一个前端标签问题


https://gongshang.mingluji.com/beijing/name/朗乐迅洁(北京)科技有限责任公司https://gongshang.mingluji.com/beijing/name/硕链科技有限公司
感觉每个注册资金的标签都不一样啊,这种怎么提取"资金" 标签呢?
回答
你是要只提取资金数值吗?比如“5000”还是说提取整个“5000万元人民币”
如果是后者,直接提取整个span标签的文本内容就行了,然后去掉空格。例如用jquery来提取(至于怎么准确获取到这个span就不说了,方式很多,看具体需求。我就直接写span了)const value = $('span').text().trim();
如果是前者,在上面的基础上,通过正则去匹配,把不是数值的部分过滤掉就行了
----更新
不好意思,没有注意这个span标签里的内容,还有题主说的很多脏数据标签
如果脏数据标签是有规律的就这几种,那可以这样,已经测试过
先通过正则把这些标签都匹配出来,然后过滤掉const reg = /<em[^>]*>(.|\n)*<\/em>|<b[^>]*>(.|\n)*<\/b>|<i[^>]*>(.|\n)*<\/i>|<div[^>]*>(.|\n)*<\/div>/gi;
const valWidthDom = $('span').html();
const realValue = valWidthDom.replace(reg, '');
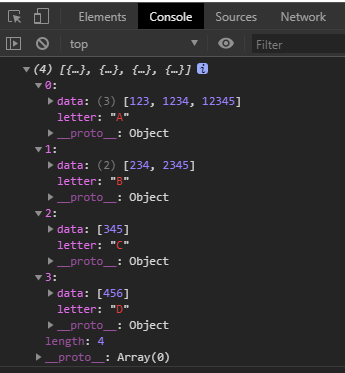
测试结果如下
以上是 一个前端标签问题 的全部内容, 来源链接: utcz.com/a/67262.html