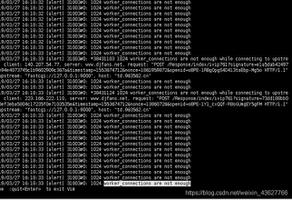
在用request库爬虫时,已经修改了headers,但status_code仍为418,请问这是什么情况?
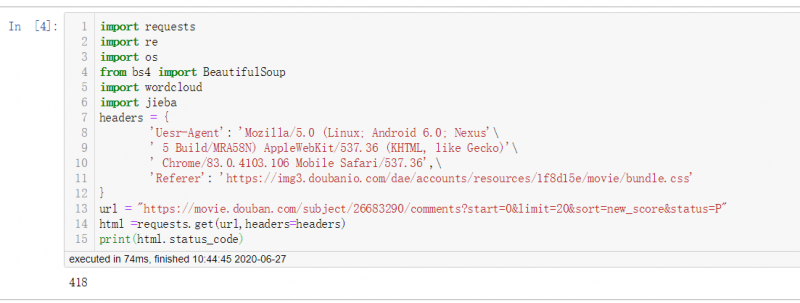
附上代码
import requests
import re
import os
from bs4 import BeautifulSoup
import wordcloud
import jieba
headers = {
'Uesr-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus'
' 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/83.0.4103.106 Mobile Safari/537.36',
'Referer': 'https://img3.doubanio.com/dae/accounts/resources/1f8d15e/movie/bundle.css'
}
url = "https://movie.douban.com/subject/26683290/comments?start=0&limit=20&sort=new_score&status=P"
html =requests.get(url,headers=headers)
print(html.status_code)
回答
试试这个
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74."
}
以上是 在用request库爬虫时,已经修改了headers,但status_code仍为418,请问这是什么情况? 的全部内容, 来源链接: utcz.com/a/28177.html