【Java】kafka(五):实现Consumer消费消息
文章目录
- [一、前言]
- [二、消费者消费方式回顾]
- [三、消费者消费核心点分析]
- [四、手动提交offset实战]
- [4.1、引入maven依赖]
- [4.2、实现一个简单的手动提交offset消费者demo]
- [4.3、答疑解惑]
- [4.4、运行调试]
- [五、自动提交offset实战]
- [六、两种提交offset方式的对比]
- [七、总结]
一、前言
注意:我所使用的kafka版本为2.4.1,java版本为1.8,本文会对一些新老版本的改动地方加以说明。
二、消费者消费方式回顾
首先咱们回顾一下kafka消费消息的方式,kafka是使用pull(拉)模式从broker中读取数据的,然后就有两个疑问需要解答一下了。
疑问一:那为什么不采用push(推,填鸭式教学)的模式给消费者数据呢?
其实这种push方式在kafka架构里显然是不合理的,比如一个broker有多个消费者,它们的消费速率不同,一昧的push只会给消费者带来拒绝服务以及网络拥塞等风险。而kafka显然不可能去放弃速率低的消费者,因此kafka采用了pull的模式,可以根据消费者的消费能力以适当的速率消费broker里的消息。
疑问二:让消费者去主动pull数据就十全十美了吗?
其实让消费者去主动pull数据自然也是有缺点的。采用pull模式后,如果kafka没有数据,消费者可能会陷入循环中,一直返回空数据,这样超级频繁的返回空数据太消耗资源了。为了解决这个问题,Kafka消费者在消费数据时会传入一个时长参数timeout,如果当前没有数据可供消费,消费者会等待一段时间之后再返回,这段时长即为timeout。
注意:老版本还可以根据条数来判断,消费者等待一定的条数后返回,不过新版本给取消了。
三、消费者消费核心点分析
我们知道,数据在kafka中是可以持久化的,因此consumer消费数据的可靠性是不用担心的,也就是说不用担心数据的丢失问题,数据的消费是可控的。
疑问:那它是怎么控制的呢?
所以消费者消费数据的核心点在于offset的维护,而在撸代码时,offset的维护又分为手动提交和自动提交,它们是怎么玩的呢?又有哪些优缺点?都应用于哪些场景呢?现在就让我们一起来见真章!
四、手动提交offset实战
4.1、引入maven依赖
大家可以根据自己的kafka版本在mvn上找到适合自己的依赖,由于只是做简单的消息消费,所以只需要和上一篇文章的消息发送一样,引入kafka-clients依赖即可。我的kafka版本为2.4.1,所以我需要引入的依赖为:
<dependency><groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.1</version>
</dependency>
4.2、实现一个简单的手动提交offset消费者demo
又到了令人兴奋掉头发的撸代码时间了,老规矩,先介绍一下待会会用到的类:
KafkaConsumer:和前文的KafkaProducer遥相呼应,用来创建一个消费者对象进行数据消费;
ConsumerConfig:获取各种配置参数,如果不去配置,就是用默认的;
ConsuemrRecord:每条数据都要封装成一个ConsumerRecord对象才可以进行消费。
那下面就开始写了,这个简单的demo一共分为四步:
第一步:对Properties参数进行配置。
消费者的配置参数非常多,不建议都去记忆,可以记住几个常用的,对于不常用的咱们可以在用到的时候去ConsumerConfig源码或者kafka官网去查,还是比较方便的。kafka官网关于consumerconfigs网址:
http://kafka.apache.org/documentation/#consumerconfigs
在这个简单的demo里,我们需要用到下面这几个参数:
Properties参数
对应变量
功能
bootstrap.servers
BOOTSTRAP_SERVERS_CONFIG
指定kafka集群
key.deserializer
KEY_DESERIALIZER_CLASS_CONFIG
序列化key
value.deserializer
VALUE_DESERIALIZER_CLASS_CONFIG
序列化value
enable.auto.commit
ENABLE_AUTO_COMMIT_CONFIG
自动提交offset,默认为true
group.id
GROUP_ID_CONFIG
消费者组ID,只要group.id相同,就属于同一个消费者组
知道了这些变量的含义,代码就出来了:
Properties props = new Properties();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-1:9092");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "csdn");
解释:这里我们不允许自动提交,所以把
enable.auto.commit设置为false,然后给咱们的消费者定一个消费者组,叫做“csdn”。第二步:创建1个消费者。
和生产者类似的操作,这里使用传参的方式来创建消费者:
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);第三步:订阅topic主题。
现在消费者有了,你要告诉它去消费哪个或哪些topic才行,可以传入多个topic:
consumer.subscribe(Arrays.asList("testKafka"));第四步:循环消费并提交offset。
到这里,消费者有了,它也知道要去消费哪个topic了,那接下来写个循环,让它去消费就好了。这部分还有几个知识点,先看代码,然后我再解释:
while (true) {ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.println("topic = " + record.topic() + " offset = " + record.offset() + " value = " + record.value());
}
consumer.commitAsync();
//consumer.commitSync();
}
4.3、答疑解惑
看第四步的代码,里面包含了一些知识点,不了解的话可能会有一些疑问,下面对应解释如下:
疑问一:consumer.poll(100),这里的poll方法是干啥的?传入的100又是啥?有啥用呢?
疑问二:poll方法拿到的数据是一条还是一批?
疑问三:record都能拿到哪些信息呢?
:实现Consumer消费消息")
疑问四:我看你最后提交offset使用了commitAsync,或者commitSync,它们是啥?这两个方式有什么区别吗?
疑问五:代码的最后为什么不和生产者一样进行close呢?
这些疑惑都解决后,就可以运行代码调试了,下面列出全部代码:
import org.apache.kafka.clients.consumer.ConsumerConfig;import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.util.Arrays;
import java.util.Properties;
/**
* @author ropleData
* 博客地址:https://blog.csdn.net/qq_26803795
* 专注大数据领域,欢迎访问
*/
public class consumerDemo {
public static void main(String[] args) {
//1.配置参数
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-1:9092");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "1205");
//2.创建1个消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//3.订阅主题topic
consumer.subscribe(Arrays.asList("testKafka"));
//5.调用poll输出数据并提交offset
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.println("topic = " + record.topic() + " offset = " + record.offset() + " value = " + record.value());
}
consumer.commitAsync();
// consumer.commitSync();
}
}
}
4.4、运行调试
首先启动咱们的消费代码,然后在kafka某个broker下启动命令行调试,创建testKafka生产者,命令如下:
bin/kafka-console-producer.sh --broker-list 192.168.8.45:9092 --topic testKafka然后输入部分数据信息::实现Consumer消费消息")
这时候观察消费端::实现Consumer消费消息")
可以得出结论,咱们的简单demo已经完成了。
虽然是一个简单的demo,但是运行调试这里仍然能够玩出花来,可以很透测的理解3种分区分配策略,也可以对比出异步提交offset(commitAsync)和同步提交offset(commitSync)的区别。
关于三种分区分配策略,我的一篇文章已经举例讲的很清楚了,这里就不重复做对应的实验了,强烈建议对照着,多启动几个消费者实验一下数据的消费情况,来印证一下它们的特点,加深印象。
相关文章:深入分析Kafka(三):消费者消费方式、三种分区分配策略、offset维护
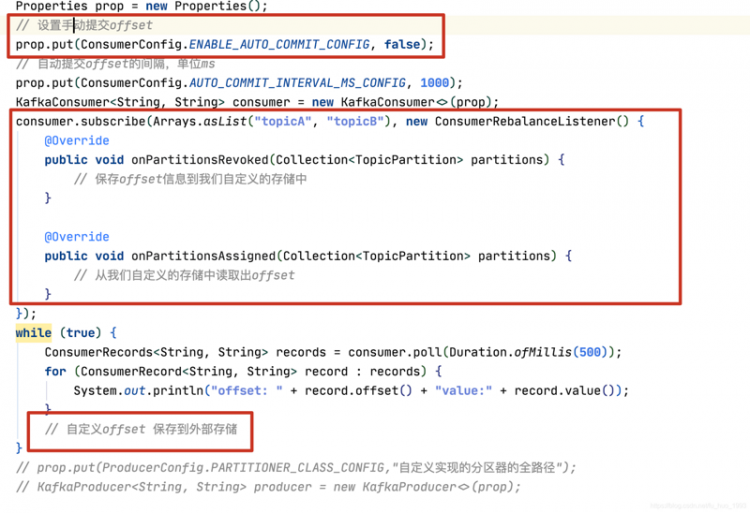
五、自动提交offset实战
其实手动提交和自动提交offset的代码差异很小,主要体现在:
配置参数,改一个,加一个。
修改:自动提交offset(enable.auto.commit)为true;
新增:自动提交时间间隔(auto.commit.interval.ms)单位ms,设置自动提交offset的时间间隔。
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");props.put("auto.commit.interval.ms", "1000");
输出数据后不在写提交offset代码。
//5.调用poll输出数据(不用自动提交offset)while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.println("topic = " + record.topic() + " offset = " + record.offset() + " value = " + record.value());
}
}
具体就不再演示了,后面会分析自动提交offset和手动提交offset的区别,完整代码如下:
import org.apache.kafka.clients.consumer.ConsumerConfig;import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.util.Arrays;
import java.util.Properties;
/**
* @author ropleData
* 博客地址:https://blog.csdn.net/qq_26803795
* 专注大数据领域,欢迎访问
*/
public class consumerAutoCommitDemo {
public static void main(String[] args) {
//1.配置参数
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-1:9092");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
props.put("auto.commit.interval.ms", "1000");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "1205");
//2.创建1个消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//3.订阅主题topic
consumer.subscribe(Arrays.asList("testKafka"));
//5.调用poll输出数据(不用自动提交offset)
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.println("topic = " + record.topic() + " offset = " + record.offset() + " value = " + record.value());
}
}
}
}
六、两种提交offset方式的对比
疑问:怎么控制的呢?
如果先消费数据后提交offset,这时候如果在提交offset的时候挂掉了,后来恢复后,会重复消费那条offset的数据,这样会数据重复,但也就是保证了数据的最少一次性(at least once);
如果先提交offset后消费数据,这时候如果在提交offset的时候挂掉了,后来恢复后,那部分offset虽然提交了,但其实是没有消费的,因此就照成了数据的丢失,但是不会重复,也就保证了数据的最多一次性(at most once)。
也就是说手动提交offset的时候,是通过控制提交offset和消费数据的顺序来完成的。
反观自动提交offset,由于是根据时间来自动提交的,因此是出了问题之后完全不可控的,因此在实际生产中不常使用。
七、总结
本文对kafka是怎么进行数据消费的,以及各个知识点进行了答疑解惑和代码的分析,应该可以弄明白kafka的消费的方式以及相关的难点,同时也解释了一些写手动提交offset代码时大家可能有疑惑的地方,并对比了两种手动提交offset的方式。我们还对手动提交offset还是自动提交offset分别进行了代码的编写以及两者在实际生产中的对比。
完整的代码已上传,感兴趣的可以下载查看。
github:https://github.com/ropleData/kafkaConsumerDemo
以上是 【Java】kafka(五):实现Consumer消费消息 的全部内容, 来源链接: utcz.com/a/92109.html