
tensorflow使用较为底层的方式复现VGG16
一般在网络上看到一些专业人士写的demo,要么看不懂,要么封装特别好使可移植性减弱。
为了巩固自己对经典网络的认识,我觉得用tensorflow以及tf.nn集成的库对经典网络进行复现,VGG作为最经典网络之一成为我的首要选择。
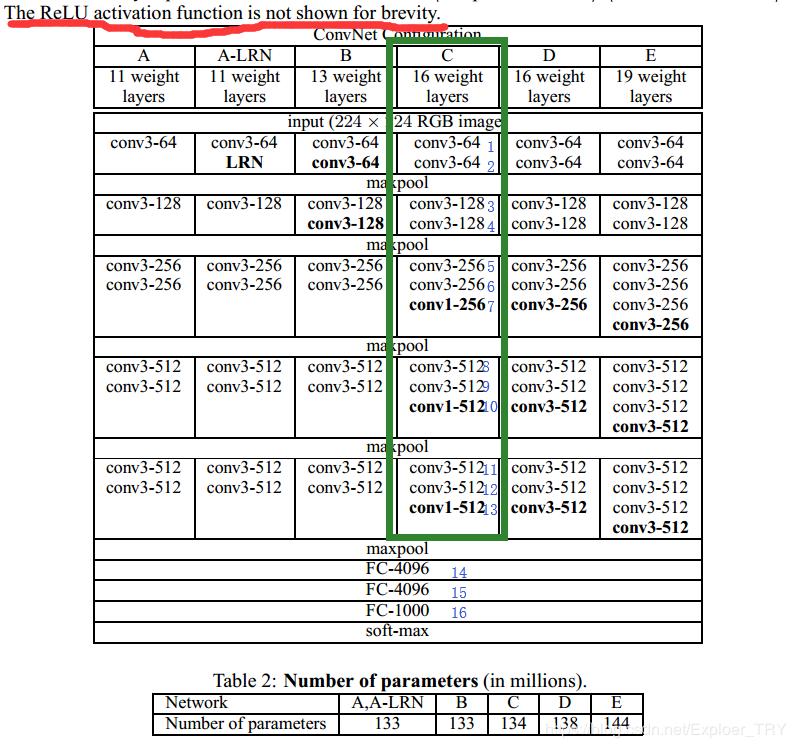
这是论文中的结构示意图,绿框中的是最后的网络结构,论文中提及,每一个卷积后隐层后加上relu激活函数。每次步幅为1,卷积后大小不变。
这里优化函数什么的我就按现在最先进的定义,tensorflow的函数不使用slim或keras。
附上demo:
# -*- coding: utf-8 -*-"""
Created on Wed Mar 19 2019
@author: Ruoyu Chen
The VGG16 networks
"""
import tensorflow as tf
import numpy as np
import os
# REGULARIZER = 0.01
BATCH_SIZE = 10
def weight_variable(shape, name=None):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial, name)
def bias_variable(shape,name=None):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial, name)
def conv2d(input, filter, name=None):
# filters with shape [filter_height * filter_width * in_channels, output_channels]
# Must have strides[0] = strides[3] =1
# For the most common case of the same horizontal and vertices strides, strides = [1, stride, stride, 1]
'''
Args:
input: A Tensor. Must be one of the following types: float32, float64.
filter: A Tensor. Must have the same type as input.
strides: A list of ints. 1-D of length 4. The stride of the sliding window for each dimension of input.
padding: A string from: "SAME", "VALID". The type of padding algorithm to use.
use_cudnn_on_gpu: An optional bool. Defaults to True.
name: A name for the operation (optional).
'''
return tf.nn.conv2d(input, filter, strides=[1,1,1,1], padding="SAME", name=name) # padding="SAME"用零填充边界
def max_pool_2x2(input, name):
return tf.nn.max_pool(input, ksize=[1,2,2,1], strides=[1,2,2,1], padding="SAME", name=name)
def VGG16(input, keep_prob):
# input_size:(224,224,3)
kernel_1 = weight_variable([3,3,3,64], name = 'kernel_1')
kernel_2 = weight_variable([3,3,64,64], name = 'kernel_2')
bias_1 = bias_variable([64],name='bias_1')
bias_2 = bias_variable([64],name='bias_2')
conv_layer_1 = conv2d(input, kernel_1, name = 'conv_layer_1') + bias_1 # size = (224,224,64)
layer_1 = tf.nn.relu(conv_layer_1, name = 'layer_1')
conv_layer_2 = conv2d(layer_1, kernel_2, name = 'cov_layer_2') + bias_2 # size = (224,224,64)
layer_2 = tf.nn.relu(conv_layer_2, name = 'layer_2')
maxpool_1 = max_pool_2x2(layer_2, name = 'maxpool_1') # size = (112,112,64)
kernel_3 = weight_variable((3,3,64,128), name = 'kernel_3')
kernel_4 = weight_variable((3,3,128,128), name = 'kernel_4')
bias_3 = bias_variable([128],name='bias_3')
bias_4 = bias_variable([128],name='bias_4')
conv_layer_3 = conv2d(maxpool_1, kernel_3, name = 'conv_layer_3') + bias_3 # size = (112,112,128)
layer_3 = tf.nn.relu(conv_layer_3, name = 'layer_3')
conv_layer_4 = conv2d(layer_3, kernel_4, name = 'conv_layer_4') + bias_4 # size = (112,112,128)
layer_4 = tf.nn.relu(conv_layer_4, name = 'layer_4')
maxpool_2 = max_pool_2x2(layer_4, name = 'maxpool_2') # size = (56,56,128)
kernel_5 = weight_variable((3,3,128,256), name = 'kernel_5')
kernel_6 = weight_variable((3,3,256,256), name = 'kernel_6')
kernel_7 = weight_variable((1,1,256,256), name = 'kernel_7')
bias_5 = bias_variable([256],name='bias_5')
bias_6 = bias_variable([256],name='bias_6')
bias_7 = bias_variable([256],name='bias_7')
conv_layer_5 = conv2d(maxpool_2, kernel_5, name = 'conv_layer_5') + bias_5 # size = (56,56,256)
layer_5 = tf.nn.relu(conv_layer_5, name = 'layer_5')
conv_layer_6 = conv2d(layer_5, kernel_6, name = 'conv_layer_6') + bias_6 # size = (56,56,256)
layer_6 = tf.nn.relu(conv_layer_6, name = 'layer_6')
conv_layer_7 = conv2d(layer_6, kernel_7, name = 'conv_layer_7') + bias_7 # size = (56,56,256)
layer_7 = tf.nn.relu(conv_layer_7, name = 'layer_7')
maxpool_3 = max_pool_2x2(layer_7, name = 'maxpool_3') # size = (28,28,256)
kernel_8 = weight_variable((3,3,256,512), name = 'kernel_8')
kernel_9 = weight_variable((3,3,512,512), name = 'kernel_9')
kernel_10 = weight_variable((1,1,512,512), name = 'kernel_10')
bias_8 = bias_variable([512],name='bias_8')
bias_9 = bias_variable([512],name='bias_9')
bias_10 = bias_variable([512],name='bias_10')
conv_layer_8 = conv2d(maxpool_3, kernel_8, name = 'conv_layer_8') + bias_8 # size = (28,28,512)
layer_8 = tf.nn.relu(conv_layer_8, name = 'layer_8')
conv_layer_9 = conv2d(layer_8, kernel_9, name = 'conv_layer_9') + bias_9 # size = (28,28,512)
layer_9 = tf.nn.relu(conv_layer_9, name = 'layer_9')
conv_layer_10 = conv2d(layer_9, kernel_10, name = 'conv_layer_10') + bias_10 # size = (28,28,512)
layer_10 = tf.nn.relu(conv_layer_10, name = 'layer_10')
maxpool_4 = max_pool_2x2(layer_10, name = 'maxpool_10') # size = (14,14,512)
kernel_11 = weight_variable((3,3,512,512), name = 'kernel_11')
kernel_12 = weight_variable((3,3,512,512), name = 'kernel_12')
kernel_13 = weight_variable((1,1,512,512), name = 'kernel_13')
bias_11 = bias_variable([512],name='bias_11')
bias_12 = bias_variable([512],name='bias_12')
bias_13 = bias_variable([512],name='bias_13')
conv_layer_11 = conv2d(maxpool_4, kernel_11, name = 'conv_layer_11') + bias_11 # size = (14,14,512)
layer_11 = tf.nn.relu(conv_layer_11, name = 'layer_11')
conv_layer_12 = conv2d(layer_11, kernel_12, name = 'conv_layer_12') + bias_12 # size = (14,14,512)
layer_12 = tf.nn.relu(conv_layer_12, name = 'layer_12')
conv_layer_13 = conv2d(layer_12, kernel_13, name = 'conv_layer_13') + bias_13 # size = (14,14,512)
layer_13 = tf.nn.relu(conv_layer_13, name = 'layer_13')
maxpool_5 = max_pool_2x2(layer_13, name = 'maxpool_10') # size = (7,7,512)
line = tf.reshape(maxpool_5, [-1, 25088])
fc_14 = weight_variable([25088, 4096], name = 'fc_14')
fc_15 = weight_variable([4096, 4096], name = 'fc_14')
fc_16 = weight_variable([4096, 1000], name = 'fc_14')
bias_14 = bias_variable([4096],name='bias_14')
bias_15 = bias_variable([4096],name='bias_15')
bias_16 = bias_variable([1000],name='bias_16')
matmul_layer_14 = tf.matmul(line, fc_14, name = 'matmul_layer_14') + bias_14
layer_14 = tf.nn.relu(matmul_layer_14, name = 'layer_14')
layer_14_dropout = tf.nn.dropout(layer_14, keep_prob, name = 'layer_14_dropout')
matmul_layer_15 = tf.matmul(layer_14_dropout, fc_15, name = 'matmul_layer_15') + bias_15
layer_15 = tf.nn.relu(matmul_layer_15, name = 'layer_15')
layer_15_dropout = tf.nn.dropout(layer_15, keep_prob, name = 'layer_15_dropout')
matmul_layer_16 = tf.matmul(layer_15_dropout, fc_16, name = 'matmul_layer_16') + bias_16
layer_16 = tf.nn.relu(matmul_layer_16, name = 'layer_16')
output = tf.nn.softmax(layer_16, name = 'output')
return output
def backward(datasets, label, test_data, test_label):
X = tf.placeholder(tf.float32, [None, 224,224,3], name = "Input")
Y_ = tf.placeholder(tf.float32, [None, 1], name = 'Estimation')
LEARNING_RATE_BASE = 0.00001 # 最初学习率
LEARNING_RATE_DECAY = 0.99 # 学习率的衰减率
LEARNING_RATE_STEP = 1000 # 喂入多少轮BATCH-SIZE以后,更新一次学习率。一般为总样本数量/BATCH_SIZE
gloabl_steps = tf.Variable(0, trainable=False) # 计数器,用来记录运行了几轮的BATCH_SIZE,初始为0,设置为不可训练
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE, gloabl_steps, LEARNING_RATE_STEP, LEARNING_RATE_DECAY, staircase=True)
keep_prob = tf.placeholder(tf.float32, name = "keep_prob")
y = VGG16(X)
global_step = tf.Variable(0, trainable=False)
loss_mse = tf.reduce_mean(-tf.reduce_sum(Y_ * tf.log(y), reduction_indices=[1]))
# loss_mse = tf.reduce_mean(tf.square(y-Y_))
# train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss_mse)
# train_step=tf.train.MomentumOptimizer(0.001,0.9).minimize(loss_mse) #其他方法
train_step=tf.train.AdamOptimizer(0.001).minimize(loss_mse)
saver = tf.train.Saver()
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
# 训练模型。
STEPS = 500001
min_loss = 1
for i in range(STEPS):
start = (i*BATCH_SIZE) % 862
end = start + BATCH_SIZE
sess.run(train_step, feed_dict={X: datasets[start:end], Y_: label[start:end]})
if i % 100 == 0:
train_loss = sess.run(loss_mse, feed_dict={X: datasets, Y_: label, keep_prob:1})
total_loss = sess.run(loss_mse, feed_dict={X: test_data, Y_: test_label, keep_prob:1})
if total_loss < min_loss:
min_loss = total_loss
f = open('./text/loss.txt', 'a')
f.write("After %d training step(s), loss_mse on train data is %g, loss_mse on val data is %g, min_loss is %g\n" % (i, train_loss, total_loss, min_loss))
print("After %d training step(s), loss_mse on train data is %g, loss_mse on val data is %g, min_loss is %g" % (i, train_loss, total_loss, min_loss))
f.close()
if i % 10000 == 0:
saver.save(sess, './checkpoint/variable', global_step = i)
def main():
# datasets, label, test_data, test_label = reload_all_data()
datasets, label, test_data, test_label = Sequential_disruption()
backward(datasets, label, test_data, test_label)
if __name__ == '__main__':
main()
demo可能不是特别正规,为的仅是了解网络结构以及理解。
这里最开始是导入一些必要的库,但是numpy和os我并没有用到。
然后定义了三个函数:weight_variable,bias_variable和conv2d,为了减小下面demo的长度,都是tf.nn的函数。
然后在VGG16里面,我设置了网络结构,只是向前传播的,每一次卷积都有数字标号,代表第几层。
最后的background就是反向传播,很套路的方法,设置好输入的占位比,衰减学习率,优化器,损失函数。训练时候多少显示一次进展,多少步保存一下。
在最后的main函数里面第一句:datasets, label, test_data, test_label = Sequential_disruption(),这里Sequential_disruption函数没有的,这句话意思是获取训练的数据和标签,以及训练中val的数据与标签。
然后就能够使用该demo训练了。
这个demo我没有实战使用过,但是在jupyter notebook上测试过其网络的正确性。
这样较为底层的demo方便个人的使用,在以后可以基于该网络做出快速的修改。
由于本人时间原因,暂时不做太多的解释工作,如果库不懂什么意思可以查看官方文档,如果有疑惑或异议欢迎留言。
以上是 tensorflow使用较为底层的方式复现VGG16 的全部内容, 来源链接: utcz.com/a/53986.html


