Python--I/O格式化与运算符
一、输出函数
1.1 Python3-print()
在Python3中。print()的使用方法如下:
# Pycharm中演示# ====print() end参数 ====print('hello',end='<----')print('world')# ==== 执行结果 ====# hello<----worldprint后面必须跟上括号,所打印的内容必须由单引号、双引号、三单引号、三双引号、以上其中任意一种括起来才能使用。这是Python语法规定的死规范。
除此之外print()还可以接收3个参数分别是 sep 和 end以及file:
print()参数详解 sep 用来显示间隔中的链接字符,默认为一个空格end 指定当print()结束后的下一个print()的位置相较于上一次print()。默认换行 \nfile 指定print()的内容写入到某个指定的文件句柄中。默认为空** sep示例:**
>>> # ====print() sep参数 ====>>>>>>print("hello","world") # 不指定sep参数hello world>>>print("hello","world",sep="-------") #指定sep参数hello-------world** end示例:**
# Pycharm中演示# ====print() end参数 ====print('hello',end='<----')print('world')hello<----world** file示例:**
# Pycharm 中演示# ====print() file参数 ====withopen(file='a.text',mode='w',encoding='utf-8')as f:print('这一行将被写入文件中去...',file=f)print()的底层实现原理(自我猜测版本):
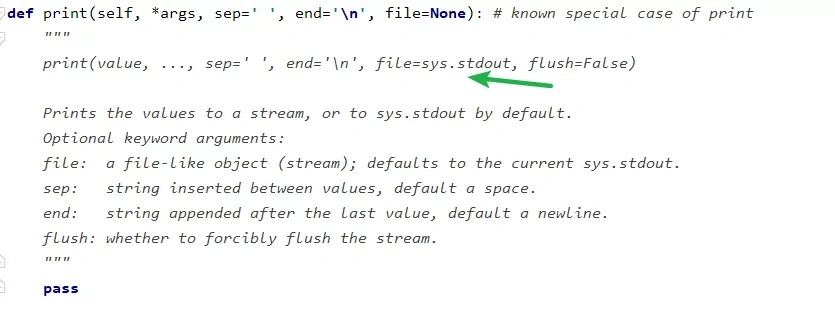
在这可以看到sys.stdout的字样。所以这里猜想是调用了sys.stdout.write()方法,如果我们将file指定为某一个文件,那么屏幕上便不会再显示print()打印的字样而是直接将内容写入到了文件中。
而flush是刷新的意思,以下代码可以在原生Python解释器中打开执行一下。分别删除flush = True 执行2次你就能看到效果了。
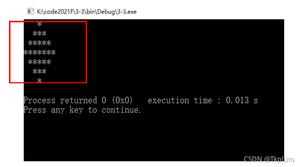
# ====print() flush参数 ====import timetime.sleep(0.1)print('下载中',end="")for i inrange(100):print('#',flush=True,end="") # 一种直接全部打印 100 个 #。加了flush = True偶则是慢慢打印。会有一种视觉上的效果1.2 Python2-print()
Python2的print()允许像Python3那样使用,但更多人使用Python2的print()是不带括号的。关于使用方式有这点差别,更深层的东西这里没有去研究了。
>>> # ==== Python2 print()====>>>>>>print("hello,world") # 允许 Python3中的使用方式hello,world>>> print "hello,world" # 允许 不加入括号,这在Python3中是不被允许的hello,world二、输入函数
2.1 Python3-input()
Python3中提供了input()方法来接收用户输入的值。但是Python3中的input()方法会将一切用户输入的值转换为str类型。这里一定要注意!
# ==== Python3 -input()====name =input("请输入您的姓名:")age =input("请输入您的年龄:")print("name的类型是:",type(name))print("age的类型是",type(age)) # <class'str'># ==== 执行结果 ===="""请输入您的姓名:yunya请输入您的年龄:18name的类型是: <class 'str'>age的类型是 <class 'str'>"""如果我们想求一个整形或者浮点型的数据,我们就将其使用int()或者float()包裹住输入的数据即可:
int()
- 只能包裹字符串str类型以及浮点型float(向下取整)
float()
- 只能包裹字符串str类型以及整形
# ==== Python3 input() 类型转换 ====name =input("请输入您的姓名:")age =int(input("请输入您的年龄:")) #注意用int()包裹input()返回的str类型的内容。并且做一次转换:确保用户输入的是 整形样式的字符串,否则会抛出异常print("name的类型是:",type(name))print("age的类型是",type(age)) # <class'int'># ==== 执行结果 ===="""请输入您的姓名:yunya请输入您的年龄:18name的类型是: <class 'str'>age的类型是 <class 'int'>"""这里提一嘴:如果用户输入的不是整形样式的字符串,则会抛出异常。那么如何处理先不着急,只需要记得肯定有处理的方法。
2.2 Python2-raw_input()
Python2中的 raw_input() 和上面介绍的 Python3 中的input()使用方法和功能全部都是一样的。这里不做详解,需要注意的是:Python3中没有raw_input()方法。
>>> # ====Python2中的raw_input()====>>>>>> name =raw_input("请输入姓名:")请输入姓名:yunya>>> age =raw_input("请输入年龄:")请输入年龄:18>>>type(name)<type 'str'>>>>type(age)<type 'str'>2.3 Python2-input()
Python2中的input()与Python3中的input()大不相同。Python3中的input()无论用户输入的值是什么都会转换为str类型,而Python2中的input()是用户输入什么类型的值就自动转换成什么类型,看起来挺好的。但是实际是非常不方便的,具体原因看下图:
>>> # ====Python2中的input()====>>>>>> name =input("请输入姓名:")请输入姓名:yunya # 注意:这里没加引号,Python2的input()会认为这是一个变量。而改变了未绑定堆区变量值,所以抛出 yunya 未定义的这么一个异常。Traceback(most recent call last): File "<stdin>", line 1,in<module> File "<string>", line 1,in<module>NameError: name 'yunya' is not defined>>> name =input("请输入姓名:")请输入姓名:"yunya">>> name'yunya' #用户必须按照Python语法规范来输入,极大的拉低了用户体验>>>>>> city =input("请输入城市:") #假如用户输入了不符合Python语法数据便直接抛出异常。请输入城市:["哈尔滨",Traceback(most recent call last): File "<stdin>", line 1,in<module> File "<string>", line 1["哈尔滨", ^SyntaxError: invalid syntax>>>三、字符串格式化
3.1 %
格式化的意思是我们有的时候想让变量值与定义好的字符串做一个融合。这个时候就有三种方法,我们先来看第一种也是最原始的一种 % 方法:
# ====%格式化 ====name ="yunya"age =18# ==== 位置传参 ====# 一个 % 对应一个 变量名。当变量名有多个时便需要%后面跟上括号做解包,如若只有一个则不需要加上括号,% 和后面的 %(a,b,c)位置一一对应msg ="姓名是:%s,年龄是%i"%(name,age) # %意味占位符,后面的字符代表转换的类型。如 %s代表接收任意类型的传值,%i代表只接受int类型的传值。print(msg)# ==== 关键字传参 ====msg2 ="姓名是:%(name)s,年龄是%(age)i"%{'age':age,'name':name} # 变量名存储变量值内存地址引用。关键字传参打破位置顺序必须统一的限制.print(msg2)# ==== 格式化 % 百分号 ====print('%s%%'%3) # %% 百分号代表一个 % 。放在 %s 后面则代表格式化出后的结果是 3%# ==== 执行结果 ===="""姓名是:yunya,年龄是18姓名是:yunya,年龄是183%"""占位符说明:
%s 字符串(采用str()的显示) Ps:推荐使用 %s 。 因为它接收所有类型的传值%r 字符串(采用repr()显示) Ps:原始字符串%c 单个字符%b 二进制整数%d 十进制整数%i 十进制整数%o 八进制整数%x 十六进制整数%e 指数(基底写为e)%E指数(基底写为E)%f 浮点数%F 浮点数,与上相同%g 指数(e)或浮点数(根据显示长度)%G指数(E)或浮点数(根据显示长度)3.2 format()
%虽然能够满足基本需求。但是其位置传参还是显得太过麻烦,故在Python2.6中新增format() 方法,它更加强大以及速度更快。推荐今后使用format()的方法进行字符串格式化 ,注意:format()中的s只接受str类型的传值而不接受全部类型!!!
# ====format()格式化 ====name ="yunya"age =18# ==== 位置传参 ====msg ="姓名是{:s},年龄是{:d}".format(name, age) # 采用{}进行占位,需要注意的是format中的 s 不是接收全部类型的参数,而是指定str# msg ="姓名是{},年龄是{}".format(name,age)也可不指定类型。默认接收全部类型参数print(msg)# ==== 索引传参 ====msg2 ="姓名是{1:d},年龄是{0:s}".format(name, age) # 采用{}进行占位 。 无法使用s接收age.且 format()中没有 i# msg2 ="姓名是{1},年龄是{0}".format(name,ageprint(msg2)msg3 ="姓名是{0:s}{0:s}{0:s},年龄是{1:d}{1:d}{1:d}".format(name, age) # 采用{}进行占位 。 无法使用s接收age# msg3 ="姓名是{0:s}{0:s}{0:s},年龄是{1:d}{1:d}{1:d}".format(name, age) #print(msg3)# ==== 关键字传参 ====msg4 ="姓名是{name:s},年龄是{age:d}".format(name=name, age=age) # 采用{}进行占位 。 无法使用s接收age# msg4 ="姓名是{name},年龄是{age}".format(name=name,age=age)print(msg4)# ==== 字符填充 ====print('{0:*<10}'.format('|||')) # < 代表字符 ||| 在左边,填充符号为 * 排在右边 一共10 个( 算上字符三个 |)print('{0:%>10}'.format('|||')) # > 代表字符 ||| 在右边,填充符号为 % 排在左边 一共10个( 算上字符三个 |)print('{0:$^10}'.format('|||')) # ^ 代表字符 ||| 在中间,填充符号为 $ 排在两侧 两侧加起来共10个 ( 算上字符三个 |)print('{0:$=10}'.format(123)) # = 代表数字 123 在右边,填充符号为 $ 排在左边 一共10个 Ps: = 只针对数字 ( 算上字符123 )# ==== 精度控制与格式转换 ====print('{0:.2f}'.format(3.1415926535)) # f代表接收值类型为float类型,.2代表小数点后保留2位print('{0:b}'.format(10)) # 转换为二进制 bprint('{0:x}'.format(10)) # 转换为十六进制 xprint('{0:o}'.format(10)) # 转换为八进制 oprint('{0:,}'.format(1000000)) # 千分位表示 ,print('{0:.2%}'.format(1)) #百分号表示 2代表2位数,转换数据1 为 百分之百print('{0:.2%}'.format(0.3)) #百分号表示print('{{{0}}}'.format('笑脸')) # 显示大括号。 外部套2层大括号# ==== 执行结果 ===="""姓名是yunya,年龄是18姓名是18,年龄是yunya姓名是yunyayunyayunya,年龄是181818姓名是yunya,年龄是18|||*******%%%%%%%|||$$$|||$$$$$$$$$$$1233.141010a121,000,000100.00%30.00%{笑脸}"""3.3 Python3-f
尽管format()已经非常方便了。但是如果传入的参数值太多依旧会看着十分混乱,于是Python3.6中新增了 f 格式字符串的操作。这种方法的速度最快,但是却不推荐使用,因为程序还要考虑一个向下兼容性的问题。
# ==== f 格式化 ====name ="yunya"age =18msg = f'我的名字叫做{name},我的年龄是{age}岁。' # f 开头。 {}为占位符用于存放变量名。print(msg)# 其他的关于高级操作如填充字符,精度控制与格式转换等等均与format()操作方式一样。# ==== 执行结果 ===="""我的名字叫做yunya,我的年龄是18岁。"""四、算术运算符
4.1 +- * /
详细举例每种数据类型支持的运算符:
- 加法运算:
int:int float(生成float) bool
float:float int bool
bool:bool int float (均生成int或float)
list:list(改变元素内index的引用值,而不改变list对应栈区变量名的引用值)
str:str(由于是不可变类型,生成新的str)
tuple:tuple (由于是不可变类型,生成新的tuple)
# ====+ 加法运算 ====# 以下代码均在Pycharm中测试通过print(1+1)print(1+1.1)print(1+ True)print([1,2,3]+[4,5,6])print('OldStr '+' NewStr') # 改变引用值,生成新对象print((1,2,3)+(4,5,6)) # 改变引用值,生成新对象# ==== 执行结果 ===="""22.12OldStrNewStr[1, 2, 3, 4, 5, 6](1, 2, 3, 4, 5, 6)"""
- 减法运算:
int:int float(生成float)bool
float:float int bool
bool:bool int float (均生成int或float)
# ====- 加法运算 ====# 以下代码均在Pycharm中测试通过print(1-1)print(1-1.1)print(1- True)# ==== 执行结果 ===="""0-0.100000000000000090"""
- 乘法运算:
int:int float(生成float)bool list(生成list不改变原本引用值) str(新生成str改变原本引用值)tuple(新生成tuple改变原本引用值)
float:float int bool
bool: bool int float
list: int (生成list不改变原本引用值)
str: int (新生成str改变原本引用值)
tuple: int (新生成str改变原本引用值)
# ====* 乘法运算 ====# 以下代码均在Pycharm中测试通过s1 ='#'l1 =[1,2,3]t1 =(1,2,3)print(1*2)print(1*2.0)print(1* True)print(3* l1)print(3* s1) #改变引用值,生成新的str对象print(3* t1) #改变引用值,生成新的tuple对象# ==== 执行结果 ===="""22.01[1, 2, 3, 1, 2, 3, 1, 2, 3]###(1, 2, 3, 1, 2, 3, 1, 2, 3)"""/ 精确除法运算 Ps: 一律生成float:
int: int float bool 注意:0 不能做 除数
float: float int bool 注意:0.0 不能做除数
bool: bool int float 注意:False不能做 除数
# # ====/ 精确除法运算 ====# 以下代码均在Pycharm中测试通过print(10/2)print(10/2.0)print(10.1/ True)print(10.1/ True)print(10.1/ True)print(10.1/ True)print(False /10)print(True /2)print(True /2.0)# ==== 执行结果 ===="""5.05.010.110.110.110.10.00.50.5"""4.2 // ** %
// 整数除法运算(向下取整) 与精确除法的可用数据类型相同 ,除开 2 个float类型 做运算为float 其他运算结果全是int。
** 幂运算(次方运算) 只支持 int float bool 三种类型。
% 求余 只支持 int float bool 三种类型。如果被求余数小于求余数,那么余数就为被求余数本身。
重点 方法介绍:divmod() 相当于整除法与求余法的糅合
>>> # ====divmod()示例 ====>>>>>>divmod(10,3) # 商3余1(3,1)>>>1%10 #被求余数小于求余数。结果为其本身1五、赋值运算符与赋值的方式
5.1 增量赋值
赋值符号本身就是一个 = 号。左边是变量名,右边是变量值这个没什么好说的了。增量赋值就是将赋值符号和算术运算符结合起来达到简写的目的:
# ==== 增量运算符与普通算术运算符对应关系及使用方式 ==== # 以下代码均在Pycharm中测试通过x =1x = x +10 # x +=1x = x -10 # x -=1x = x *10 # x *=1x = x /10 # x /=1x = x // 10 # x //= 1x = x ** 10 # x **= 1x = x % 10 # x %= 15.2 链式赋值
链式赋值也被称为间接赋值:
>>> # ==== 链式赋值使用方式 ====>>>>>> x = y = z =100 # 经常使用的一种链式赋值方式>>> x100>>> y100>>> z100>>> i =100 # 链式赋值也被称为间接赋值>>> j = i>>> i100>>> j1005.3 交叉赋值
交叉赋值是Python独有的一种语法:
>>> # ==== 交叉赋值使用方式 ====>>>>>> x =100>>> y =1000>>> x,y = y,x #互换2个变量名绑定的内存地址,即变量值的引用>>> y100>>> x10005.4 解压赋值
解压赋值一般只是用来拿到列表或者元组中开头或结尾的一些数据:
>>> # ==== 解压赋值使用方式 ====>>>>>> l1 =[1,2,3,4]>>> w,x,y,z = l1>>> w1>>> x2>>> y3>>> z4>>> a,b,*_ = l1 #取出前面2个值。字符 * 代表取所有以列表形式返回,变量名为单下划线 _ 表示废弃值不会使用。 >>> a1>>> b2>>>>>>*_,c,d = l1 #取出后面2个值>>> c3>>> d4为什么解压赋值不能拿中间的值呢?因为解压赋值依赖于字符 * 。假设列表长度为10,我要取第5个和第6个,那么前面就必须要有4个变量存储列表中解压出来的前4个值。这么做很麻烦所以一般不会用解压赋值取中间的值。
不光可以对列表进行解压赋值,字典也同样可以。但是字典的解压赋值只会取出key。
>>> # ==== 对字典的解压赋值 ====>>>>>> dic ={"k1":"v1","k2":"v2","k3":"v3"}>>> a,b,c = dic #只取key>>> dic{'k1':'v1','k2':'v2','k3':'v3'}六、比较运算符
6.1 > < == != >= <=
比较运算符一般是用于比较相同数据类型的2个值。返回一个bool类型的值(True或者False),常用于条件分支结构中。
> 大于 < 小于 == 等于 (注意 = 是赋值符号,不可用于比较运算) != 不等于 >= 大于或者等于 <= 小于或者等于>>> # ==== 比较运算符的使用 ====>>>>>>1<2True>>>1>2False>>>1==1.0True>>>1== TrueTrue6.2 关于字符串之间的比较
请解释以下现象:
>>>"1235"<"456" #字符串比较也是按照索引来比,一位一位去比True>>>("100",)>("45","b") #元组之间,或者列表之间的比较都是对同一索引下的值做比较。如果值是字符串则继续分成一位一位比,如果是int或者float则直接进行比较。False
由于是字符串,所以按照index继续一位一位比较。

由于是数字,所以比整体。
其实上面的比较只是初步的比较。详细一点就来讨论单个字符与单个字符之间的比较是怎么进行的,首先。如果两个都是字符串,则对比索引按位比较没问题。比如:”y” 单个字符对比 “k”,那么又是依照什么对比呢?其实这里涉及到一个ASCII码的概念。它们的这个字符就是通过ASCII码来对比。
>>>ord("y") # 字符转ASCII的函数ord() , ASCII转字符则是 chr()121>>>ord("k")107>>>"y">"k"True七、逻辑运算符
7.1 not and or
逻辑运算符的作用在于做一系列逻辑判断,常用于分支结构与流程控制中,所以这里也是先引出概念,其中not代表非,and代表与,or代表否则。
>>> # === 逻辑运算符的使用 ====>>>>>> not True # not 我不管你是什么,在我这里只取反False>>> not FalseTrue>>> True and True # and 一真一假取一假,全部为真才取真True>>> True and FalseFalse>>> False and FalseFalse>>> True or True # or 一真一假取一真,全部为假才取假True>>> True or FalseTrue>>> False or FalseFalse打油诗一首
作者:云崖
not 我不管你是什么,在我这里只取反。
and 一真一假取一假,全部为真才取真。
or 一真一假取一真,全部为假才取假。
我们看一个很有趣的比喻:
# === not and or 优先级 ==='''二狗子要找女朋友, 年龄不能大于25岁,这个是前提!!, 身高不能超过170或者体重不能超过60公斤。请问下面那个符合二狗子的需求?'''xiaoli ={'age':30,'height':158,'weight':90}xiaohua ={'age':38,'height':190,'weight':50}xiaocui ={'age':22,'height':164,'weight':58}# 人能一眼就看出来。计算机还要做一系列的判断呢print(xiaoli['age']<25 and xiaoli['height']<170 or xiaoli['weight']<60) # Falseprint(xiaohua['age']<25 and xiaohua['height']<170 or xiaohua['weight']<60) # True 小花按理说是不符合二狗子要求的,为什么通过了呢?print(xiaocui['age']<25 and xiaocui['height']<170 or xiaocui['weight']<60) # True原来是优先级搞的鬼,我们先不管优先级是什么。使用括号()可以提升优先级,这和小学数学的四则运算是相同的道理
# ==== 使用括号修改原本 not and or 的优先级 ====print(xiaoli['age']<25and(xiaoli['height']<170 or xiaoli['weight']<60)) # Falseprint(xiaohua['age']<25and(xiaohua['height']<170 or xiaohua['weight']<60)) # False 这样就好了,二狗子没有被骗 ...注意加了括号改变了优先级print(xiaocui['age']<25and(xiaocui['height']<170 or xiaocui['weight']<60)) # True 7.2 区分优先级
好了,通过上面的例子我们知道了有优先级这个概念。那么什么是优先级呢?
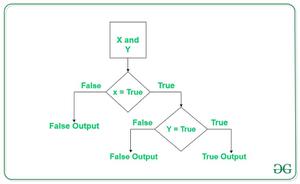
优先级就是对于在 有 2 种或者以上的逻辑运算符时决定符号右侧数值的归属权的问题。如下图:

关于优先级就先到这里了。其他的还有一个偷懒机制名叫短路运算,待会介绍。
八、其他运算符
8.1 成员运算符
in 判断一个元素是否在不在另一个集合之中(str,list,tuple,dict,set),也是用于分支结构之中,这里依旧是引出概念:
>>> # ====in 与 not 的结合使用 ====>>>>>> str1 ="abcdefg">>> list1 =["a","b","c"]>>> tuple1 =("a","b","c")>>> dict1 ={"a":1,"b":2,"c":3}>>> set1 ={"a","b","c","d"}>>>"a"in str1True>>>"a" not in str1False>>>"a"in list1True>>>"a" not in list1False>>>"a"in tuple1True>>>"a" not in tuple1False>>>"a"in dict1 #只会检索字典的key,不会去检索valueTrue>>>"a" not in dict1False>>>"a"in set1True>>>"a" not in set1False8.2 身份运算符
is 判断对象引用值是否相等,并非形式值。(引用值相同代表2个值数据存储在同一堆区内存),故引用值相等的情况下形式值一定相等,形式值相等的情况下引用值不一定相等。具体可看Python变量与基本数据类型一章。
>>> # ==== is的使用 ====>>>>>> x=y=z=10000>>> x is yTrue>>> x is zTrue>>> y is xTrue>>> y is zTrue九、逻辑运算符之短路运算
关于逻辑运算符还有一个短路运算没有说完。
如果一次逻辑运算中的逻辑运算符号全部为 and 或者 or 则会从左至右依次进行逻辑运算。如果每一次都进行运算是很消耗时间的,所以这个时候出现了短路机制。看图说话:

以上是 Python--I/O格式化与运算符 的全部内容, 来源链接: utcz.com/p/217217.html