关于使用xpath解析数据返回空列表
**今天使用xpath去解析从豆瓣中爬取的数据时发现返回空列表
于是我对于xpath路径从前往后测试时发现:
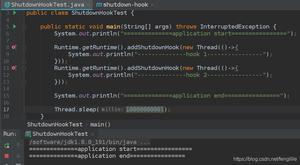
碰到下图绿色箭头所示的标签处就返回空列表,
该标签的上一个标签的属性能够成功获取,
就是卡在了这个标签处,这是为什么呢?*
import requestsfrom lxml import etree
url='https://movie.douban.com/typerank?type_name=%E5%96%9C%E5%89%A7&type=24&interval_id=100:90&action=' //指定url
headers={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'}//UA伪装
response=requests.get(url=url,headers=headers).text//获取响应数据
tree=etree.HTML(response)//实例tree对象
path_0='//*[@id="content"]/div/div[1]/div[6]/@class'//出现问题标签的前一个标签的xpath路径
path_1='//*[@id="content"]/div/div[1]/div[6]/div'出现问题的标签的路径
list_data_0=tree.xpath(path_0)
list_data_1=tree.xpath(path_1)
print(list_data_0)//打印第一个的属性
print(list_data_1)//

然后我就去查看了一下页面的源代码,发现了一个很诡异的事情,页面的源码中,是没有我上述爬取失败的标签,但是这个标签在抓包工具却可以定位到,我好迷呀???

回答
网页上的所有东西,都可以用js来生成,
而requests获取的,只是服务器第一次渲染的html内容。
等浏览器运行后,js开始运行的时候,JS可以再次对原始的html进行修改。
selenium或者找到接口
以上是 关于使用xpath解析数据返回空列表 的全部内容, 来源链接: utcz.com/a/63769.html