家。
参考:
- edX – HarvardX –使用Python进行研究
- next_step:ML-高级
如果发现任何不正确的地方, 或者想分享有关上述主题的更多信息, 请写评论。
首先, 你的面试准备可通过以下方式增强你的数据结构概念:Python DS课程。
以上是 Python 3中如何实现文本分析?详细指南 的全部内容, 来源链接: utcz.com/p/204216.html