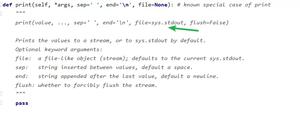
【Python】固定格式转换为表格
日志服务器收集防火墙的数据用于分析,从DB文件导出部分数据到csv,如下
"a=a1 b=b2 c=c3 devid=0 date=""2020/02/22 07:52:28"" dname=venus""a=a4 b=b5 c=c6 devid=0 date=""2020/02/26 07:52:27"" dname=venus"
"b=b8 c=c9 d=d10 devid=0 date=""2020/02/27 07:52:27"" dname=venus"
"b=b12 c=c9 d=d11 devid=0 date=""2020/02/27 07:52:27"" dname=venus"
目标是把日志转换为
请教大家有什么好的办法?
思路一:
csv文件进行处理,通过正则表达式处理。但是只符合格式相对统一的文本?因为1、2行与3、4行的格式不一致的。
思路二:
把字符串进行切片,转换为字典,再导入。
注意:date时间里面有个空格,切片时候会把时间也切开,导致时间不完整。
"a=a1 b=b2 c=c3 devid=0 date=""2020/02/22 07:52:28"" dname=venus" 附自己找到认为有用的资料
http://www.imooc.com/wenda/de...
https://www.jianshu.com/p/237...
回答
data.txt内容
a=a1 b=b2 c=c3 devid=0 date=""2020/02/22 07:52:28"" dname=venusa=a4 b=b5 c=c6 devid=0 date=""2020/02/26 07:52:27"" dname=venus
b=b8 c=c9 d=d10 devid=0 date=""2020/02/27 07:52:27"" dname=venus
b=b12 c=c9 d=d11 devid=0 date=""2020/02/27 07:52:27"" dname=venus
实现代码:
# 读取本地文件with open('./data.txt') as f:
# 按照行进行读取
line_list = f.read().splitlines()
# 结果集合[{row1 dict},{row2 dict},....]
res_list = []
# 判断日期是否需要续上,默认为False
continue_flag = False
for line in line_list:
# 按照空格进行分割,对应的k=v对
data_list = line.split(" ")
# 每一行生成一个row dict
dic = {}
# 遍历每一行,如果没有date关键词,则直接取k,v
for data in data_list:
if "date" in data:
continue_flag = True
res = data
# 如果是碰到date把下一词的v接上来,保证时间完整性
else:
if not continue_flag:
res = data
else:
res = res + " "+ data
# v已经接上了后面的分钟,故continue_flag重置为False
continue_flag = False
key,value = res.split("=")
dic.update({key:value})
res_list.append(dic)
# 生成data_frame
import pandas as pd
df = pd.DataFrame(res_list)
print(df)
产生结果:
a b c d date devid dname0 a1 b2 c3 NaN ""2020/02/22 07:52:28"" 0 venus
1 a4 b5 c6 NaN ""2020/02/26 07:52:27"" 0 venus
2 NaN b8 c9 d10 ""2020/02/27 07:52:27"" 0 venus
3 NaN b12 c9 d11 ""2020/02/27 07:52:27"" 0 venus
以上是 【Python】固定格式转换为表格 的全部内容, 来源链接: utcz.com/a/79839.html