kafka-可靠的数据传递
可靠性保证
了解系统的保证机制对于构建可靠的应用程序来说至关重要,这也是能够在不同条件下解释系统行为的前提。kafka做出了以下保证
- kafka可以保证分区消息的顺序。如果使用同一个生产者往同一个分区写入消息,而且消息B在消息A之后写入,那么kafka可以保证消息B的偏移量比消息A的偏移量大(这个是指保证消息指到达broker处的顺序,消费者消费的顺序一定是消息到达broker的顺序)
- 只有当消息被写入分区的所有同步副本时(但不一定要写入磁盘),它才被认为是“已被提交”的。生产者可以选择接收不同类型的确认,比如在消息被完全提交时才确认,或者在消息被写入首领副本时的确认,或者在消息被发送到网络时的确认。
- 只要还有一个副本是活跃的,那么已经提交的消息就不会丢失
- 消费者只能读取已经提交的消息
强有序的场景不使用kafka
这些基本的保证机制可以用来构建可靠的系统,但仅仅依赖它们是无法保证系统完全可靠的。构建一个可靠的系统需要作出一些权衡,消息存储的可靠性、一致性的重要程度与可用性、高吞吐量、低延迟和硬件成本的重要程度之间的权衡。
复制
kafka的复制机制和分区的多副本架构是kafka可靠性保证的核心。把消息写入多个副本可以使kafka在发送崩溃时仍能保证消息的持久性。
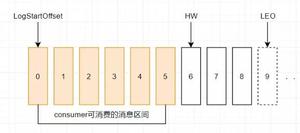
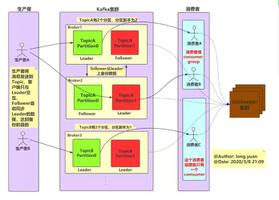
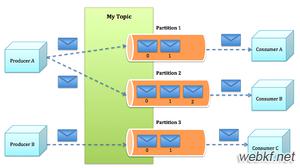
kafka的主题被分为多个partition,partition是基本的数据库。partition存储在单个磁盘上,kafka可以保证分区里面但事件是有序的,分区可以在线(可用),也可以离线(不可用)。每个分区都可以有多个副本,其中一个副本是首领。所有的时间都直接发送给首领副本,或者直接从首领副本读取事件。其他副本只需要与首领保持同步,并及时复制最新的事件。当首领副本不可用时,其中一个同步副本将成为新首领。
生产者与消费者都是直接与首领partition沟通,不会与跟随者沟通;(每次生产、消费数据之前都会拉取partition首领信息)
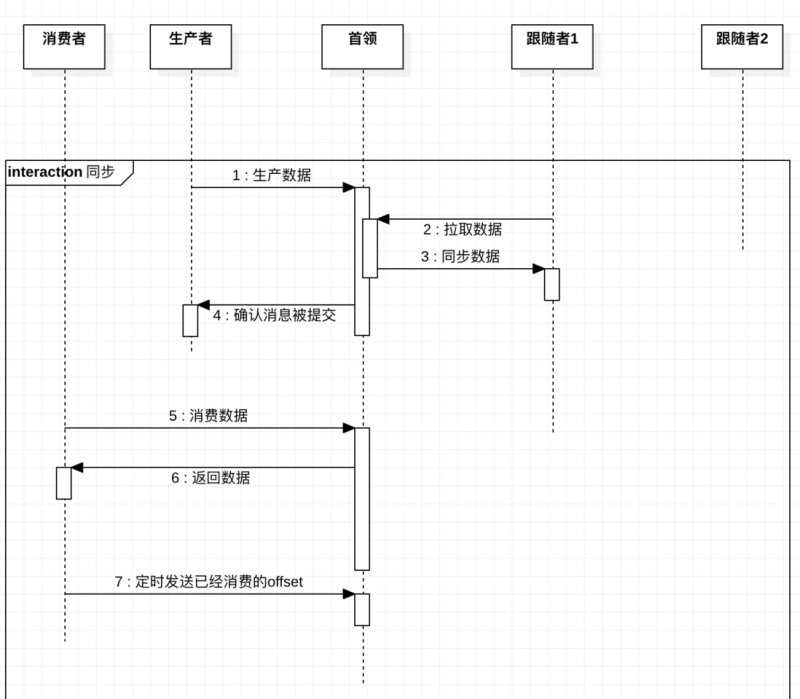
分区首领是同步副本,对于跟随者来说,它需要满足以下条件才能被认为是同步的
- 与zookeeper之间有一个活跃的会话,也就是说,它在过去的6s(可配置)内向zookeeper发送过心跳
- 在过去的10s内(可配置)从首领那里获取过消息。
- 过去10s内从首领那里获取过最新的消息,光从首领那里获取消息是不够的,它还必须是几乎零延迟(与leader同步)的。
我们可以配置同步副本的个数,也可以配置同步副本的定义。kafka提供了灵活的配置。
broker配置
broker有三个配置可以会影响Kafka消息存储的可靠性。与其他配置参数一样,他们可以作用在broker上,用于控制所有主题行为。也可以作用在主题上。这意味着kafka集群可同时拥有可靠的和不可靠的主题。
| 参数 | 说明 | 可选值 | 默认值 |
|---|---|---|---|
| replication.factor(主题级别)default.replication.factor(broker级别) | partition的复制数量 | 数字 | 3 |
| unclear.leader.election(broker级别) | 是否允许不完全同步的副本成为首领副本 | true、false | true |
| min.insync.replicas | 最小同步副本数,当同步副本数小于这个值的时候。集群会拒绝写入。 | 数字 |
consumer配置
每个kafka都应该注意两件事情
- 根据场景,设置正确的ack
- 在参数配置和代码中正确的处理错误
| 参数 | 说明 | 可选值 | 默认值 |
|---|---|---|---|
| ack | 生产者消息确认方式 | 0:发送出去即认为成功;1:首领收到便认为成功;all:所有同步副本同步认为成功 | |
| retries | 当生产者收到异常时,重试次数 | 数字 |
retries重试机制可能会导致消息重复,重试和恰当的错误处理可以保证“至少一次”。但是在kafka版本(0.10.0)无法保证每个消息“只被保存一次”。我们可以加入唯一标识符或者通过消费者幂等来解决
额外的错误处理
大部分错误可以通过kafka自身的重试机制实现,但是有一些错误需要我们程序自己处理
- 不可重试的broker错误,例如消息大小错误、认证错误
- 在消息发送前的错误,比如序列化错误
- 在生产者重试次数超过上线或者在消息占用的内存达到上线时发生的错误
消费者配置
只有那些被提交到kafka的数据,也就是那些被写入所有同步副本的数据才对消费者是可见的。这意味着消费者得到的消息具有一致性。消费者唯一要做的就是跟踪哪些消息是已经处理过的。这是读取消息时不丢失消息的关键。
消费者唯一要做的事情就是跟踪哪些消息是已经处理过的
| 参数 | 说明 | 可选值 | 默认值 |
|---|---|---|---|
| group.id | 消费组id | 数字 | |
| auto.offset.reset | 当没有offset时(比如消费者第一次启动),消费者从哪读取 | earliest:从分区最开始地方读取;latest:从分区末尾开始读取 | earliest |
| enable.auto.commit | 可以让消费者自动提交偏移量 | true、false | true |
| auto.commit.interval.ms | 与自动提交参数相关,每隔多久提交一次 | 数字 |
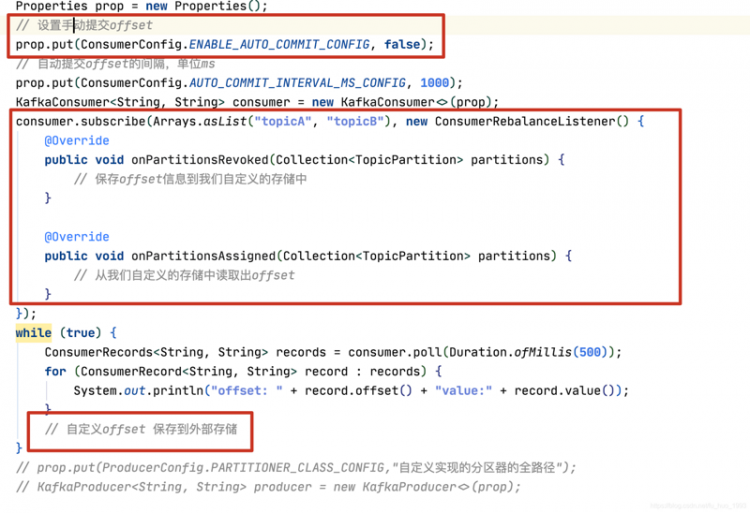
显示提交偏移量问题
- 总是在处理完事件后再提交偏移量
- 提交频率是性能和重复消息的权衡
- 确保对提交的偏移量心里有数:在轮训过程中有不好的一点就是,提交的偏移量是读取到的,而不是处理过的最新偏移量。
- 再均衡:一般要在消费者被撤销前提交偏移量
- 消费者有可能需要再重试:加入你现在有两条消息分别是30、31,31消息被成功处理,但是30确没有,这个时候你不能提交31。因为broker会认为你处理完了30、31
- 消费者可能需要维护状态
- 长时间处理:对于一些需要长时间处理的消息,不应该阻塞轮训太长时间,因为客户端需要发送心跳
- 仅一次传递:唯一性写入,幂等操作
以上是 kafka-可靠的数据传递 的全部内容, 来源链接: utcz.com/a/28181.html