您好,怎么用python处理纯文本数据为二维数组?

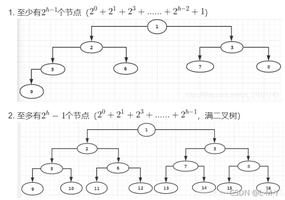
1. ad-表方向或加强语气原型:ad-(在拉丁语中出现在元音或辅音d、h、j、m和v 前)
aducir (拉丁语addūcere、英语adduce:ad-表方向+dūcere领导) tr.引证,举例(西语中只保留一个d)
变体:ad-和除d、h、j、m、v之外的辅音字母连用时发生逆行完全同化。其变体较多,请结合"逆行完全同化"的概念记忆。
abreviar (拉丁语abbreviāre、英语abbreviate :ad-→ab-+breviāre变短)tr.缩短(西语中只保留一个b)
afiliar (拉丁语affīliāre、英语 affiliate:ad-→af-+fil?us儿子+-āre) tr. 使参加(党派,团体等)
2. ab-分离、远离
原型:ab-
abducir (拉丁语abdūcere、英语abduce:ab-远离+duc-引导+-ir ) tr. 诱拐,绑架
abusar (拉丁语abusāre、英语abuse:ab-远离+us-使用+-ar ?远离正常的使用范围) intr. 乱用,滥用
变体:abs-用在以c或t为首字母的词根前
absceso (拉丁语abscessus、英语abscess:ab-表示远离→abs-;ces-走?从平面中走出?凸起; ) m. 脓肿,脓疡
abstraer (拉丁语abstrahere、英语abstract:ab-远离→abs-+tra-拉,抽+-er?使抽离现实) tr. 使抽象化
请问怎么用python处理如上数据成如下JSON数据?
{ "prefix":"ad",
"intro":"表方向或加强语气",
"prototype":{
"intro":"ad-(在拉丁语中出现在元音或辅音d、h、j、m和v 前)",
"list":[
{"word":"aducir","meaning":"(拉丁语addūcere、英语adduce:ad-表方向+dūcere领导) tr.引证,举例(西语中只保留一个d)"}
]
},
"variation":{
"intro":"ad-和除d、h、j、m、v之外的辅音字母连用时发生逆行完全同化。其变体较多,请结合"逆行完全同化"的概念记忆。",
"list":[
{"word":"abreviar","meaning":"(拉丁语abbreviāre、英语abbreviate :ad-→ab-+breviāre变短)tr.缩短(西语中只保留一个b)"},
{"word":"afiliar","meaning":"(拉丁语affīliāre、英语 affiliate:ad-→af-+fil?us儿子+-āre) tr. 使参加(党派,团体等)"}
]
}
}
{
如上。。。
}
回答:
import recontent = """..."""
def extract_case(text):
return [dict(zip(["word", "meaning"], i.split(maxsplit=1))) for i in text.split("\n") if i]
exp_parts = (
"\d+\.\s([a-z]+)-(.*?)\n"
"原型:(.*?)\n"
"((?:[a-z]+.*?\n)+)"
"变体:(.*?)\n"
"((?:[a-z]+.*?\n)+)"
)
parts = re.findall(exp_parts, content)
result = []
for part in parts:
prefix, intro, prototype, prototype_text, variation, variation_text = part
result.append(
{
"prefix": prefix,
"intro": intro,
"prototype": {"intro": prototype, "list": extract_case(prototype_text)},
"variation": {"intro": variation, "list": extract_case(variation_text)},
}
)
以上是 您好,怎么用python处理纯文本数据为二维数组? 的全部内容, 来源链接: utcz.com/a/158754.html