闪电智能创作(莎士比亚和李白)平台前端项目总结
前言
闪电智能平台,我从2018年开始接触这个项目就一直伴随着它一路成长,从一个简单的文案生成平台到现在的智能内容创作,见证了这个平台从功能简单到越来越强大的整个过程。期间进行了多次的项目重构和整合,经历多次的产品升级,改进业务需求,逐渐形成现在比较完善的闪电智能内容创作平台。
它的前身是莎士比亚系统,主要进行智能文案创作;同时还有个李白系统,它主要是文案创作,但是它是偏文艺范诗词类。
在莎士比亚线上运行了一段时间之后,莎士比亚和李白进行了整合,诞生了现在的闪电智能内容创作平台。
1. 闪电介绍
闪电是闪电智能内容创作平台的简称,它是 AI 智能生成平台。支持用户登录网站使用,也支持接口合作模式。针对类目未覆盖、内容类型拓展等个性化需求,支持商家进行邮件提报等功能。主要包含以下五大模块:智能写作、智能视频、智能图片、智能商详、会员体系。
入口地址:https://aisd.jd.com
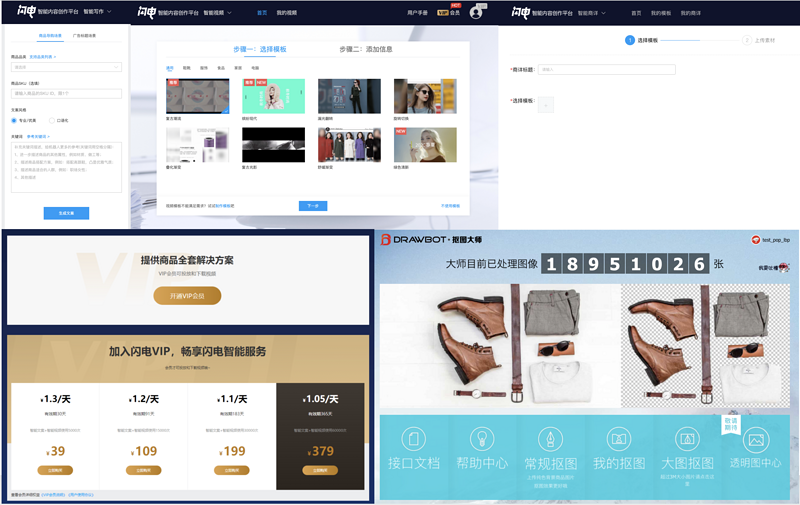
闪电平台推出的时候新增了视频模块,有了第一版的视频生成和视频编辑,在一年多时间里的多次版本迭代,新增了会员体系、智能商详、智能图片、闪电实验室等模块。
现在的闪电智能内容创作平台功能越来越强大,用户数量在大量增加,它的价值正在不断攀升。

整个项目历程中,最难最不常见的是智能视频这个模块,也是投入时间和精力最多的部分。为了更方便的生成视频,更友好的视频编辑体验,先后经历了两次大的改版,做了视频二期、视频三期。
投入这么多,它的收益也是很显著的。
视频模块给了用户更多自由发挥的空间,得到越来越多商家用户的认可,它给商家用户创造的价值是非常巨大的,产出的创作内容越来越多的体现在商品介绍上,也许您浏览的某些商品的短视频介绍就是闪电出品呢!

智能视频是最复杂最具特色的模块,作为前端开发者必须要分享一下我的心路历程,本文就主要基于这个模块谈谈开发时候的一些感受和对前端开发的一些理解。
2. 一个具体业务场景引发的思考
我们接触的项目大多与电商或者 OA 有关,而闪电是个比较特殊的存在,主要体现在智能视频这个模块,从视频生成到视频编辑都有着相当复杂的逻辑和交互。
先来看下这个视频生成的过程。

这不挺简单的嘛,我拿到这个需求的第一反应就是这样。
着手 coding 前先来梳理一下需求流程:
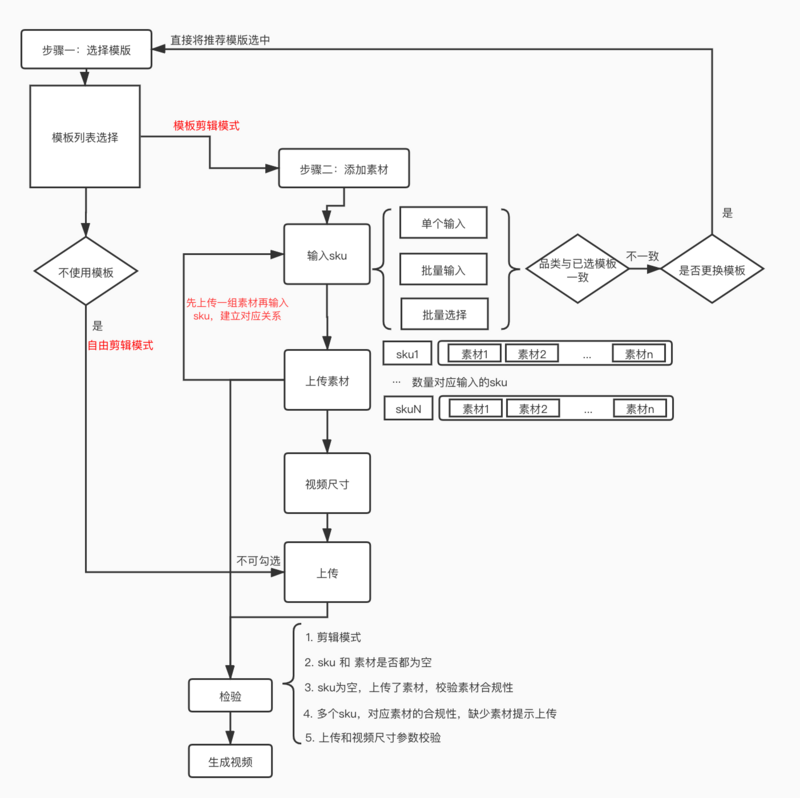
这张流程图中是生成视频的主要流程,还有很多细节的逻辑没有在这里面表达出来,这跟拿到需求的第一反应相差有点大啊!
整个流程下来就一个提交操作,实现这些需求,有以下难点:
- 检验完 sku 的品类属性,需要无感知的切换选中模板
- 步骤一和步骤二之间来回切换需要保证流畅并缓存已添加的内容
- sku 的添加和素材添加的不同顺序,正向和反向建立 sku 和素材的对应关系
- 相对复杂逻辑和交互下达到开发高效、性能高效
有难点就要解决难点,迎难而上,先不要乱了阵脚。
为了能够高效的完成 coding,我们总是会不断的寻找高效解决方案。在前端开发中,比如通过相同的类名设置统一的样式,相同的 DOM 结构完成相似的布局,函数的封装实现相同或相似的逻辑,等等方式来提升我们的效率。
为了更高的开发效率,对上面的几种效率提升方式进行整合,逐渐形成组件化思维,并在项目和框架中运用。
目前的主流框架 React、Vue 都很好的实现了组件化,组件化也是伴随前端发展不可或缺的设计思想,既然 React 拥有组件化的天然优势那就利用起来!恰好本项目使用了 React 技术栈。
先分析一下页面结构和功能,建立起代码框架再进行 coding 。
3. 将需求进行组件化,提高复用性和维护性
分析页面结构和功能是为组件化做准备,那么先了解一下组件化的基本常识。
3.1 组件和组件化的认知
以前我们经常会这样做,使用相同结构的 HTML 结构,定义相同的类,然后写一套 CSS 样式,来达到相同或相似区块的样式结构复用,这在一定程度上有些类似组件的概念,但是这种方式最大的问题在于他们的逻辑并不是相互独立。那么到底什么是组件化呢?
简单来说,组件就是将一段UI样式和其对应的功能作为独立的整体去看待,无论这个整体放在哪里去使用,它都具有一样的功能和样式。
将组件实现复用的这种整体化细想就是组件化。不难看出,组件化设计就是为了增加复用性,灵活性,提高系统设计,从而提高开发效率。
3.2 组件化的大致演变过程
前端最初的模式是频繁的操作 DOM,发送请求,刷新数据,页面局部刷新,是一种典型过程式的开发,开发体验式是很差的。
后来逐步改进,学习后端思想,开始流行 MV* 模式,比如 MVC ,按业务逻辑,UI,功能,划分成不同的文件,结构清晰,设计明了,开发起来也不错。
在这个基础上,又有了更加不错的 MVVM 框架,它的出现,更加简化了前端操作,并将前端的 UI 赋予了真实意义:你所看到的任何 UI,应该都对应其相应的 ViewModel ,即你看到的 View 就是真实的数据,并且实现了双向绑定,只要 UI 改变,UI 所对应的数据也改变,反之亦然。这的确很方便,但大部分的 MVVM 框架,并没有实现组件化,或者说没有很好的实现组件化,因为 MVVM 最大的问题就是:
1. 执行效率,只要数据改变,它下面所有监测数据上绑定的 UI 一般都会去更新,效率很低,如果你操作频繁,很可能会非常频繁的更新 UI ,造成性能问题。
2. 由于 MVVM 一般需要严格的 ViewModel 的作用域,因此大部分情况不支持多次绑定,或者只允许绑定一个根节点做为顶层DOM渲染,这就给组件化带来了困难(不能独立的去绑定部分UI)。
而后,在此基础上,一些新的前端框架“取其精华,去其糟粕”,开始大力推广前端组件化的开发方式, React 和 Vue 则是先行者。
就 React 而言,它是单向数据流管理设计的先驱,React + Redux 将 MVC 做到了极致。下面请看一个实例。
3.3 组件化过程的亲身经历
React 提供了很好的组件化开发环境,以生成视频的过程进行页面和功能分析,逐步实现组件化。
3.3.1 页面分析,块级划分页面结构
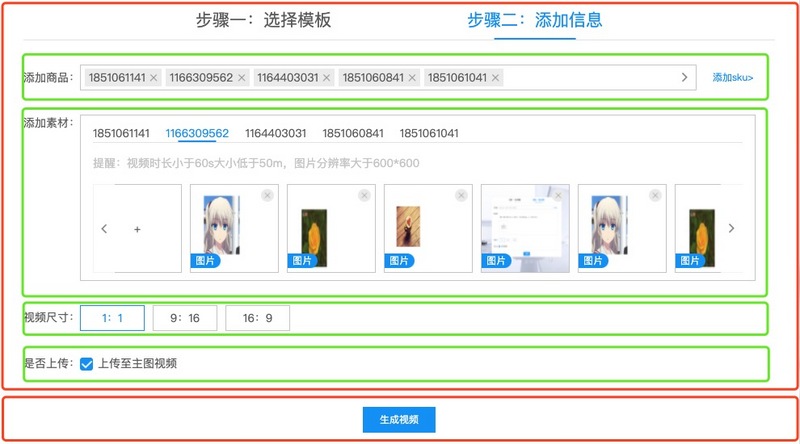
根据页面内容,可以分为上下两部分,上方是两个操作步骤,下方是主按钮。
步骤一的模板选择划分一个部分,步骤二中每个步骤划分为一个部分。步骤二中的每个部分是有相似之处的,即都分为左侧的标题和右侧的内容区域,这是可以复用一些布局的。
基于此番分析,我们基本的页面结构就有了。
<div class="video-index_main"><div class="video-main">
<div class="tabs-nav"></div>
<div class="tabs-body">
<div class="upload-item">添加商品:</div>
<div class="upload-item">添加素材:</div>
<div class="upload-item">视频尺寸:</div>
<div class="upload-item">是否上传:</div>
</div>
</div>
<div class="button-container">生成视频</div>
</div>
主要的页面结构基本是这样,但是看到上面的功能截图,这每一个块 div 中的内容仍然是很多的,如果都在这一个文件中进行开发,将会显得非常繁杂,试想一下 React 组件的 render 中 jsx 代码几百上千行,想想可能都觉得头大吧,另外为实现各种交互需要维护的状态也将非常多,还有最重要的问题,局部的某个交互更新 state 也将重新渲染整个组件,这将是非常大的性能消耗。
3.3.2 功能划分,按功能拆分页面
接下来按照功能块进行拆分。
<div class="video-index_main"><Tabs>
<TabPanel label="步骤一:选择模板">
<Templates/>
</TabPanel>
<TabPanel label="步骤二:添加信息">
<UploadMaterial>
<SkuInput />
<Material />
<Aspect />
<Upload />
</UploadMaterial>
</TabPanel>
</Tabs>
<div class="button-container">生成视频</div>
</div>
这样将步骤一的内容独立成一个文件,步骤二独立成一个文件,步骤二中的每个部分再拆分成独立的文件,就有了上面的结构, Tabs 则是一个组件。这样将具有比较复杂的交互操作的块相互分开,整个页面结构也更加清晰了。
3.3.3 抽象组件,将可复用的功能块组件化
再来看下组件化,仔细观察不难发现一些相似的结构和功能是可以复用的。

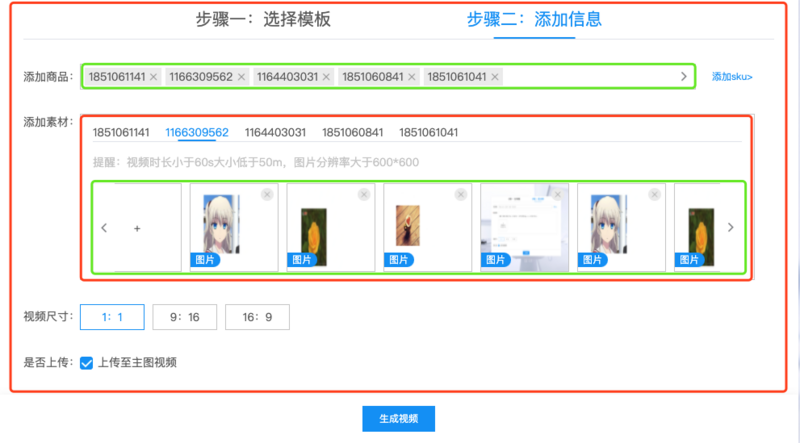
看上面这两张图不难发现,有一些相似之处,整个外层是一个大的 Tab,选择模板中依然是一个 Tab,而添加素材这里面仍然是一个 Tab,只是长的样式上些微有些差别罢了,但是功能上却是如此的一致。
再来看添加商品 sku 这块当 sku 数量角度的时候需要能够左右滚动,添加素材中 sku 对应的一组素材同样有这样的需求,而且别的页面也有这样的需求。
基于此这块内容至少可以抽象出两个通用组件 Tabs、 HorizontalScroll 。步骤二又可以抽象出 AddItem 组件。
<div class="video-index_main"><Tabs>
<Tabs.TabPanel label="步骤一:选择模板">
<Templates />
</Tabs.TabPanel>
<Tabs.TabPanel label="步骤二:添加信息">
<AddItem title="添加商品:" cls="add-sku"><SkuInput /></AddItem>
<AddItem title="添加素材:" cls="add-material"><Material /></AddItem>
<AddItem title="视频尺寸:" cls="aspect"><Aspect /></AddItem>
<AddItem title="是否上传:" cls="deploy"><Deploy /></AddItem>
</Tabs.TabPanel>
</Tabs>
<div class="button-container">生成视频</div>
</div>
AddItem 组件右侧的内容和布局并不相同,这并不是组件本身的差异,因此给出自定义的 class 入口,可根据 class 重写相应的样式。
Tabs 组件前后用到了三次,嵌套使用,这样只需要切换的交互逻辑只需要处理一次,只需要对样式的不同进行覆盖。HorizontalScroll 组件同样如此,在封装好组件之后将不在关注他的功能,直接使用即可,这在多次重复用到的场景将变的非常效率。
这里只是列举了比较大的组件的划分,里面还有一些小组件的划分,比如每个 sku 的划分,每个素材的划分,这些小组件划分的意义在于,它的状态只需要维护在它自己的文件中,组件的更新也只会影响它的这个组件返回,将会大大减少父级组件的重新渲染。这也是性能优化的一种手段,即降低组件重新渲染的次数和范围。
既然组件拆分可以为我们带来这么多的好处,那就把页面上的内容全部拆分成大大小小的组件吧!这样真的好吗?
3.3.4 组件拆分粒度,权衡组件拆分利弊
最近经常和同事讨论起组件化拆分的利弊问题,部分人认为组件化会导致代码分散,可读性和可维护性变得比较差,数据传递变得复杂;部分人则认为组件化能够使代码结构清晰、模块划分明确、能够提升页面渲染性能。所以怎么选择呢?
这是个值得深思的问题,拆还是不拆这是个问题...
经过项目实践我认为,拆分组件的目的无非以下几个:
- 提高复用率,避免代码和逻辑臃肿
- 模块划分,可根据页面结构模块化开发
- 提高性能,细化组件可减小状态变化引起的重新渲染的范围
基于以上目的再进行组件拆分,或许会有不一样的结果。再配合 redux 之类的数据管理,性能提升将会更加明显。
个人认为在一个大型前端项目中,这种组件化的抽象设计是很重要的,不仅增加了复用性提高了工作效率,从某种程度上来说也反应了程序员对业务和产品设计的理解,一旦有问题或者需要功能扩展时,也许很多之前的组件就能派上用场从而节约开发工时。

页面分析和组件抽象也同样适用于视频编辑页,具体的组件化实现就不多说了,但是这个页面数据流更加复杂。
页面组件化仅仅只是完成了开发的初步工作,很顺畅,很丝滑,接下来就开始业务数据开发吧。
React 是单向数据流管理,那么组件之间如何通信将是个非常重要的问题。这可能也是有些时候不愿意拆分组件的重要原因。
4. 将数据独立管理,从业务逻辑中剥离
上面说到组件化开发中最重要的问题是数据流的问题,当我们把一个模块拆分成多个组件的时候,数据可能就会分散到各个组件中了,同时由于 React 单向数据流的特性,数据只能由上至下传递,也就是只能从父组件传往子组件,那么更不好解决的问题是同级兄弟组件之间的数据通信,以及多层嵌套下的 Prop 传递。
4.1 单向数据流的工作模式
如果只是用 React 本身的 props 或者 state 开发将变得非常恶心,很多层级的 props 传递很容易混淆和丢失,同时根组件的性能消耗也是非常大的,兄弟组件之间的数据通信也需要通过频繁的回调来处理。
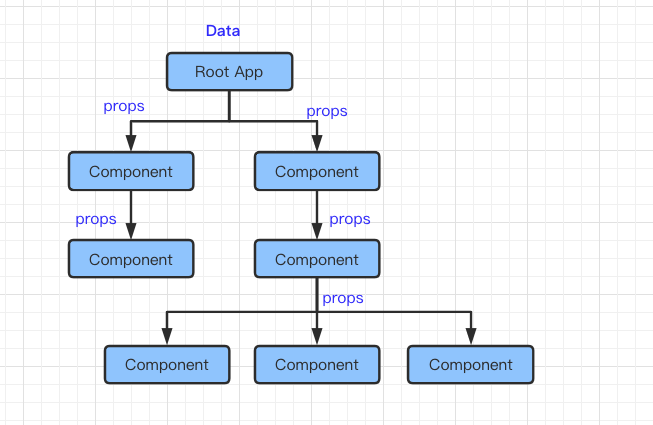
就像上面这样,看似组件拆分了,实则数据都依赖于顶层,而且需要逐级向下传递,当 props 发生变化需要 re-render 的时候也会变得难以处理,是否还记得 componentWillReceiveProps 和 shouldComponentUpdate 这些 API ,它们就是用来处理这种难题的,但是使用不当也会造成更严重的问题。
4.2 状态提升的工作模式
状态提升,同级组件中共同使用的状态需要统一维护在它们的父级组件中,然后组件同时订阅,要想更改状态,需要在子组件中去修改组件中的状态,同时其他子组件重新获取状态重新 render 。
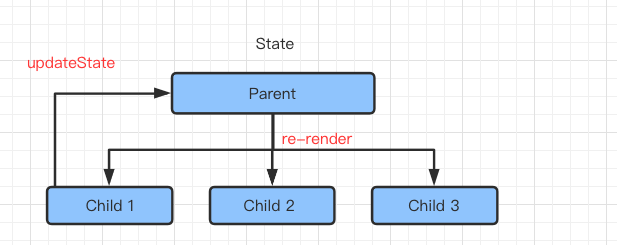
这是最简单的状态提升,当嵌套层级比较深的时候,这个过程将变得非常繁杂,每一层组件都将传递很多的 props 属性和回调函数,越往下越多,很容易就混乱了。
4.3 状态共享的工作模式
在 React V16.3 之前虽然有官方提供的 context API ,但是存在一个问题:看似跨组件,实则还是逐级传递,如果中间组件使用了 ShouldComponentUpdate 检测到当前 state 和 props 没有变化,return false,那么 context 就会无法透传,因此 context 没有被官方推荐使用。
React V16.3 之后,新版的 context 解决了之前的问题,可以轻松实现,但依然存在一个问题,context 也是将底部子组件的状态控制交给到了顶级组件,但是顶级组件状态更新的时候一定会触发所有子组件的 re-render ,也会带来损耗。虽然可以通过一些手段来减少重绘,比如在中间组件的 ShouldComponentUpdate 里进行一些判断,但是当项目较大时,需要花很多的精力去做这件事。
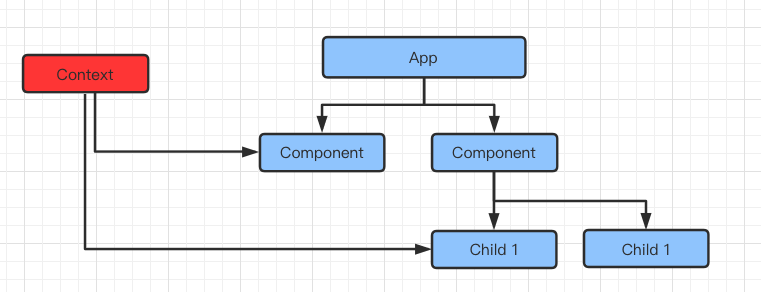
数据流的问题,状态共享的问题似乎已经得到了解决,但总觉得不得劲。
当某个组件的业务逻辑非常复杂时,代码会越写越多,因为只能在组件内部去控制数据流,没办法抽离,Model 和 View 都放在了 View 层,整个组件显得臃肿不堪,业务逻辑统统堆在一块,难以维护,看的人头大。
当数据流混乱时,我们一个执行动作可能会触发一系列的 setState ,如果能够让整个数据流变得可“监控”,甚至可以更细致地去控制每一步数据或状态的变更,那将会是一件非常棒的事情。
React 自身并未提供多种处理异步数据流管理的方案,仅用一个 setState 很难满足一些复杂的异步流场景;
总结下来,使用 React 数据流依然存在以下问题:
- 组件臃肿
- 状态变得难以预知,难以回溯
- 异步数据流难以处理
4.4 使用数据流管理工具,解决数据流造成的问题
为解决以上问题,需要用到数据流管理工具来帮助实现,希望通过数据流管理工具能够将数据从 React 组件中脱离出来,只负责管理数据,让 React 专注于 View 层的绘制,这样我们的组件也将变得干净,划分更加明确。
数据流管理工具世面上有很多,比如 redux、mobx、dva等,他们都能和 React 很好的结合,这里就不多做介绍了。本次以 redux 作为数据流管理工具来说明一下解决上述问题的思路。
- store: 提供一个全局的 store ,用来存储从组件中抽离出来的状态
- action:一个对象,用来记录每次状态的变更,可打印日志与调试回溯,也是
- reducer: 纯函数,处理 action,计算状态返回最新的状态。
这是 redux 提供的最基本的也是最核心的功能,这里不多做解释。再配合 react-redux 将状态 store 与组件关联起来,这样组件就可以订阅到 store 中的状态,实现状态共享。
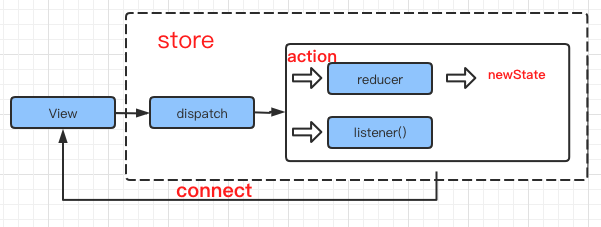
前文说到组件化之后会出现多层级的 props 传递问题,同级组件之间的状态共享问题,在结合 redux 之后,这些问题将会得到解决。
组件需要去订阅 store 中的状态,在状态发生改变的时候 re-render 组件,这样可以避免逐级传递 props ,同时也很方便的解决了同级组件之间状态共享的问题。
更重要的是,通过合理的订阅 store 中的值,可以大大减小因为状态改变导致的 re-render 的范围,这也是性能提升的一大手段。
此时组件中只包含私有的状态和 UI 渲染逻辑,数据已经分离出去,组件也将逐渐变得纯净,这也大大有利于组件的抽象提取。
5. 开发中遇到的问题
5.1 H5拖拽便捷实现元素拖动效果
在三期改版中对视频编辑做了大量的调整,为了用户能够更方便的使用编辑功能,优化了很多交互。最大的改变是将视频资源进行拆分,拆分成为文字轨道、视频轨道、音频轨道,同时可以对不同轨道的内容进行编辑,比如添加或替换新的素材、更换转场、添加卖点文字、更换背景音乐等。
在此次优化中产品提出了拖拽元素进行内容编辑,比如添加新的素材、更换转场、添加卖点文字。

这是其中一个功能,将素材内容添加到素材轨道中,然后重新生成新的视频,要实现它却也费了不少功夫。
一开始考虑到用定位来做,可以实现,但是面临的问题将会非常多,计算量也非常大,再加上不同的浏览器大小也会对计算造成很大影响,还有组件化开发导致的组件件的通信也会变得更加复杂,这种种原因使得我不得不另找出路。
由于项目只需要支持到 IE 10 以上,可以使用 H5 拖拽。那么问题似乎就变得简单了起来。
拖拽的过程很简单,拖动开始 --> 拖动移动 --> 拖动释放。
| 操作对象 | 事件 | 说明 |
|---|---|---|
| 被拖动元素 | dragstart | 在元素开始被拖动时候触发 |
| drag | 在元素被拖动时反复触发 | |
| dragend | 在拖动操作完成时触发 | |
| 目标元素 | dragenter | 当被拖动元素进入目的地元素空间范围时触发 |
| dragover | 当被拖动元素在目的地元素内时触发 | |
| dragleave | 当被拖动元素没有放下就离开目的地元素时触发 | |
| drop | 当被拖动元素在目的地元素里放下时触发 |
可以看到拖拽需要两个元素,一是需要一个可以被拖拽的元素,二是需要一个接受的目标元素,这两个元素都必须添加 draggable="true" 属性。
一个简单的demo:
<div class="container"><span class="drag" draggable="true" id="drag">拽我</span>
<div class="drop" draggable="true" id="drop"></div>
</div>
let drag = document.getElementById('drag');let drop = document.getElementById('drop');
drag.addEventListener('dragstart', (e) => {
console.log('start');
e.dataTransfer.setData('text', '拽我');
});
drop.addEventListener('dragenter', () => {
console.log('dragenter');
});
drop.addEventListener('drop', (e) => {
console.log('drop');
const text = e.dataTransfer.getData('text');
drop.innerHTML += text;
});
很简单的 demo 试运行一下,结果是并没有成功达成预期效果。
查阅资料发现, dragenter 和 dragover 事件的默认行为是拒绝接受任何被拖放的元素。因此,必须阻止浏览器这种默认行为,不然是不会触发 drop 事件的。
drop.addEventListener('dragover', (e) => {console.log('dragover');
e.preventDefault();
});
在需求中对拖动元素的对应数据进行操作,通知学习才知道要给拖拽目标设置数据的话,需要在被拖动元素开始拖拽的时候以字符串的格式设置数据,比如 e.dataTransfer.setData('text', '拽我') ,在目标元素释放的时候去接收,const text = e.dataTransfer.getData('text') ,这点成为实现需求的关键。
drag.addEventListener('dragstart', (e) => {console.log('start');
e.dataTransfer.setData('text', '拽我');
});
drop.addEventListener('drop', (e) => {
console.log('drop');
const text = e.dataTransfer.getData('text');
drop.innerHTML += text;
});
好了,看下效果。

5.2 应用拖拽轻松实现复杂的素材添加功能
上面实现了元素拖拽,拖拽完成之后,还要实现以下功能:
- 如果是在之前的视频片段是释放,是替换之前的素材内容(对应下图的绿色区域)
- 如果是在素材片段之外的空白区域释放,则是在末尾添加片段 (对应下图的红色区域)
- 如果是在两个片段之间释放,则是插入新的片段 (对应下图的蓝色区域)
- 两个片段之间还有转场效果,需要排除这种(对应下图的灰色方块)
- 进入可释放区域需要展示蓝色边框

实现起来是相当复杂的,需要对很多的元素进行做监听,同时必须阻止事件冒泡,才能准确捕捉释放区域。
本次需求中可拖拽的操作包含素材、卖点文字、转场效果,这些不同的功能拖拽释放的区域是有交叉的,或者说在拖拽结束后该执行哪种操作呢?这就必须用到 e.dataTransfer.setData(format, data) ,同时在拖拽释放的时候根据 e.dataTransfer.getData(format) 来获取数据,只有获取到相应数据才可以进行相应的响应。
还记得上面说的组件化吗,那么这里是不是就是个很适合呢?红色、蓝色、绿色框的部分分别对应一个组件,那么在判断拖拽元素是否进入该区域并显示边框给出反馈,这将变得简单很多,想一想不拆分组件的话怎么区分进入的是哪一个区域呢?
在这期间进行的每一个动作都保存为新的数据,在下次生成视频的时候需要将这些数据传给后台,这里也同样用到了 redux 进行数据管理,替换素材直接将 redux 中的字段值进行修改,然后重新渲染元素,添加片段也是将 redux 中的 list 进行添加,再渲染列表,这将很大程度上降低了数据管理的难度,而且在提交重新生成的时候只需要直接从 redux 中拿取,避免了组件之间的参数传递。
5.3 巧妙实现组合快捷键操作
为了提升用户体验,实现了上一步、下一步删除的快捷操作,页面上的每一步操作都需要对数据进行保存,那撤销和删除快捷操作其实是对数据的回退和恢复,将数据置为上一个或下一个状态,那该怎么做呢?
本次实现采用了比较粗暴的方式,每一次页面操作都将数据进行备份,每一次快捷错做则是将备份数据中的某一条设置为当前数据。
// 上一步、删除case UNDO_OPERATION:
if (state.stackPointer > 0) {
const currentStackPointer = state.stackPointer - 1
const currentVideoDetail = state.operationStack[currentStackPointer]
return {...state, stackPointer: currentStackPointer}
}
return state
// 下一步
case REDO_OPERATION:
if (state.stackPointer < state.operationStack.length - 1) {
const currentStackPointer = state.stackPointer + 1
const currentVideoDetail = state.operationStack[currentStackPointer]
return {...state, stackPointer: currentStackPointer}
}
return state
快捷键一般都是组合键,比如本次需求的 Ctrl + Z 、Ctrl + Y ,如何才能准确捕获到呢?可以监听键盘事件如:
window.onkeyup = (e) => {// Ctrl + Z
if (e.code === 'KeyZ' && e.ctrlKey) {
console.log('KeyZ')
return
}
// Ctrl + Y
if (e.code === 'KeyY' && e.ctrlKey) {
console.log('KeyY')
return
}
}
为什么没有用 keyCode 做判断呢?
在 IOS 和 windows 中 keyCode 的值不尽相同,可能会存在判断不准确的问题,而 e.code 得到的按下键的键名是相同,这就不用考虑操作系统的问题了。
再通过 e.ctrlKey 判断是否按下了 control 键,这样便能准确识别出组合快捷键。
6. 项目优化
经过多次需求的迭代,再回看代码是不是有一种 “这代码绝对不是我写的” 的感觉。那么在最近几次的迭代中我们也是在不断的做项目优化,包括打包、页面性能提升等。
6.1 代码提取,避免重复打包
以上这些是组件思维在实际项目中的应用,以及为什么需要组件化抽离。其实组件化抽离也为性能优化提供了帮助。
之前项目是将所有的文件打包成一个 js 文件,在最近几次的版本迭代中逐渐做了些优化。
打包成一个 js 文件,文件会比较大,会影响加载速度,特别是首页表现的特别明显,可能会有白屏时间。

其实最终打包的内容包含第三方模块、公共组件、业务代码,那么可以将第三方和公共组件抽离出来,单独打包。
抽离公共代码都是在optimization.splitChunks 中进行配置。
optimization: {splitChunks: {
minSize: 100,
cacheGroups: {
vendor: {
priority: 1, //设置优先级,首先抽离第三方模块
name: 'vendor',
test: /[\/]node_modules[\/]/,
chunks: 'initial',
minChunks: 1
},
default: {
//公共模块
chunks: 'initial',
name: 'common',
minChunks: 2, //最少引入了2次
}
}
},
}
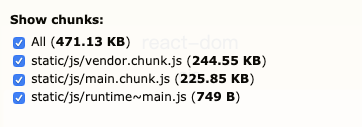
公共代码抽离出来后,这些代码就下载一次就缓存起来,避免重复下载。这也是组件化开发的一大好处。
可以看到按需加载后 第三方模块 vendor 的大小也小了很多,首页的 main.js 体积也小很多,其余的 js 和公共模块会在相应的页面再去加载,这样每个页面加载的资源体积就会小很多,可以大大提升页面加载速度,同时可以避免网络资源的浪费。
可以借助 webpack-bundle-analyzer 查看文件体积以及组成部分。
const BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin;const merge = require('webpack-merge');
const baseWebpackConfig = require('./webpack.config.base');
module.exports = merge(baseWebpackConfig, {
//....
plugins: [
//...
new BundleAnalyzerPlugin(),
]
})
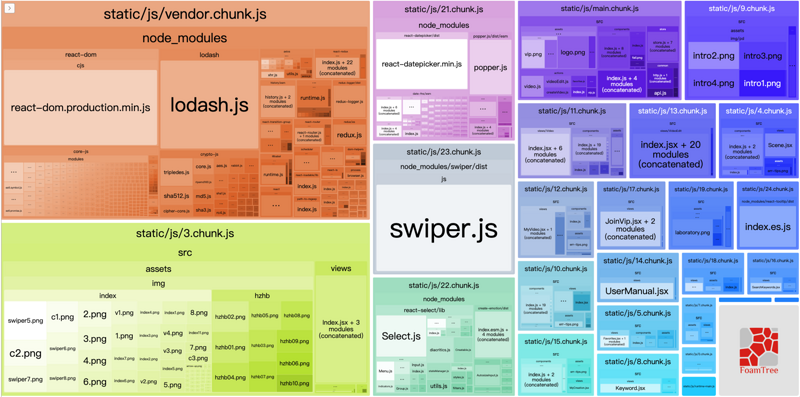
借助这个插件可以对文件大小进行分析,根据实际需要进行进一步的拆分,增加 cacheGroups 的设置即可。
6.2 按需加载,提升页面加载速度
之前项目是一次性加载所有 js 、css 资源,最近开发中改变成按需加载,用来提升首页加载速度,节省网络资源。
结合按需加载,可以将文件拆分的更小,模块提取的粒度更细些。在闪电项目中用到页面按需加载,打包结果如下:

新版 React 提供了按需加载的解决方案,那就用起来。
import React, { lazy } from 'react';const Index = lazy(() => import('./views/Index'));
...
要渲染哪个组件再去加载对应的 js ,单个 js 的体积也是很小的,将会很大程度上提高页面加载速度。
代码拆分打包后会有多个 chunk ,加载过一次就会被浏览器缓存,那么按需加载的时候被加载的资源就会变得越来越少。
6.3 页面架构优化,降低维护成本
项目之初是将公共的头尾组件在每个页面中引入,也就是说每次路由跳转都要重新加载和渲染头尾组件,而头尾组件中有一些用户信息的接口,这会造成每次切换路由的时候都会重新请求,这在大多数情况下是没必要的,为了减少不必要的渲染和接口请求,并次页面架构优化。将公共头尾提取出来。
ReactDOM.render((<Provider store={store}>
<Suspense fallback={<div className="loading">loading</div>}>
<HashRouter>
<div className="container-wrapper">
<Route component={Header} />
<Switch>
<Route path={routePaths.INDEX} exact component={Index} />
<Route path={routePaths.SCENE} component={Scene} />
<Route path={routePaths.FAVORITES} istore={store} component={Favorites} />
...
<Redirect to={routePaths.INDEX} />
</Switch>
<Route render={props => {
let hasFooterRoute = [routePaths.INDEX, routePaths.JOINVIP, routePaths.LABORATORY];
return hasFooterRoute.indexOf(props.location.pathname) > -1 ? <Footer /> : null
}} />
</div>
</HashRouter>
</Suspense>
</Provider>
), document.getElementById('root'));
路由变化只是加载 Switch 中的内容组件,头尾将固定。
![]()
头部 Header 组件中页包含比较多的逻辑,比如头部中的导航在不同的路由下展示的内容是不同的,之前由于 Header 分散在各个页面组件中,对应的逻辑也分散在各个组件中,这样其实是很难维护的,那么本次也将根据理由的变化在 Header 中对这些逻辑集中处理,这更有利于组件的维护。
这样做有一个问题,之前在另一个项目中也遇到过,当 Header 作为一直展示的通用组件,如何在每次路由切换的时候更新它所依赖的数据呢?
我最开始使用的是最暴力的方式,利用 Route 的 render 属性,在路由切换时先更新数据再渲染组件。
<Routerender={props => {
getUserInfo(); // 更新数据的方法
return <Header />
}}
/>
这个方法看似解决了需求的问题,但是有个非常明显的弊端,就是路由每次变化都要重新渲染组件,其实有很多的的渲染是完全没必要的,但是这种情况下并没有办法进行拦截,而且即使是相同的路由,组件也会重新 render 导致进行了没必要的接口请求和组件渲染,一番折腾尝试总结了以下几种更好的路由监听方案。
6.3.1 history 监听
class Header extends Component {componentDidMount() {
// 监听路由的变化,如果路由发生变化则进行相应操作
this.props.history.listen(location => {
// 最新路由的 location 对象,可以通过比较 pathname 是否相同来判断路由的变化情况
if (this.props.location.pathname !== location.pathname) {
// 路由发生了变化
}
})
}
}
6.3.2 组件重新渲染前后
class Header extends Component {componentWillReceiveProps (nextProps, nextState) {
if (this.props.location.pathname !== nextProps.location.pathname){
// 路由发生了变化
}
}
}
同样 componentDidUpdate 、componentWillUpdate 两个生命周期中也是能够去识别出路由变化的。
以上两种方式再结合 shouldComponentUpdate 可以减少组件不必要的渲染
class Header extends Component {// 当路由发生变化的时候再重新render
shouldComponentUpdate(nextProps) {
let prevRouteName = this.props.location.pathname;
let currentRouteName = nextProps.location.pathname;
return prevRouteName !== currentRouteName;
}
}
6.3.3 hooks 方式监听
import React, { useEffect } from 'React';const Header = function (props) {
useEffect(() => {
console.log(props.location);
}, [props.location])
}
export default Header;
其实监听路由最重要的就是监听 props 中 location 对象是否发生了变化,变化了则说明路由改变了,反之则不变。
监听的时机,一种是组件挂载后利用 this.props.history.listen ,另外一种是监听 props 的变化,这包括了 componentWillReceiveProps 、 componentDidUpdate 、componentWillUpdate,也就是组件接收新的 props,组件将要更新,组件更新完成这几个时间节点,hooks也是一样监听的是 props.location 的变化。
由于是旧项目没有使用 hooks,最终我使用了 this.props.history.listen + shouldComponentUpdate 的方式,在新项目中使用 hooks 将会变得更加的简单方便。
总结
经过将近两年的时间不断打磨的闪电智能内容创作平台已经逐渐稳定,功能越来越强大,使用的商家越来越多,产出内容覆盖到的商品品类也多了起来,正在逐步产品化商业化。对于我们前端来说提升和改善的空间还很大,第一次在将 AI 和前端进行结合,我们正在探寻更成熟更高效的技术方案,这对我们来说是机会更是挑战。
以上是 闪电智能创作(莎士比亚和李白)平台前端项目总结 的全部内容, 来源链接: utcz.com/a/31941.html